







一、简介
我们在前面写了这么一个代码:
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from pydantic import BaseModel, Field, model_validator
from typing import List
# 1、构建第一个chain的模板,根据这个模板让大模型为我们输出一个他作为cityMajor的专家的一个当前经济环境的结果。
getRespPromptTemplate = ChatPromptTemplate([
("system", "假如你是一个研究{cityMajor}的专家。"),
("human", "介绍一下当前的经济环境,不要思考过程。"),
])
# 2、构建第一个chain,先获取模板,发给llm,最后结果通过一个字符串的parser解析输出为字符串
getRespChain = getRespPromptTemplate | llm | StrOutputParser()
# 3、构建第二个chain的模板,这个模板有一个参数,就是上一个chain的输出作为输入,分析其中的内容,我们只要结果的标题小点的总结
getHeadingPromptTemplate = ChatPromptTemplate.from_template("""
分析{resp},并且仅仅获取其中的每一点的标题,注意只获取每一点的标题,不要后面的描述,我只要标题点,并且不要思考过程
""")
"""
4、构建第二个chain,第二个chain首先我们要把第一个chain的结果当成第一步传递给getHeadingPromptTemplate
因为getHeadingPromptTemplate需要第一个的结果去填充{resp},所以我们构建一个{}的map结构,得到第一个chain的输出给getHeadingPromptTemplate
getHeadingPromptTemplate填充完了发给llm
最后以字符串输出解析器解析为字符串。
"""
getHeadingChain = {"resp":getRespChain} | getHeadingPromptTemplate | llm | StrOutputParser()
# 执行最后的chain,然后把第一个chain的参数可以传进去,此时他们是一个chain了,可以这么传
resp = getHeadingChain.invoke({"cityMajor":"山西经济"} )
print(resp)
我们串行执行了两个chain,把第一个输出传给第二个作为输入,得到结果。
但是这里有一点不太好,就是我第一个输出有时候可能很长,有时候可能很短。有时候token的长度不同选择不同的模型可能会更好。所以我们需要根据第一个的输出长度来判断下一个处理的模型是啥这个就有必要实现。
这个需求的实现我们可以通过RunnableLambda
二、RunnableLambda
1、前置代码
自然是要准备先读取配置文件方便我们集成langsmith监控,以及声明模型
from dotenv import load_dotenv
import os
from langchain_ollama import ChatOllama
# 这一步就把环境文件加载进来系统了
load = load_dotenv("./.env")
# 我们用os来读取加载的内容,输出测试一下
print(os.getenv("LANGSMITH_API_KEY"))
# 声明llm
llm = ChatOllama(
base_url = "http://127.0.0.1:11434",
model = "deepseek-r1:8b",
temperature = 0.5,
num_predict = 10000,
max_tokens = 250
)
llmllama32 = ChatOllama(
base_url = "http://127.0.0.1:11434",
model = "llama3.2:latest",
