







一、简介
我们之前完成了一个简易的聊天机器人,但是还留下了一些问题没有解决,比如如何开启新的会话。如何切换session_id,如何把对话做成流式的输出。这些我们就会在今天来完成。
二、关于新的会话和session_id
from dotenv import load_dotenv
from langchain_ollama import ChatOllama
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import ElasticsearchChatMessageHistory
from streamlit import streamlit as st
# load env file
load = load_dotenv("./.env")
# 无密码的elasticsearch配置
es_url = "http://localhost:9200"
# 存储的索引,我们不用预先创建索引,因为说实话我也不知道字段,langchain会创建,并且自动映射字段
index_name = "chat_history"
# init llm
llm = ChatOllama(
base_url = "http://127.0.0.1:11434",
model = "huihui_ai/deepseek-r1-abliterated:14b",
temperature = 0.5,
num_predict = 10000
)
# 构建ElasticsearchChatMessageHistory
def get_session_history(session_id: str) :
return ElasticsearchChatMessageHistory(
index=index_name,
session_id=session_id,
es_url=es_url,
ensure_ascii=False
)
session_id = "levi"
st.title("你好,这里是橘子GPT,我是小橘")
st.write("请把您的问题输入,小橘会认真回答的哦。")
# 添加一个输入框,用户自己输入来替代默认的
session_id = st.text_input("请输入一个session_id,否则我们将使用默认值levi",session_id)
# 添加一个按钮,触发按钮开启新的会话,并且删除上下文记录
isClickButton:bool = st.button("点击按钮,开启新的对话")
# query input
user_prompt = st.chat_input("我是小橘,请输入你的问题吧")
if isClickButton:
# 清除es中存储的上下文记录,这个是物理删除delete_by_query
get_session_history(session_id).clear()
# 清除当前会话的上下文
st.session_state.chat_history = []
# 如果没有就创建,不要每次都建立新的
if 'chat_history' not in st.session_state:
st.session_state.chat_history = []
# 遍历里面的内容,取出来存进去的每一组role 和 content
for message in st.session_state.chat_history :
# 通过取出来的信息,构建st.chat_message,不同的角色会有不同的ui样式,这里就是做这个的
with st.chat_message(message['role']):
# 把内容展示出来
st.markdown(message['content'])
template = ChatPromptTemplate.from_messages([
('human',"{prompt}"),
('placeholder',"{history}")
])
chain = template | llm | StrOutputParser()
chain_with_history = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key="prompt",
history_messages_key="history",
)
if user_prompt :
response = chain_with_history.invoke(
{"prompt": user_prompt},
config={"configurable": {"session_id": session_id}})
# 保存历史,上面用来遍历显示,避免后面覆盖前面的显示
st.session_state.chat_history.append({'role':'user','content':user_prompt})
with st.chat_message('user'):
st.markdown(user_prompt)
# 保存历史,上面用来遍历显示,避免后面覆盖前面的显示
st.session_state.chat_history.append({'role':'assistant','content':response})
with st.chat_message('assistant'):
st.markdown(response)
这样就实现了需求了,可以直接跑一下看看。
三、关于流式对话
流式对话其实说白了就是回复的时候一个字一个字的显示,表现为流的样子,而不是一次性返回一大堆。
from dotenv import load_dotenv
