









文章目录
近年来,Transformer架构在自然语言处理(NLP)领域掀起了一场革命。从2017年提出的Transformer,到基于此架构的BERT和GPT模型,NLP模型的性能和应用范围被大幅度扩展。这篇文章将从Transformer的基础出发,详细介绍其核心原理,并深入探讨BERT和GPT的特点、实现及其应用场景。
一、Transformer架构基础
Transformer架构由Vaswani等人在2017年的论文《Attention is All You Need》中首次提出,其核心创新是完全基于注意力机制(Attention)来处理序列数据,从而替代传统的循环神经网络(RNN)和卷积神经网络(CNN)。
1.1 Transformer的主要组成
Transformer模型由两个部分组成:
- 编码器(Encoder):将输入序列编码为一组高维表示。
- 解码器(Decoder):根据编码器的输出生成目标序列。
编码器
编码器由多个堆叠的子层组成,每个子层包括:
- 多头自注意力机制(Multi-Head Self-Attention):捕捉输入序列中词与词之间的依赖关系。
- 前馈神经网络(Feed-Forward Neural Network, FFN):对注意力机制的输出进行非线性变换。
解码器
解码器的结构与编码器类似,但增加了一个额外的注意力模块:
- 编码器-解码器注意力(Encoder-Decoder Attention):利用编码器的输出,帮助解码器生成与输入相关的目标序列。
1.2 注意力机制详解
Transformer的核心在于注意力机制。给定查询(Query)、键(Key)和值(Value)三组向量,注意力机制计算一个加权平均值,其中权重由查询与键的相似度决定。常用的公式如下:
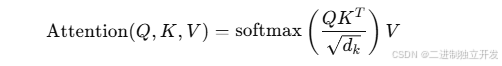
其中:
- ( Q ):查询矩阵
- ( K ):键矩阵
- ( V ):值矩阵
- ( d_k ):键向量的维度,用于缩放避免数值不稳定。
二、BERT模型:从预训练到微调
BERT(Bidirectional Encoder Representations from Transformers)由Google在2018年提出,是一个双向编码的Transformer模型。BERT的主要目标是通过深度预训练捕捉语言的上下文语义表示。
2.1 BERT的核心创新
BERT的关键特点包括:
- 双向编码:同时考虑输入序列的左右上下文。
- 掩码语言模型(Masked Language Model, MLM):随机掩盖部分输入单词,让模型预测这些单词。
- 下一句预测(Next Sentence Prediction, NSP):通过判断两句话是否连续,帮助模型理解句子间的关系。
2.2 BERT的实现
以下是一个简单的BERT加载和使用示例,基于Hugging Face Transformers库:
from transformers import BertTokenizer, BertModel
# 加载BERT模型和分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# 输入文本
text = "Transformers are powerful tools in NLP."
inputs = tokenizer(text, return_tensors='pt')
# 通过模型获取输出
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
print(last_hidden_states.shape)
BERT的预训练任务使其能够在大量无监督数据上学习语言表示,经过微调后可以广泛应用于分类、问答等任务。
2.3 BERT的应用
BERT的应用场景包括但不限于:
- 文本分类(情感分析、垃圾邮件检测)
- 问答系统(SQuAD等数据集)
- 句子相似度计算
- 命名实体识别(NER)
三、GPT模型:生成式的突破
GPT(Generative Pre-trained Transformer)是OpenAI提出的一系列生成式语言模型,GPT的主要目标是通过无监督学习生成连贯、上下文相关的文本。
3.1 GPT的特点
GPT与BERT相比,具有以下不同之处:
- 单向编码:GPT只关注从左到右的上下文,适合生成任务。
- 语言建模任务:通过预测下一个单词进行训练。
- 无监督学习:通过大规模文本数据学习语义和语言结构。
3.2 GPT的实现
以下是一个简单的GPT实现示例,基于Hugging Face Transformers库:
from transformers import GPT2Tokenizer, GPT2LMHeadModel
# 加载GPT模型和分词器
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
# 输入文本
prompt = "The future of AI is"
inputs = tokenizer(prompt, return_tensors='pt')
# 生成文本
outputs = model.generate(inputs.input_ids, max_length=50, num_return_sequences=1)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_text)
GPT在生成任务中表现卓越,例如:
- 文本续写
- 对话生成
- 文案撰写
3.3 GPT的演进
GPT经历了多次迭代:
- GPT-2:更大的模型规模,展示了文本生成能力。
- GPT-3:显著提升模型规模和效果,支持零样本和少样本学习。
- GPT-4(尚未公开细节):进一步扩展生成能力,支持多模态输入。
四、BERT与GPT的对比
| 特性 | BERT | GPT |
|---|---|---|
| 任务类型 | 表征学习(上下文语义) | 文本生成 |
| 编码方向 | 双向 | 单向 |
| 预训练任务 | MLM 和 NSP | 语言建模 |
| 应用场景 | 分类、问答、NER等 | 文本生成、对话系统 |
| 模型架构 | Transformer 编码器 | Transformer 解码器 |
尽管两者架构有所不同,但都以Transformer为核心,推动了NLP的飞速发展。
五、如何选择BERT或GPT?
- 选择BERT:如果你的任务是理解文本(例如情感分析、问答系统),BERT是更好的选择。
- 选择GPT:如果你的任务是生成文本(例如写作助手、聊天机器人),GPT更适合。
六、总结与未来展望
本文从Transformer的基础出发,详细介绍了BERT和GPT模型的架构、实现和应用场景。Transformer架构凭借其强大的注意力机制,已经成为深度学习领域的关键技术之一。
在未来,Transformer将进一步融合多模态数据(如文本、图像、音频),并在更大的模型规模和更高效的训练方法推动下,继续改变我们与AI互动的方式。
你更喜欢使用BERT还是GPT?有哪些应用场景让你感到兴奋?欢迎在评论区分享你的观点或提问,我们共同探讨NLP的未来!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











