









ES是一个分布式可扩展的东西,这个分布式我们可以从redis的cluster获得理解。和所有的分布式应用一样,ES也拥有一些概念诸如节点,集群,分片。本文就一一来看一下这些概念,对于后面的搭建集群有一个认知。
ES是具有高可用性的,也就是当你某些节点突然宕机了,是可以继续对外提供服务的。
ES基于其高可用性,是具有数据可用性的。当部分节点的数据丢失,整体不会丢失数据。
ES是具有可扩展性的,当你的请求量或者数据量增长到一定程度,我们可以水平扩展节点,将数据分布到所有的节点上面。
下面我们一一来理解介绍一下这些概念。
一、节点
1、简介
节点是一个ES的实例,也就是说当你在服务器启动一个es实例的时候,他就是一个节点。
- 其本质是一个JAVA进程,你可以用JPS查到。
- 一个机器上可以运行多个ES进程,但是生产环境建议一台机器运行一个,因为保证可用性,别一个机器宕机了,你所有的服务全部没了。
- 每一个几点都是由名称的,你可以在配置文件中配置指定,也可以在启动命令行中指定,通过-E node.name = 名称。
- 每一个节点启动之后,会分配一个UID,保存在data目录下面。
2、主节点
每个节点启动之后,都是自己的Master eligible节点。
- 你也可以在配置文件中设置node.master:false来禁止成为主节点。
Master eligible节点可以参加选主流程,进而成为Master主节点。也就是说一个节点起来之后是拥有成为主节点的资格。
当第一个节点启动的时候,他会将自己选举成为Master节点。
每个节点上都保存了集群的状态,只有Master节点才能修改集群的状态信息。 - 所谓的集群状态信息,也叫cluster state,维护了一个集群中所必要的信息。
-
包括所有的节点信息。 -
所有的索引和其相关的Mapping 和Setting信息。 -
分片的路由信息,数据被分片之后分到哪里了。
-
