







原文地址:http://www.bubuko.com/infodetail-701576.html
学习深度学习,不可避免的要选择一个适合于自己的框架,目前深度学习的主流框架有caffe,Theano,Torch7等,而由Yangqing Jia等人开发并维护的caffe框架,由于其代码简洁,可读性强,较高的运行效率以及CPU/GPU切换简单,并且拥有较大的user group,所以越来越受到学习者的重视.
caffe框架基于c++语言编写,并且具有licensed BSD,开放源码,具有matlab和python接口,关于caffe的详细介绍参考论文"Caffe:convolutional architecture for fast feature embedding",网址http://caffe.berkeleyvision.org/.本文先介绍caffe框架的网络定义.GitHub中有源码下载,源代码中的文件类型有.cpp,.prototxt,.sh,.m.,.py等,caffe框架的网络定义都放在.prototxt文件中.所以我们先分析此类文件.
1.Vision layers(头文件位置: ./include/caffe/vision_layers.hpp)
(i)卷积层
例子:
layers {
name: "conv1"
type: CONVOLUTION #层类型
bottom: "data"
top: "conv1"
blobs_lr: 1 # learning rate multiplier for the filters
blobs_lr: 2 # learning rate multiplier for the biases
weight_decay: 1 # weight decay multiplier for the filters
weight_decay: 0 # weight decay multiplier for the biases
convolution_param {
num_output: 96 # learn 96 filters
kernel_size: 11 # each filter is 11x11
stride: 4 # step 4 pixels between each filter application
weight_filler {
type: "gaussian" # initialize the filters from a Gaussian
std: 0.01 # distribution with stdev 0.01 (default mean: 0)
}
bias_filler {
type: "constant" # initialize the biases to zero (0)
value: 0
}
}
}
top和bottom:输出和输入
convolution_param:
必须:
num_output(c_o): 滤波器数目kernel_size(orkernel_handkernel_w): 滤波器尺寸
建议:
weight_filler [default type: ‘constant‘ value: 0]:滤波器权重
可选:
bias_term[defaulttrue]: 指定滤波器输出是否加偏置pad(orpad_handpad_w) [default 0]: 指定输入需要padding的尺寸stride(orstride_handstride_w) [default 1]: 指定滤波器滑动步长group(g) [default 1]: 如果 g > 1, 输入和输出map都被分为g组,第i组的输入对应第i组的输出.
例子:
layers {
name: "pool1"
type: POOLING
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3 # pool over a 3x3 region
stride: 2 # step two pixels (in the bottom blob) between pooling regions
}
}
top和bottom:输出和输入
pooling_param:
必须:
kernel_size (or kernel_h and kernel_w): 指定滤波器尺寸
可选:
pool[default MAX]: 池化方法. 可选项为 MAX, AVE, or STOCHASTICpad(orpad_handpad_w) [default 0]: 指定输入需要padding的尺寸stride(orstride_handstride_w) [default 1]: 指定滤波器滑动步长
(iii)局部响应正则化(Local Response Normalization)
层类型:LRN
lrn_param:
可选:
local_size[default 5]: 需要加和的通道数 (for cross channel LRN) or 需要加和的正方形区域尺寸 (for within channel LRN)alpha[default 1]:尺度化参数(see below)beta[default 5]: 指数 (see below)norm_region[defaultACROSS_CHANNELS]: 对相邻通道求和 (ACROSS_CHANNELS) or 对相邻空间位置求和 (WITHIN_CHANNEL)
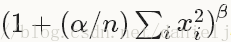
2.Loss layers
神经网络能够执行运算的动力就是误差层,forward pass运算得到loss,backward pass运算利用loss计算gradient.
(i)softmax
层类型:SOFTMAX_LOSS
(ii)Sum-of-Squares / Euclidean
层类型: EUCLIDEAN_LOSS
(iii)Hinge / Margin
例子:
# L1 Norm
layers {
name: "loss"
type: HINGE_LOSS #层类型
bottom: "pred"
bottom: "label"
}
# L2 Norm
layers {
name: "loss"
type: HINGE_LOSS
bottom: "pred"
bottom: "label"
top: "loss"
hinge_loss_param {
norm: L2
}
}
norm [default L1]: 范数类型. 可选范数 L1, L2
(IV)Sigmoid Cross-Entropy
层类型:SIGMOID_CROSS_ENTROPY_LOSS
(V)Infogain
层类型:INFOGAIN_LOSS
(i)ReLU / Rectified-Linear and Leaky-ReLU
例子:
layers {
name: "relu1"
type: RELU #层类型
bottom: "conv1"
top: "conv1"
}
relu_param:
可选
negative_slope [default 0]: 指定输入为负时的输出
(ReLU是常用的激活函数,因为收敛速度快,不易饱和.给定输入x,如果x>0,则输出x,否则输出negative_slope*x,如果未设定negative_slope的值,则等效于标准的relu操作,支持in-place运算,意味着bottom和top相同时可以避免内存的消耗.)