from langchain_ollama import ChatOllama
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import ElasticsearchChatMessageHistory
from streamlit import streamlit as st
# load env file
load = load_dotenv("./.env")
# 无密码的elasticsearch配置
es_url = "http://localhost:9200"
# 存储的索引,我们不用预先创建索引,因为说实话我也不知道字段,langchain会创建,并且自动映射字段
index_name = "chat_history"
# streamlit code
session_id = "levi"
# init llm
llm = ChatOllama(
base_url = "http://127.0.0.1:11434",
model = "huihui_ai/deepseek-r1-abliterated:14b",
temperature = 0.5,
num_predict = 10000
)
# 构建ElasticsearchChatMessageHistory
def get_session_history(session_id: str) :
return ElasticsearchChatMessageHistory(
index=index_name,
session_id=session_id,
es_url=es_url,
ensure_ascii=False
)
st.title("你好,这里是橘子GPT,我是小橘")
st.write("请把您的问题输入,小橘会认真回答的哦。")
# 设置一个输入框,用户输入的内容来替代默认的session_id。
session_id = st.text_input("请输入一个session_id,否则我们将使用默认值levi",session_id)
# 添加一个按钮,点击按钮的时候清空历史会话
isClickButton:bool = st.button("点击按钮,开启新的对话")
if isClickButton:
# 注意这一行会去调用es客户端delete_by_query物理删除es中的上下文数据,最好自己定制,不要直接用
get_session_history(session_id).clear()
# 清除当前窗口的上下文记录
st.session_state.chat_history = []
# query input
user_prompt = st.chat_input("我是小橘,请输入你的问题吧")
# 构建langchain执行
def invoke_history_by_stream(chain,prompt,session_id):
chain_with_history = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key = prompt,
history_messages_key="history",
)
# 以stream流的方式执行
responseStream = chain_with_history.stream({"prompt": prompt},config={"configurable": {"session_id": session_id}})
# 遍历返回,逐个回复
for response in responseStream:
yield response
# 如果没有就创建,不要每次都建立新的
if 'chat_history' not in st.session_state:
st.session_state.chat_history = []
# 遍历里面的内容,取出来存进去的每一组role 和 content
for message in st.session_state.chat_history :
# 通过取出来的信息,构建st.chat_message,不同的角色会有不同的ui样式,这里就是做这个的
with st.chat_message(message['role']):
# 把内容展示出来
st.markdown(message['content'])
template = ChatPromptTemplate.from_messages([
('human',"{prompt}"),
('placeholder',"{history}")
])
chain = template | llm | StrOutputParser()
# 如果感知到输入
if user_prompt :
# 保存历史,上面用来遍历显示,避免后面覆盖前面的显示
st.session_state.chat_history.append({'role':'user','content':user_prompt})
with st.chat_message('user'):
st.markdown(user_prompt)
with st.chat_message('assistant'):
# 以流式的方式渲染答案
streamResp = st.write_stream(invoke_history_by_stream(chain,user_prompt,session_id))
# 保存历史,上面用来遍历显示,避免后面覆盖前面的显示
st.session_state.chat_history.append({'role': 'assistant', 'content': streamResp})
