







目录
1、Lambda表达式
2、函数式接口
3、Lambda语法
4、方法引用
5、Stream
6、并行操作
参考代码:https://github.com/xiangqian19831224/lambda
一、Lambda表达式
1、用处
Lambda表达式可以替代只有一个抽象函数的接口<函数式接口>实现。
提升了对集合,框架的迭代,遍历,过滤数据等操作
2、特点
函数式编程
参数类型自动推断
代码简洁
例如:
public static void main(String[] args){
new Thread(new Runnable(){
public void run(){
System.out.println("runnable 是只有一个抽象函数的接口");
}).start();
}
new Thread(()->{System.out.println("只是用一个lambda表达式替代了Runnable的实现");}).start();
}
二、函数式接口
只有一个抽象方法(Object类中的方法除外)的接口是函数式接口
1> Supplier : 代表一个输出
2> Comsumer : 代表一个输入
3> BiComsumer :两个输入
4> Function :一个输入一个输出 输入输出类型可以不同
5> UnaryOperator : 一个输入一个输出 输入输出类型相同
6> BiFunction :两个输入一个输出 输入输出类型可以不同
7> BinaryOperator :两个输入一个输出 输入输出类型相同
三、Lambda语法
1、概念
Lambda表达式是对象,是一个函数式接口的实例
2、语法
(Object… args) -> {函数式接口抽象方法实现逻辑}

参数个数由函数式接口中的抽象方法的参数个数决定
一个参数可以省略()
实现逻辑简单时候,{}和return都可以省略
3、示例
() -> {} // 无参,无返回值
() -> { System.out.println(1); } // 无参,无返回值
() -> System.out.println(1)//无参,无返回值(上面的简写)
() -> { return 100; } // 无参,有返回值
() -> 100 // 无参,有返回值(上面的简写)
() -> null // 无参,有返回值(返回null)
(int x) -> { return x+1; } // 单个参数,有返回值
(int x) -> x+1 // 单个参数,有返回值(上面的简写)
(x) -> x+1 // 单个参数,有返回值(不指定参数类型,多个参数必须用括号)
x -> x+1 //单个参数,有返回值(不指定参数类型)
4、注意不需要也不允许使用throws语句来声明它可能会抛出的异常
四、方法引用
1、概念
用直接访问类或者示例已经存在的方法或者构造方法
2、类型
| 类型 | 语法 | 对应lambda表达式 |
| 静态方法引用 | className::staticMethod | (args)->className.staticMethod(args) |
| 实例方法引用 | instance::instMethod | (args)->instance.instMethod(args) |
| 对象方法引用 | className::instMethod | (args)->className.instMethod(args) |
| 构造方法引用 | className::new | (args)->new className(args) |
对象方法引用: 抽象方法的第一个参数类型刚好是实例方法的类型,抽象方法剩余的参数恰好可以当做实例方法的参数。如果函数式接口的实现可以由上面说的实例方法调用来实现的话,那么就可以使用对象方法引用
构造方法引用:如果函数式接口的实现恰好可以通过调用一个类的构造方法来实现,那么就可以使用构造方法引用
五、stream API
1、概念
对一组数据支持串行和并行累加处理的操作的API
2、特点
不是数据结构,没有内部存储
不支持索引访问
延迟计算
支持并行
容易生成数据或计划(List, Set)
支持过滤,查找,转化,汇总,聚合等操作
3、机制
Stream分为源,中间操作,终止操作
1> 源: 数组,集合,生成器方法,I/O通道
生成方法: 数组,集合,Stream.generate, Stream.iterate,其他
2> 中间操作: 返回新的流
过滤filter,去重distinct,排序sorted,截取limit、skip,转换map/flatMap/mapToInt,其他peek
3> 终止操作:开启执行遍历操作
循环:foreach
计算:min,max,count,average,sum
匹配:anyMatch,allMatch,noneMatch,findFirst,findAny
汇聚:reduce
收集器: toArray,collect
六、stream深度分析
参考:http://www.cnblogs.com/CarpenterLee/p/6637118.html
1、函数回调
stream API大量使用表达式作为回调方法。
回调示例:
ArrayList.forEach()实现:
default void forEach(Consumer<? super T> action) { Objects.requireNonNull(action); for (T t : this) { action.accept(t); } }2、Stream操作