temperature = 0.5,
num_predict = 10000,
max_tokens = 250
)
2、RunnableLambda
我们来看一下他的文档介绍。
RunnableLambda 将 python 可调用对象转换为 Runnable。
将可调用对象包装在 RunnableLambda 中使可调用对象可在同步或异步上下文中使用。
RunnableLambda 可以像任何其他 Runnable 一样组合,并提供与 LangChain 跟踪的无缝集成。
我们可以看到他可以把调用对象转为Runnable。那自然我们就可以把一个函数转为Runnable。
这个函数里面我们可以执行一些判断。说干就干。
我们来重新写一些代码。
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableLambda
# 模型选择器,当要处理的内容长度超过100使用deepseek大模型来处理,反之使用llama大模型
def choose_llm(resp):
resp_text = str(resp)
if len(resp_text) > 100:
return llm
else:
return llmllama32
# 通过RunnableLambda把一个函数转为一个Runnable
llm_selector_runnable = RunnableLambda(choose_llm)
# 1、构建第一个chain的模板,根据这个模板让大模型为我们输出一个他作为cityMajor的专家的一个当前经济环境的结果。
getRespPromptTemplate = ChatPromptTemplate([
("system", "假如你是一个研究{cityMajor}的专家。"),
("human", "介绍一下当前的经济环境,不要思考过程。"),
])
# 2、构建第一个chain,先获取模板,发给llm,最后结果通过一个字符串的parser解析输出为字符串
getRespChain = getRespPromptTemplate | llm | StrOutputParser()
# 3、构建第二个chain的模板,这个模板有一个参数,就是上一个chain的输出作为输入,分析其中的内容,我们只要结果的标题小点的总结
getHeadingPromptTemplate = ChatPromptTemplate.from_template("""
分析{resp},并且仅仅获取其中的每一点的标题,注意只获取每一点的标题,不要后面的描述,我只要标题点,并且不要思考过程
""")
"""
4、构建第二个chain,第二个chain首先我们要把第一个chain的结果当成第一步传递给getHeadingPromptTemplate
因为getHeadingPromptTemplate需要第一个的结果去填充{resp},所以我们构建一个{}的map结构,得到第一个chain的输出给getHeadingPromptTemplate,这一步的结果我们传递给下一个Runnable,也就是我们的llm选择器,他就会把输出传给选择器中的调用函数进行判断,
根据长度返回对应的llm,最后以字符串输出解析器解析为字符串。
"""
getHeadingChain = {"resp":getRespChain} | getHeadingPromptTemplate | llm_selector_runnable | StrOutputParser()
# 执行最后的chain,然后把第一个chain的参数可以传进去,此时他们是一个chain了,可以这么传
resp = getHeadingChain.invoke({"cityMajor":"山西经济"} )
print(resp)
执行之后我们得到结果然后去langsmith看一下监控。
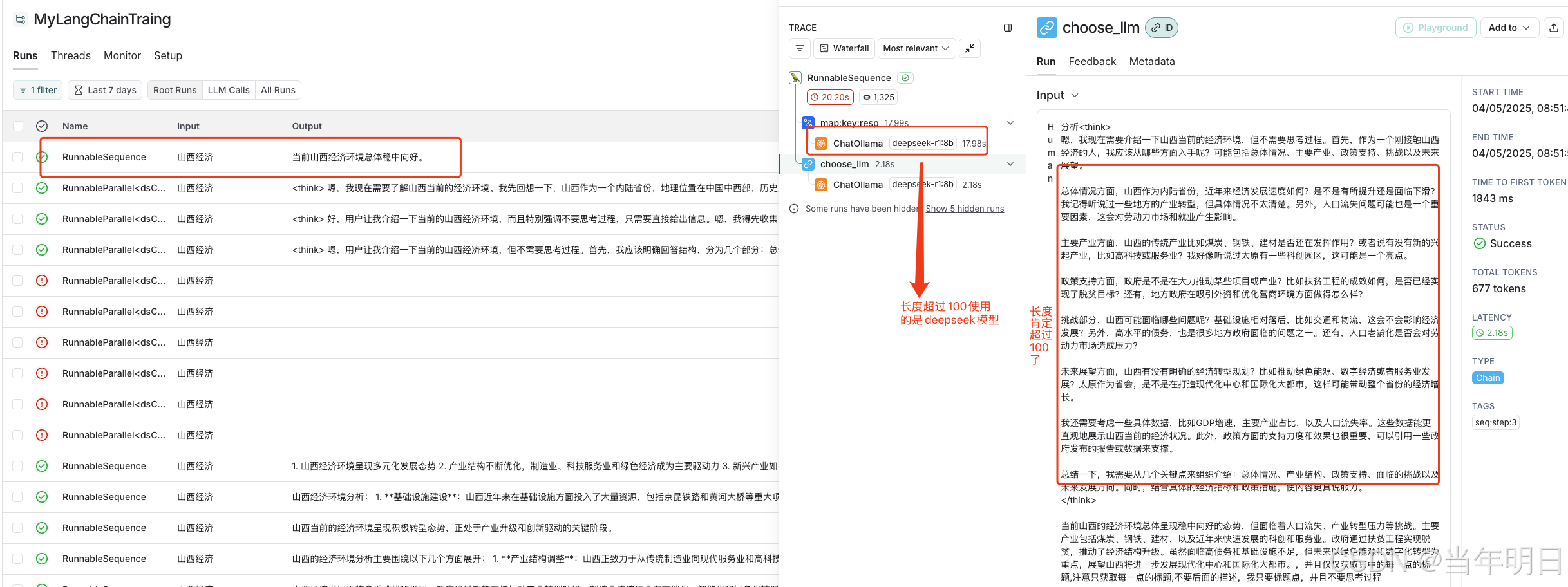
没毛病,我们再反向验证一下,我们只需要修改llm选择器函数中的判断即可。我们这次没超过100用deepseek,反之用llama。