- 之所以要主节点才能修改集群的状态信息,是为了避免任意节点都能修改信息会导致数据的不一致性。怕乱了。
3、Data Node && Coordinating Node
3.1、Data Node
顾名思义,数据节点就是可以保存数据的节点。负责保存分片的数据,当集群扩展的时候其实就是扩展他。
3.2、Coordinating Node
协调节点,负责接收客户端的请求,然后将请求分发到合适的节点分片,最后把各个分片查到的数据结果汇集到一起。
每个节点默认都是Coordinating Node,都具有他的职责。
3.3、Hot & Warm Node
冷热节点,es提供了冷热数据分开存储的机制。实现hot & warm架构,Hot数据就是冷数据,一些不常用的数据,我们可以部署在一些低配置的机器上,实现冷热分区的机制。降低部署的成本。
3.4、Machine Learning Node
负责跑机器学习的job的节点,自动发现ES数据的异常,发出一些警报。
3.5、Tribe Node
这个东西慢慢被淘汰了,在5.3之后开始使用Cross Cluster Search节点,Tribe Node连接到不同的ES集群,并且支持将这些集群当成一个单独的集群处理。
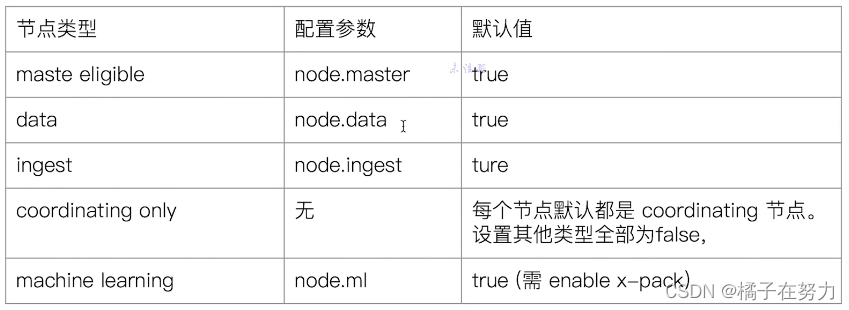
4、配置节点类型
1、开发环境中一个节点可以承担多个角色。
2、生产环境中,应该设置单一的角色节点。一来可以性能好,节点负责的东西不多就性能好。二来职责单一,可以很快确定问题。管理也方便,可以为不同职责的节点配置不同的硬件。这里不要纠结这种,后面我们配置集群的时候来理解这些问题。
二、分片
分片分为主分片和副本。
1、主分片
主分片用于解决数据水平扩展的问题,通过主分片,可以将数据分布到集群内的所有节点上。
一个分片就是一个运行的Lucene实例。
主分片数量在索引创建的时候指定,后续不许修改,除非Reindex。
我们从以上信息可以提取一些点。