| Stream操作分类 | ||
| 中间操作(Intermediate operations) | 无状态(Stateless) | unordered() filter() map() mapToInt() mapToLong() mapToDouble() flatMap() flatMapToInt() flatMapToLong() flatMapToDouble() peek() |
| 有状态(Stateful) | distinct() sorted() sorted() limit() skip() | |
| 终止操作(Terminal operations) | 非短路操作 | forEach() forEachOrdered() toArray() reduce() collect() max() min() count() |
| 短路操作(short-circuiting) | anyMatch() allMatch() noneMatch() findFirst() findAny() | |
中间操作: 只是一种标记,不触发计算
终止操作: 出发实际的计算
无状态:元素的处理不受前面元素的影响
有状态: 元素的处理受前面元素的影响,必须等到所有元素的处理之后才知道最终结果
短路操作:不需要处理完全部元素就可以返回结果
非短路操作:处理完所有的元素才可以返回结果
3、stream优点
1> 简单的实现:
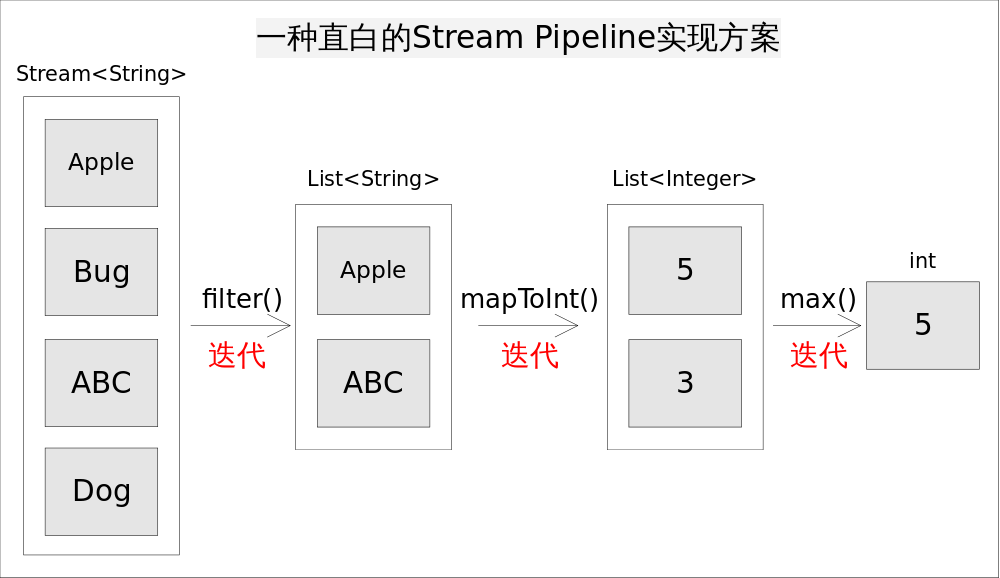
int longest =0;
for(String str : strings){
if(str.startsWith("A")){// 1. filter(), 保留以A开头的字符串
int len = str.length();// 2. mapToInt(), 转换成长度
longest = Math.max(len, longest);// 3. max(), 保留最长的长度
}
}
2> 简单实现缺点:
迭代次数多
频繁产生中间结果
3> stream
尽量减少迭代次数
减少中间结果的产生
并行计算
4、Stream流水线
关键问题:
1> 操作如何记录
2> 操作如何叠加
3> 叠加后如何执行
4> 结果记录在哪里
详细解析:
1> 操作如何记录
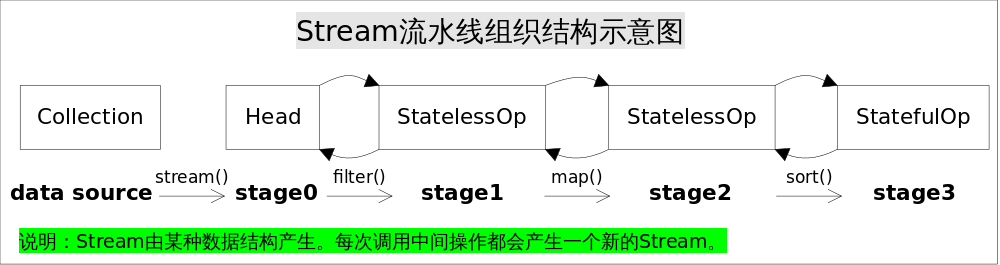
每个stage记录:
前一个stage
本次的操作
回调函数
2> 操作如何叠加
叠加协议 Sink
| 方法名 | 作用 |
| void begin(long size) | 开始遍历元素之前调用该方法,通知Sink做好准备。 |
| void end() | 所有元素遍历完成之后调用,通知Sink没有更多的元素了。 |
| boolean cancellationRequested() | 是否可以结束操作,可以让短路操作尽早结束。 |
| void accept(T t) | 遍历元素时调用,接受一个待处理元素,并对元素进行处理。Stage把自己包含的操作和回调方法封装到该方法里,前一个Stage只需要调用当前Stage.accept(T t)方法就行了。 |
| 方法名 | 作用 |
| void begin(long size) | 开始遍历元素之前调用该方法,通知Sink做好准备。 |
| void end() | 所有元素遍历完成之后调用,通知Sink没有更多的元素了。 |
| boolean cancellationRequested() | 是否可以结束操作,可以让短路操作尽早结束。 |
| void accept(T t) | 遍历元素时调用,接受一个待处理元素,并对元素进行处理。Stage把自己包含的操作和回调方法封装到该方法里,前一个Stage只需要调用当前Stage.accept(T t)方法就行了。 |
accept: 必须实现,每个stage通过accept接受数据并调用后一个stage的accept操作
bengin:
end: 有状态方法必须实现
cancellationRequested: 短路操作必须实现
void accept(U u){
1. 使用当前sink包装的回调函数处理u
2. 将结果传递给流水线下游的sink
}
// Stream.map(),调用该方法将产生一个新的Stream public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper) { ... return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE, StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) { @Override /*opWripSink()方法返回由回调函数包装而成Sink*/ Sink<P_OUT> opWrapSink(int flags, Sink<R> downstream) { return new Sink.ChainedReference<P_OUT, R>(downstream) { @Override public void accept(P_OUT u) { R r = mapper.apply(u);// 1. 使用当前Sink包装的回调函数mapper处理u downstream.accept(r);// 2. 将处理结果传递给流水线下游的Sink } }; } }; }