# 模型选择器,当要处理的内容长度超过100使用llama大模型来处理,反之使用deepseek大模型
def choose_llm(resp):
resp_text = str(resp)
if len(resp_text) < 100:
return llm
else:
return llmllama32

我们看到选择生效了。ok,这就是Lambda Runnable的主要用法,其余还有一些异步操作,可以对着文档直接操作即可。
3、chain
我们上面是通过RunnableLambda把一段函数转化成Runnable然后添加到调用链中的。实际上还有一种注解的方式就能实现这个操作,我们简单使用一下。
他的文档位于chain。
他不需要使用RunnableLambda,而是直接在函数上添加@chain注解就能把这个函数转为Runnable。
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import chain
# 模型选择器,当要处理的内容长度超过100使用deepseek大模型来处理,反之使用llama大模型
@chain # 通过@chain把一个函数转为一个Runnable
def choose_llm(resp):
resp_text = str(resp)
if len(resp_text) > 100:
return llm
else:
return llmllama32
# 1、构建第一个chain的模板,根据这个模板让大模型为我们输出一个他作为cityMajor的专家的一个当前经济环境的结果。
getRespPromptTemplate = ChatPromptTemplate([
("system", "假如你是一个研究{cityMajor}的专家。"),
("human", "介绍一下当前的经济环境,不要思考过程。"),
])
# 2、构建第一个chain,先获取模板,发给llm,最后结果通过一个字符串的parser解析输出为字符串
getRespChain = getRespPromptTemplate | llm | StrOutputParser()
# 3、构建第二个chain的模板,这个模板有一个参数,就是上一个chain的输出作为输入,分析其中的内容,我们只要结果的标题小点的总结
getHeadingPromptTemplate = ChatPromptTemplate.from_template("""
分析{resp},并且仅仅获取其中的每一点的标题,注意只获取每一点的标题,不要后面的描述,我只要标题点,并且不要思考过程
""")
"""
4、构建第二个chain,第二个chain首先我们要把第一个chain的结果当成第一步传递给getHeadingPromptTemplate
因为getHeadingPromptTemplate需要第一个的结果去填充{resp},所以我们构建一个{}的map结构,得到第一个chain的输出给getHeadingPromptTemplate
getHeadingPromptTemplate填充完了发给llm
最后以字符串输出解析器解析为字符串。
"""
getHeadingChain = {"resp":getRespChain} | getHeadingPromptTemplate | choose_llm | StrOutputParser()
# 执行最后的chain,然后把第一个chain的参数可以传进去,此时他们是一个chain了,可以这么传
resp = getHeadingChain.invoke({"cityMajor":"山西经济"} )
print(resp)
输出也是正常的。

所以至此我们基本完成了关于Runnable的使用,接下来我们就开始操作一些模型的上下文问题,让他能够成为一个可以有记忆的对话机器。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









