







一、HDFS概述
什么是分布式文件系统?
一、数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统 。
二、是一种允许文件通过网络在多台主机上分享的文件系统,可让多机器上的多用户分享文件和存储空间。
三、通透性。让实际上是通过网络来访问文件的动作,由程序与用户看来,就像是访问本地的磁盘一般。
四、容错。即使系统中有某些节点宕机,整体来说系统仍然可以持续运作而不会有数据损失【通过副本机制实现】。
分布式文件管理系统很多,hdfs只是其中一种,不合适小文件。
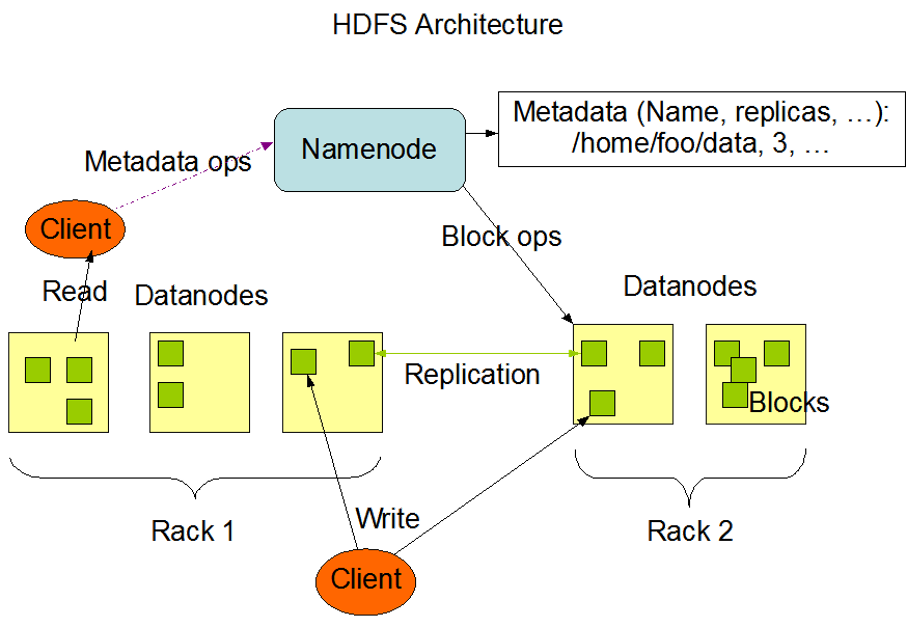
HDFS架构
主节点NameNode:
1.负责管理HDFS中元数据信息(数据存储的位置, 数据的Block块位置信息,权限相关等内容)
2.负责响应客户端的读写请求
3.管理DataNode
从节点DataNode:
1.存储实际的数据库
2.负责数据的读写请求
NameNode是整个文件系统的管理节点。它维护着整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表,接收用户的操作请求。
文件包括:
fsimage:元数据镜像文件。存储某一时段NameNode内存元数据信息。
edits:操作日志文件,namenode启动后一些新增元信息日志。
fstime:保存最近一次checkpoint 的时间
以上这些文件是保存在linux的文件系统中hdfs-site.xml的dfs.namenode.name.dir属性


BLock存储
DataNode为整个集群提供真实文件数据的存储服务,同时管理本节点中所有Block块
什么是Block块?
文件块(block):最基本的存储单位。对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小,顺序对文件进行划分并编号,划分好的每一个块称一个Block。2.0以后HDFS默认Block大小是128MB,可以在hdfs-site.xml中dfs.blocksize属性配置Block块
客户端从HDFS中读取数据时,会根据就近原则(根据网络拓扑结构) 选择最近的DataNode下载对应的BLock块
BLock块分布:
HDFS存储数据时,会根据机架感知,如果副本数为3,其中两份数据会被存放在一个节点中,另外一份数据会单独存放,为了防止单个机架出现故障,导致数据丢失。 为什么这样做?
当每个机架上存储一份数据,那么数据会分的过于分散,在后期做数据处理时,会将处理后的数据,进行做数据的汇总,这样机架和机架之间的网络通信会非常频繁,导致大量网络IO 降低执行效率
副本机制
什么是副本机制?
HDFS中通过副本方式来保证数据的安全性,并且同一数据的副本是存储在不同节点当中。HDFS默认副本数是三个。可以在hdfs-site.xml的dfs.replication属性中配置对应数量。
HDFS系统Web界面
- master:9000 表示是HDFS的API端口 JAVA
- Safemode is off. 表示当前的安全模式是出于关闭状态,当状态是ON时,整个HDFS不能对外提供任何服务
- DFS Remaining: 59.9 GB (82.4%) 表示当前HDFS可以存储的数据量大小为59.9GB
- Datanode 表示是数据节点,也是HDFS中的从节点名称为DataNode 该进程主要用来保存具体数据
- Browse the fileSystem 可以查看当前文件系统中的内容 / 作为其根路径
- logs可以查看HDFS的执行日志
HDFS使用
1.上传文件 hdfs dfs -put README.txt /
2.文件的元数据信息 -> 对数据的描述(权限,所属者,创建及其修改时间,数据存储的位置)
3.权限 -rw-r–r– 第一位 文件或目录 第一组rw-当前所属者权限 第二组是当前所属组权限 第三组是其他用户权限
4.Replication(副本机制) 用来保证数据的安全,如果设置为1 表示当前该数据在HDFS中只有一份
5.Block Size 表示块大小 128 MB Block块切分逻辑
HDFS API使用
相关代码练习可以到我的gitee仓库查看
https://gitee.com/zhao-shengdi/bigdata24-project.git
git@gitee.com:zhao-shengdi/bigdata24-project.git















 7632
7632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