例子
layers {
name: "encode1neuron"
bottom: "encode1"
top: "encode1neuron"
type: SIGMOID #层类型
}
例子
layers {
name: "layer"
bottom: "in"
top: "out"
type: TANH #层类型
}
例子
layers {
name: "layer"
bottom: "in"
top: "out"
type: ABSVAL #层类型
}
例子
layers {
name: "layer"
bottom: "in"
top: "out"
type: POWER #层类型
power_param {
power: 1
scale: 1
shift: 0
}
}
power_param:
可选
power[default 1]scale[default 1]shift[default 0]
(输出等于(shift + scale * x) ^ power)
(V)BNLL(binomial normal log likelihood)
layers {
name: "layer"
bottom: "in"
top: "out"
type: BNLL #层类型
}
4.Data Layers
根据数据输入网络的方式,参数也有所不同.
(i)Database
例子
layers {
name: "mnist"
# DATA layer 加载 leveldb or lmdb数据库进行大数据运算.
type: DATA #层类型
# the 1st top is the data itself: 名字是任意的
top: "data"
# the 2nd top is the ground truth: 名字是任意的
top: "label"
# the DATA layer configuration
data_param {
# path to the DB
source: "examples/mnist/mnist_train_lmdb"
# 数据库类型: LEVELDB or LMDB (LMDB supports concurrent reads)
backend: LMDB
# 批处理块大小
batch_size: 64
}
# 数据转换
transform_param {
# 归一化系数: this maps the [0, 255] MNIST data to [0, 1]
scale: 0.00390625 #1/256
}
}
必须
source:数据库路径名batch_size: 每次处理的块大小
rand_skip: 计算开始时跳过rand_skip这批输入,这在异步随机梯度下降算法中很有用backend[defaultLEVELDB]: 选择LEVELDBorLMDB
层类型:MEMORY_DATA
必须参数:batch_size, channels, height, width: 指定从内存中读取数据块的大小
(直接从内存中读取数据而非复制,使用是需要调用MemoryDataLayer::Reset (from C++) orNet.set_input_arrays (from Python)来指定读取的数据块)
(iii)HDF5 Input
层类型:HDF5_DATA
必须参数
source: 读取文件名batch_size
层类型:HDF5_OUTPUT
必须参数:
file_name: 写文件名
(V)Images
层类型:IMAGE_DATA
参数类型
必须
source: 文本文件名, 文件没一行代表一幅图像和一个标签batch_size: number of images to batch together
rand_skipshuffle[default false]new_height,new_width: resize all images to this size
层类型:WINDOW_DATA
(VII)Dummy
层类型:DUMMY_DATA(DUMMY_DATA is for development and debugging. SeeDummyDataParameter.)
5.Common Layers
(I)Inner Product(fully connected layer)
例子
layers {
name: "fc8"
type: INNER_PRODUCT #层类型
blobs_lr: 1 # 滤波器学习率
blobs_lr: 2 # 偏置学习率
weight_decay: 1 # 滤波器权重衰减
weight_decay: 0 # 偏置权重衰减
inner_product_param {
num_output: 1000
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
bottom: "fc7"
top: "fc8"
}
inner_product_param:
必须
num_output (c_o): 滤波器个数
建议
weight_filler [default type: ‘constant‘ value: 0]
可选
bias_filler[defaulttype: ‘constant‘ value: 0]bias_term[defaulttrue]: 指定是否设定偏置
(ii)Splitting
SPLIT
(用于讲输入blob分为多个blobs,适用于有多个输出层的情况)
(iii)Flattening
层类型:FLATTEN
(把输入矩阵 n * c * h * w 转换为向量n * (c*h*w) * 1 * 1.)
(IV)Concatenation
例子
layers {
name: "concat"
bottom: "in1"
bottom: "in2"
top: "out"
type: CONCAT #层类型
concat_param {
concat_dim: 1
}
}concat_dim[default 1]: 0 for concatenation along num and 1 for channels.
例子
layers {
name: "slicer_label"
type: SLICE #层类型
bottom: "label"
## Example of label with a shape N x 3 x 1 x 1
top: "label1"
top: "label2"
top: "label3"
slice_param {
slice_dim: 1 #目标维度,0 for num and1for channel
slice_point: 1 #slice_point表示指定维度中的索引,索引数等于输出blobs中最小的那个
slice_point: 2
}
}
层类型:ELTWISE
(VII)Argmax
层类型:ARGMAX
(VIII)Softmax
层类型:SOFTMAX
层类型:MVN
由以上的定义我们也能看出来,caffe框架还不太完善,需要更多的人才不懈努力,尤其是我们青年才俊更是如此,以后还会对此文进行更新的.















 2514
2514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