这就是流的代码,可以执行一下。
四、优化一版
我们再来优化一下样式。这个可以有可以不做,最好交给前端来做,streamlit的ui太生硬了。加了几个模板占位的替换。
from dotenv import load_dotenv
from langchain_community.chat_message_histories import ElasticsearchChatMessageHistory
from langchain_ollama import ChatOllama
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_core.prompts import MessagesPlaceholder, ChatPromptTemplate
from streamlit import streamlit as st
load = load_dotenv("./.env")
es_url = "http://localhost:9200"
index_name = "chat_history"
def get_session_history(session_id: str) :
return ElasticsearchChatMessageHistory(index=index_name,session_id=session_id,es_url=es_url,ensure_ascii=False)
# init llm
llm = ChatOllama(
base_url = "http://127.0.0.1:11434",
model = "huihui_ai/deepseek-r1-abliterated:14b",
temperature = 0.5,
num_predict = 10000
)
user_id = "levi"
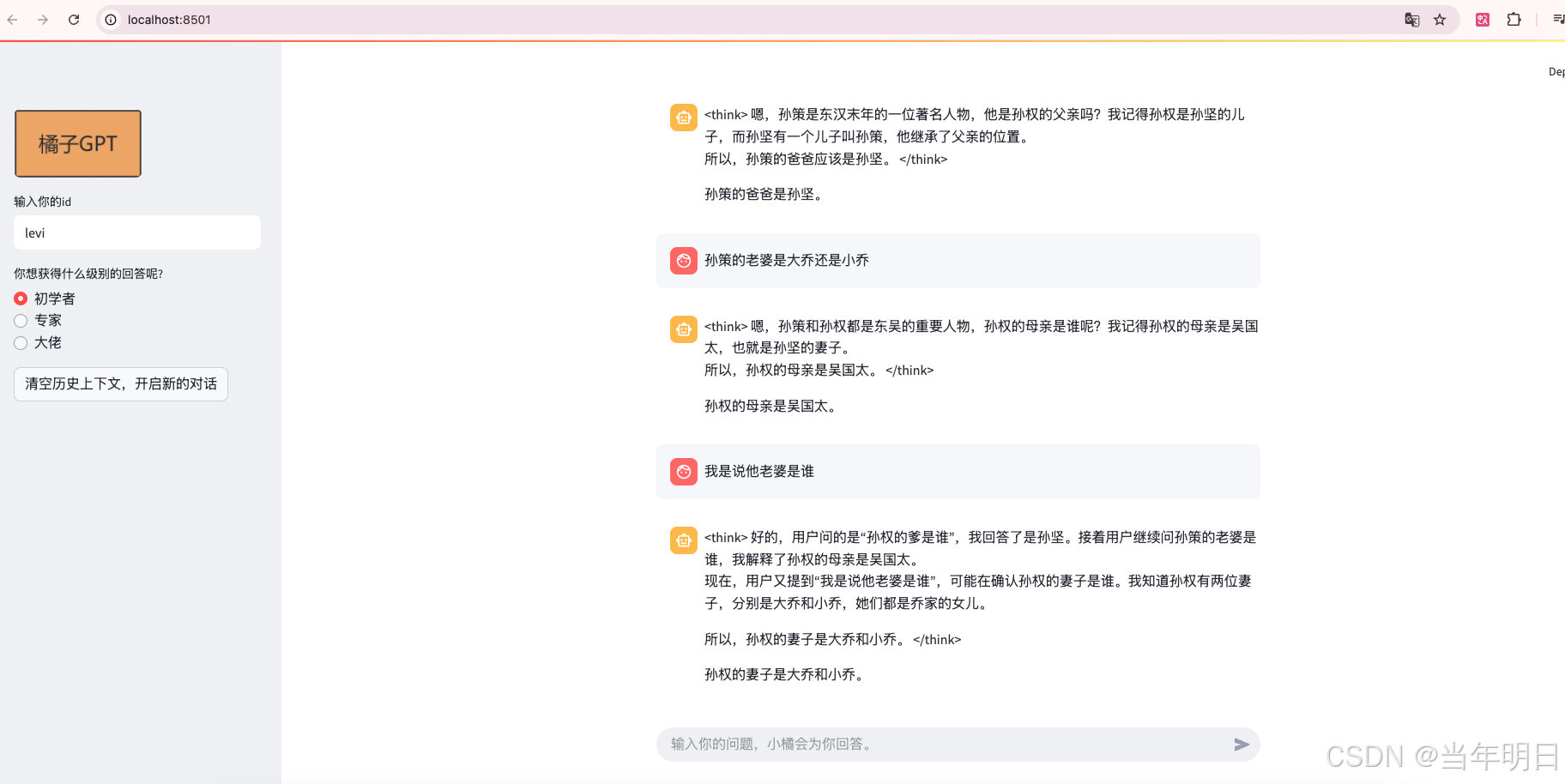
with st.sidebar:
st.image("./orange.png", width=150)
user_id = st.text_input("输入你的id", user_id)
role = st.radio("你想获得什么级别的回答呢?", ["初学者", "专家", "大佬"], index=0)
if st.button("清空历史上下文,开启新的对话"):
st.session_state.chat_history = []
get_session_history(user_id).clear()
st.markdown(
"""
<div style='display: flex; height: 70vh; justify-content: center; align-items: center;'>
<h2>请问你需要什么帮助呢?</h2>
</div>
""",
unsafe_allow_html=True
)
if 'chat_history' not in st.session_state:
st.session_state.chat_history = []
for message in st.session_state.chat_history:
with st.chat_message(message['role']):
st.markdown(message['content'])
template = ChatPromptTemplate.from_messages([
MessagesPlaceholder(variable_name="history"),
('system', f"你作为一个 {role} 级别的人来回答这个问题"),
('human', "{prompt}")
])
chain = template | llm | StrOutputParser()
def invoke_history(chain, session_id, prompt):
history = RunnableWithMessageHistory(chain,
get_session_history,
input_messages_key="prompt",
history_messages_key="history")
for response in history.stream({"prompt": prompt},config={"configurable": {"session_id": session_id}}):
yield response
prompt = st.chat_input("输入你的问题,小橘会为你回答。")
if prompt:
st.session_state.chat_history.append({'role': 'user', "content": prompt})
with st.chat_message('user'):
st.markdown(prompt)
with st.chat_message('assistant'):
streamResponse = st.write_stream(invoke_history(chain, user_id, prompt))
st.session_state.chat_history.append({'role': 'assistant', "content": streamResponse})


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