// Stream.sort()方法用到的Sink实现 class RefSortingSink<T> extends AbstractRefSortingSink<T> { private ArrayList<T> list;// 存放用于排序的元素 RefSortingSink(Sink<? super T> downstream, Comparator<? super T> comparator) { super(downstream, comparator); } @Override public void begin(long size) { ... // 创建一个存放排序元素的列表 list = (size >= 0) ? new ArrayList<T>((int) size) : new ArrayList<T>(); } @Override public void end() { list.sort(comparator);// 只有元素全部接收之后才能开始排序 downstream.begin(list.size()); if (!cancellationWasRequested) {// 下游Sink不包含短路操作 list.forEach(downstream::accept);// 2. 将处理结果传递给流水线下游的Sink } else {// 下游Sink包含短路操作 for (T t : list) {// 每次都调用cancellationRequested()询问是否可以结束处理。 if (downstream.cancellationRequested()) break; downstream.accept(t);// 2. 将处理结果传递给流水线下游的Sink } } downstream.end(); list = null; } @Override public void accept(T t) { list.add(t);// 1. 使用当前Sink包装动作处理t,只是简单的将元素添加到中间列表当中 } }
Sink的四个接口协同工作:
首先beging()方法告诉Sink参与排序的元素个数,方便确定中间结果容器的的大小;
之后通过accept()方法将元素添加到中间结果当中,最终执行时调用者会不断调用该方法,直到遍历所有元素;
最后end()方法告诉Sink所有元素遍历完毕,启动排序步骤,排序完成后将结果传递给下游的Sink;
如果下游的Sink是短路操作,将结果传递给下游时不断询问下游cancellationRequested()是否可以结束处理。
3> 如何执行
终止操作触发操作,终止操作需要解决问题:
--->梳理调用流程:
上游Sink如何找到下游Sink:
// AbstractPipeline.wrapSink()
// 从下游向上游不断包装Sink。如果最初传入的sink代表结束操作, // 函数返回时就可以得到一个代表了流水线上所有操作的Sink。 final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) { ... for (AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) { sink = p.opWrapSink(p.previousStage.combinedFlags, sink); } return (Sink<P_IN>) sink; } --->执行过程
// AbstractPipeline.copyInto(), 对spliterator代表的数据执行wrappedSink代表的操作。 final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) { ... if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) { wrappedSink.begin(spliterator.getExactSizeIfKnown());// 通知开始遍历 spliterator.forEachRemaining(wrappedSink);// 迭代 wrappedSink.end();// 通知遍历结束 } ... }
4> 结果存储
| 返回类型 | 对应的结束操作 |
| boolean | anyMatch() allMatch() noneMatch() |
| Optional | findFirst() findAny() |
| 归约结果 | reduce() collect() |
| 数组 | toArray() |
ArrayList<String> results = new ArrayList<>(); stream.filter(s -> pattern.matcher(s).matches()) .forEach(s -> results.add(s)); // Unnecessary use of side-effects! // 正确的收集方式 List<String>results = stream.filter(s -> pattern.matcher(s).matches()) .collect(Collectors.toList()); // No side-effects!