1、分片是在索引创建的时候指定的,所以分片的维度是在索引上,不同的索引有不同的分片数。
2、一个索引会分散数据到各个分片上,每个分片都是一个Lucene实例。
3、Reindex会导致主分片数量变化。
2、副本
副本是解决数据高可用问题的关键点。副本是属于主分片的,每个主分片下面多个副本。
1、副本是主分片的拷贝。
2、副本分片数是可以动态调整的。
3、增加副本数,可以在一定程度上提高服务的可用性,还能提高读取的吞吐。可见读取数据可以走副本。为啥说一定程度呢,因为不可能无限制增加的,你副本要同步主分片数据也需要成本,只能是一定限度。
3、分片,副本,和节点的关系
场景,一个集群testCluster里面有三个节点,此时我们去创建一个testIndex索引。其分片情况如下。
PUT /testIndex
{
"settings":{ # 在settings里面设置分片,副本等信息
"number_of_shards":3 # 这个索引指定三个主分片
"number_of_replicas":1 # 每个主分片下设置一个副本
}
}
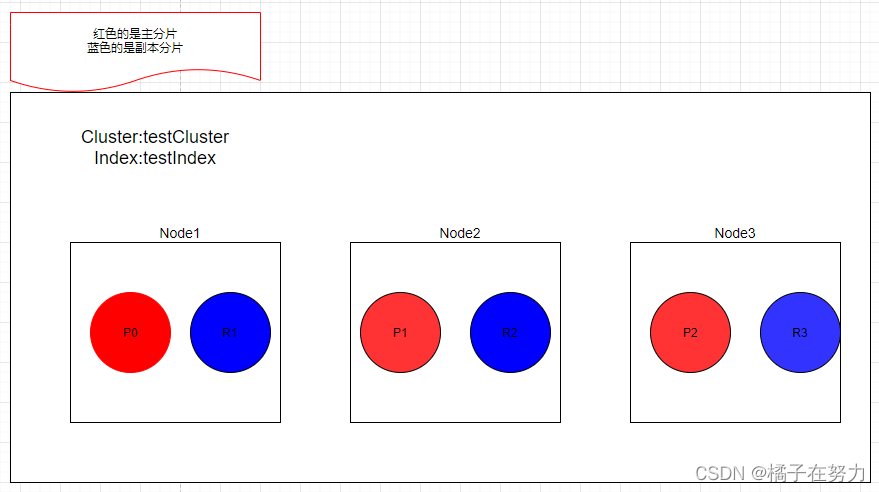
我们看到此时三个节点下的集群,三个主分片就分布到不同的节点上。每个主分片的副本分片分布到和主分片不同的节点上。避免一个宕机了把主从都丢失了。
问题:
此时增加一个节点,或者增大主分片数对系统有何影响。
4、分片的设定
对于生产中分片的设定,需要提前做好容量规划。
4.1、分片数量过小
导致后续无法通过增加节点来实现水平扩展。因为你分片就那么多,你增加节点他没分片去分布啊。
单个分片的数量会很多,导致数据重新分配耗时。查询也慢。
4.2、分片数量设置过大
7.0开始默认主分片从原来的5变成了1.解决了over-sharding的问题。
分片数过于多也影响相关性打分。这个后面学打分的时候看一下。
单个节点过多分片也会导致资源浪费,影响节点性能,此外因为分布集中要是一个节点挂了,可能还有可用性问题。