- 返回boolean或者Optional的操作: 只需要在对应的Sink中记录这个值,等到执行结束时返回就可以了。
- 归约操作: 最终结果放在用户调用时指定的容器中(容器类型通过收集器指定)。collect(), reduce(), max(), min()都是归约操作,虽然max()和min()也是返回一个Optional,但事实上底层是通过调用reduce()方法实现的。
- 返回是数组的情况: 毫无疑问的结果会放在数组当中。这么说当然是对的,但在最终返回数组之前,结果其实是存储在一种叫做Node的数据结构中的。Node是一种多叉树结构,元素存储在树的叶子当中,并且一个叶子节点可以存放多个元素。这样做是为了并行执行方便。关于Node的具体结构,我们会在下一节探究Stream如何并行执行时给出详细说明。
六、并行操作——回头再补充
参考: http://lvheyang.com/?p=87

abstract class AbstractPipeline<E_IN, E_OUT, S extends BaseStream<E_OUT, S>> extends PipelineHelper<E_OUT> implements BaseStream<E_OUT, S> { ... ... /** * Evaluate the pipeline with a terminal operation to produce a result. * * @param <R> the type of result * @param terminalOp the terminal operation to be applied to the pipeline. * @return the result */ final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) { assert getOutputShape() == terminalOp.inputShape(); if (linkedOrConsumed) throw new IllegalStateException(MSG_STREAM_LINKED); linkedOrConsumed = true; return isParallel() ? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags())) : terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags())); } }
interface TerminalOp<E_IN, R> { ... ... /** * Performs a parallel evaluation of the operation using the specified * {@code PipelineHelper}, which describes the upstream intermediate * operations. * * @implSpec The default performs a sequential evaluation of the operation * using the specified {@code PipelineHelper}. * * @param helper the pipeline helper * @param spliterator the source spliterator * @return the result of the evaluation */ default <P_IN> R evaluateParallel(PipelineHelper<E_IN> helper, Spliterator<P_IN> spliterator) { if (Tripwire.ENABLED) Tripwire.trip(getClass(), "{0} triggering TerminalOp.evaluateParallel serial default"); return evaluateSequential(helper, spliterator); }
/** * A short-circuiting {@code TerminalOp} that searches for an element in a * stream pipeline, and terminates when it finds one. Implements both * find-first (find the first element in the encounter order) and find-any * (find any element, may not be the first in encounter order.) * * @param <T> the output type of the stream pipeline * @param <O> the result type of the find operation, typically an optional * type */ private static final class FindOp<T, O> implements TerminalOp<T, O> { private final StreamShape shape; final boolean mustFindFirst; final O emptyValue; final Predicate<O> presentPredicate; final Supplier<TerminalSink<T, O>> sinkSupplier; ... ... @Override public <P_IN> O evaluateParallel(PipelineHelper<T> helper, Spliterator<P_IN> spliterator) { return new FindTask<>(this, helper, spliterator).invoke(); } }
abstract class AbstractTask<P_IN, P_OUT, R, K extends AbstractTask<P_IN, P_OUT, R, K>> extends CountedCompleter<R> { ...... @Override public void compute() { Spliterator<P_IN> rs = spliterator, ls; // right, left spliterators long sizeEstimate = rs.estimateSize();//预估分片中的数据量 long sizeThreshold = getTargetSize(sizeEstimate);//设置最小执行单元的数量 boolean forkRight = false; @SuppressWarnings("unchecked") K task = (K) this; while (sizeEstimate > sizeThreshold && (ls = rs.trySplit()) != null) {//分片大小大于处理单元的阈值,尝试分片成功就进行分片 K leftChild, rightChild, taskToFork; task.leftChild = leftChild = task.makeChild(ls); task.rightChild = rightChild = task.makeChild(rs); task.setPendingCount(1); if (forkRight) { forkRight = false; rs = ls; task = leftChild; taskToFork = rightChild; } else { forkRight = true; task = rightChild; taskToFork = leftChild; } taskToFork.fork();//对左右子节点进行fork sizeEstimate = rs.estimateSize(); }//任务足够小的时候推出循环 task.setLocalResult(task.doLeaf());//task.doLeaf 完成最小计算单元的计算任务,并设置到当前任务的localResult中 task.tryComplete();//扫尾工作 }}
七、补充 ForkJoin机制
参考:
http://www.cnblogs.com/chenpi/p/5581198.html
http://www.cnblogs.com/shijiaqi1066/p/4631466.html
1、示例
import java.awt.image.BufferedImage; import java.io.File; import java.util.concurrent.ForkJoinPool; import java.util.concurrent.RecursiveAction; import javax.imageio.ImageIO; /** * ForkBlur implements a simple horizontal image blur. It averages pixels in the * source array and writes them to a destination array. The sThreshold value * determines whether the blurring will be performed directly or split into two * tasks. * * This is not the recommended way to blur images; it is only intended to * illustrate the use of the Fork/Join framework. */ public class ForkBlur extends RecursiveAction { private static final long serialVersionUID = -8032915917030559798L; private int[] mSource; private int mStart; private int mLength; private int[] mDestination; private int mBlurWidth = 15; // Processing window size, should be odd. public ForkBlur(int[] src, int start, int length, int[] dst) { mSource = src; mStart = start; mLength = length; mDestination = dst; } protected static int sThreshold = 10000; @Override protected void compute() { if (mLength < sThreshold) { computeDirectly();//核心计算 return; } int split = mLength / 2; invokeAll(new ForkBlur(mSource, mStart, split, mDestination), new ForkBlur(mSource, mStart + split, mLength - split, mDestination));//ForkJoin使用 } // Plumbing follows. public static void main(String[] args) throws Exception { String srcName = "D:\\test.jpg"; File srcFile = new File(srcName); BufferedImage image = ImageIO.read(srcFile); System.out.println("Source image: " + srcName); BufferedImage blurredImage = blur(image); String dstName = "D:\\test_out.jpg"; File dstFile = new File(dstName); ImageIO.write(blurredImage, "jpg", dstFile); System.out.println("Output image: " + dstName); }// Average pixels from source, write results into destination. protected void computeDirectly() { int sidePixels = (mBlurWidth - 1) / 2; for (int index = mStart; index < mStart + mLength; index++) { // Calculate average. float rt = 0, gt = 0, bt = 0; for (int mi = -sidePixels; mi <= sidePixels; mi++) { int mindex = Math.min(Math.max(mi + index, 0), mSource.length - 1); int pixel = mSource[mindex]; rt += (float) ((pixel & 0x00ff0000) >> 16) / mBlurWidth; gt += (float) ((pixel & 0x0000ff00) >> 8) / mBlurWidth; bt += (float) ((pixel & 0x000000ff) >> 0) / mBlurWidth; } // Re-assemble destination pixel. int dpixel = (0xff000000) | (((int) rt) << 16) | (((int) gt) << 8) | (((int) bt) << 0); mDestination[index] = dpixel; } }public static BufferedImage blur(BufferedImage srcImage) { int w = srcImage.getWidth(); int h = srcImage.getHeight(); int[] src = srcImage.getRGB(0, 0, w, h, null, 0, w); int[] dst = new int[src.length]; System.out.println("Array size is " + src.length); System.out.println("Threshold is " + sThreshold); int processors = Runtime.getRuntime().availableProcessors(); System.out.println(Integer.toString(processors) + " processor" + (processors != 1 ? "s are " : " is ") + "available"); ForkBlur fb = new ForkBlur(src, 0, src.length, dst); ForkJoinPool pool = new ForkJoinPool(); long startTime = System.currentTimeMillis(); pool.invoke(fb); //触发操作 long endTime = System.currentTimeMillis(); System.out.println("Image blur took " + (endTime - startTime) + " milliseconds."); BufferedImage dstImage = new BufferedImage(w, h, BufferedImage.TYPE_INT_ARGB); dstImage.setRGB(0, 0, w, h, dst, 0, w); return dstImage; }}
2、ForkJoin原理
回头再补充















 839
839











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