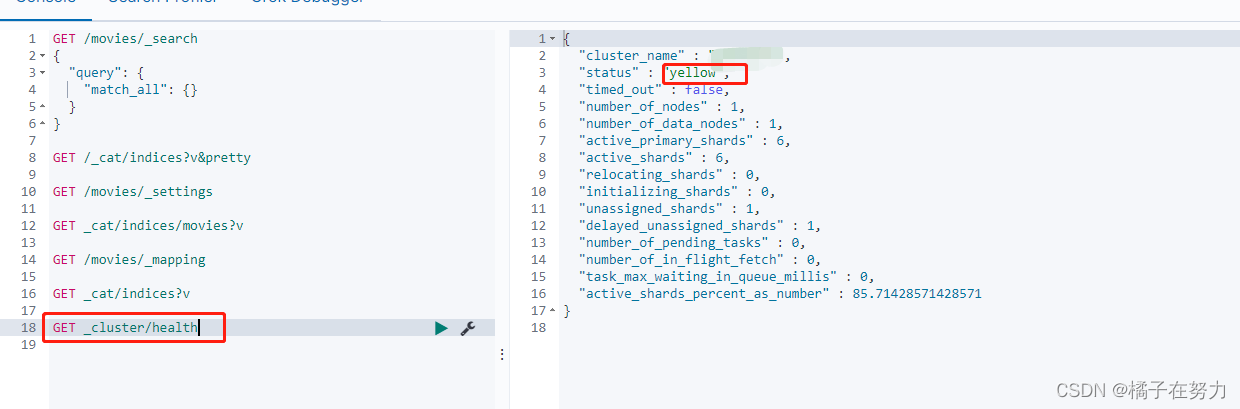
可以使用GET _cluster/health来查看集群的健康程度。
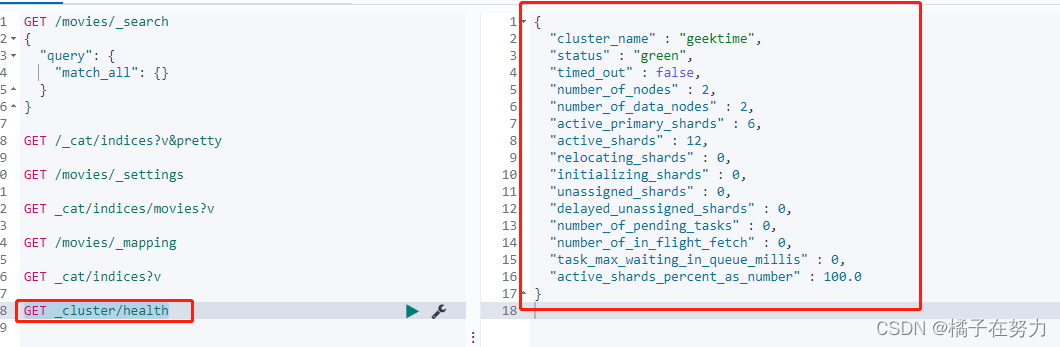
{
"cluster_name" : "test",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 2,
"number_of_data_nodes" : 2,
"active_primary_shards" : 6,
"active_shards" : 12,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
显示出以上的信息,其中status有三个值。
- green:集群中的主分片和副本都正常分配。
- yellow:主分片全部正常分配,有副分片未能正常分配。
- red:有主分片未能正常分配。
例如,当服务器的磁盘容量超过百分之85,此时你去创建索引,就会分配失败,需要人工介入干预。
三、cerebro可视化查看集群
1、查看信息
连接到9000端口查看集群信息。
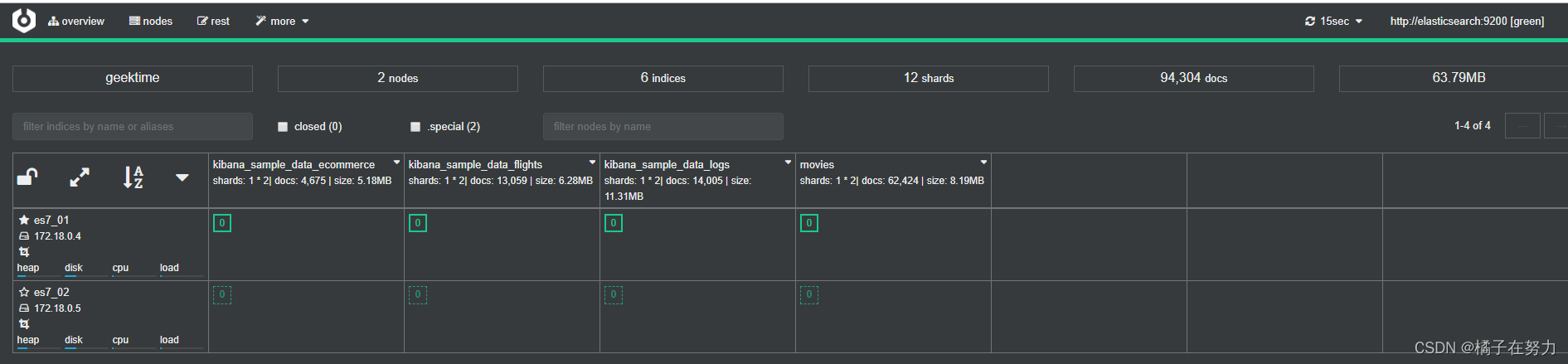
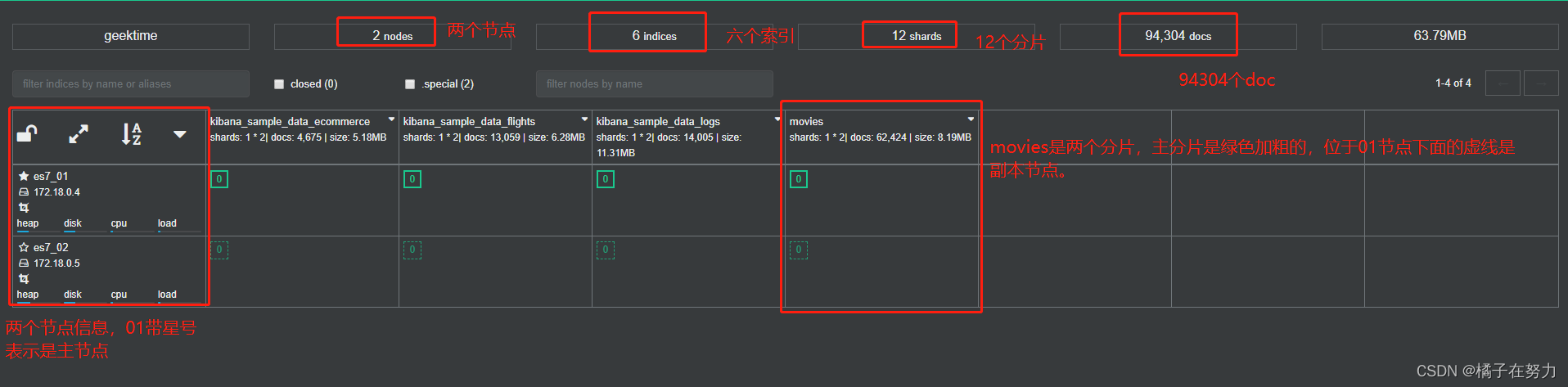
索引现在的主分片和副本分片默认都是1。
我上面说错,每个节点都是带星号的,表示都是Master eligible节点。但是加粗的星号表示是master节点,他们都有被选能力,但是加粗的表示他成为了master节点,一般先启动的就是master。
2、手动移除节点
为了验证我们上面说的那个status的绿色,红色,黄色,我们现在看到的都是正常的,绿色。
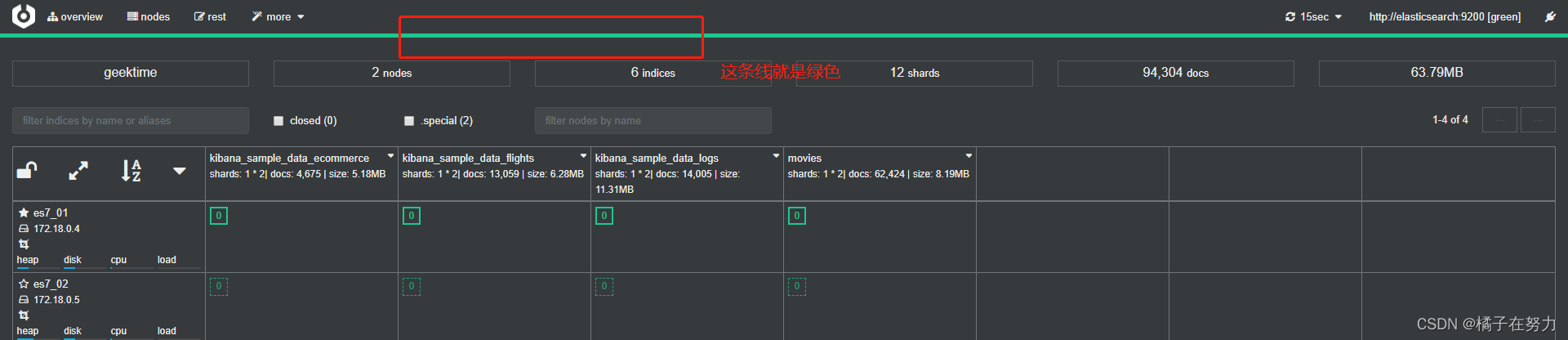
现在我们手动停止其中的一个容器。我们先查看一下当前docker有哪些容器。docker ps

我们停掉es_702那个,我们上面看到702是各个索引的副本分片所在的地方,所以停掉之后应该就变成黄色。红色的自己去试试。socker stop

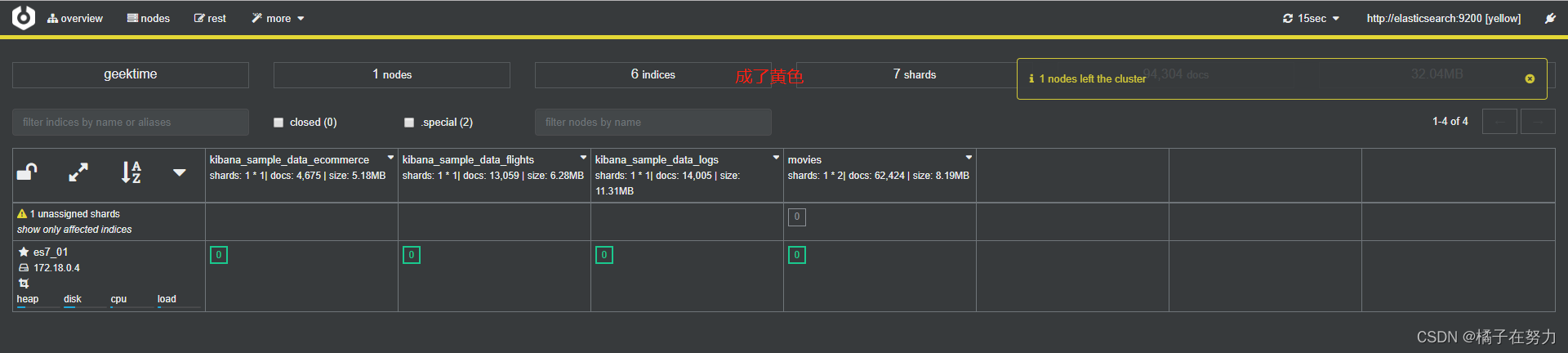
此时再去kibana看下信息:发现一切都如预期。
四、总结
我们需要知道这些概念,因为实际生产都是集群模式,我们需要做到心中有数,有的放矢。后续再真正使用集群的时候才能知道自己在干吗。至于具体的设计,搭建,配置,调优需要在后续不断的完善知识完成理论和实践体系。
附操作:
#查看索引相关信息
GET kibana_sample_data_ecommerce
#查看索引的文档总数
GET kibana_sample_data_ecommerce/_count
#查看前10条文档,了解文档格式
POST kibana_sample_data_ecommerce/_search
{
}
#_cat indices API
#查看indices
GET /_cat/indices/kibana*?v&s=index
#查看状态为绿的索引
GET /_cat/indices?v&health=green
#按照文档个数排序
GET /_cat/indices?v&s=docs.count:desc
#查看具体的字段
GET /_cat/indices/kibana*?pri&v&h=health,index,pri,rep,docs.count,mt
#How much memory is used per index?
GET /_cat/indices?v&h=i,tm&s=tm:desc















 743
743











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









