









0、前言
大家在开发vue项目的时候,常常会发现url中带有#号,用webstorm开发vue项目的时候,会默认在url中带有#号
例如启动后的链接:http://0.0.0.0:18000/#/,端口配的是18000
本人刚入行前端开发,特此记录下自己去掉#的过程,中幼稚处不少,望各位路过大神高抬贵手
本人的项目链接:http://0.0.0.0:18000/#/api/newsList,因是单位项目,页面具体内容就不给大家显示了,显示个部分吧

红色api在此处特别标出,是为了与后台api接口做比较,config/index.js我是这样配置跨域的,路径中也用了api
接口url:http://x.x.x.x:31000/api/top_news?page=2&page_size=10
assetsSubDirectory: 'static',
assetsPublicPath: '/',
proxyTable: {
'/api': {
target: 'http://x.x.x.x:31000/',
secure: false,
// ws: true,
changeOrigin: true,
// pathRewrite: {
// '^/api': ''
// },
},
},
// Various Dev Server settings
host: '0.0.0.0', // can be overwritten by process.env.HOST21·
port: 18000, // can be overwritten by process.env.PORT, if port is in use, a free one will be determined
不多说了,下面显示具体去掉过程
1、修改router/index.js文件
增加 mode: 'history',例如
export default new Router({
base: 'aaa',
mode: 'history',
routes: [
{
path: '/',
name: 'HelloWorld',
component: HelloWorld
},
{
path: '/api/newsList',
name: 'newsList',
component: newsList
},
...因为修改的是router的index.js文件,所以需要重启服务
访问无#链接:http://0.0.0.0:18000/,正常显示

改后访问新闻页http://0.0.0.0:18000/api/newsList,发现不正常显示
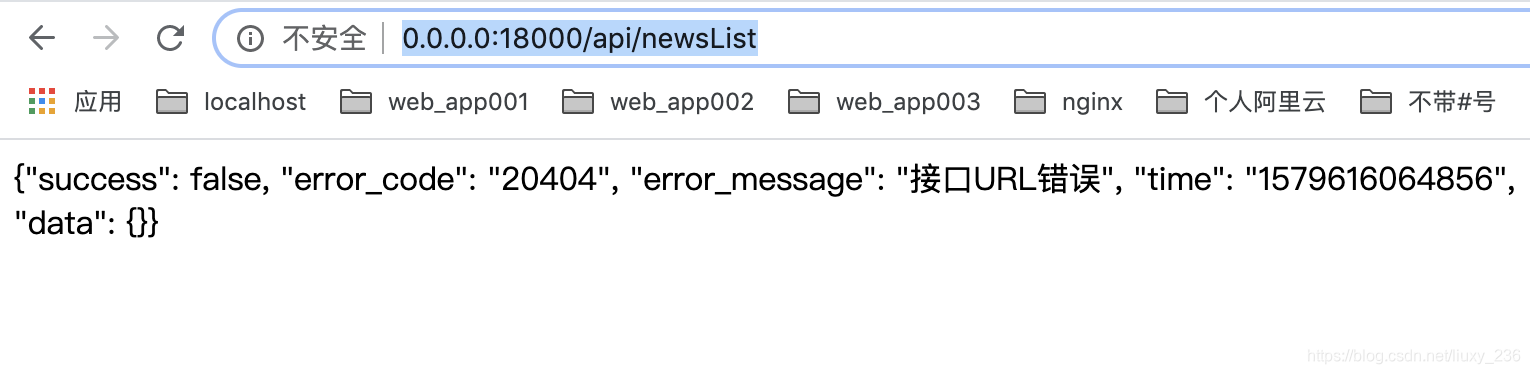
因为去掉#号后,此链接中的api与跨域配置中的'api'是冲突的,有#的存在可以很好区别这两个api路径名称,
解决办法有两种:
其一,此时解决办法可以改跨域接口配置中的api为别的名称,同时将后台接口中的api改为同样的名字http://x.x.x.x:31000/api2/top_news?page=2&page_size=10。这种改动较大,不建议采用
proxyTable: {
'/api2': {
target: 'http://x.x.x.x:31000/',其二,页面url中的链接api名称,如http://0.0.0.0:18000/ap3i/newsList
{
path: '/ap3i/newsList',
name: 'newsList',
component: newsList
},注意:此处没有改为/api3,因为仍会与proxyTable中配置的'/api'产生冲突,因为proxyTable是按照由前到后匹配的,不是按照整个字符串匹配的,成功界面如下:

或者是将/api去掉,因api一般是用在后台接口,前端页面一般不用,本文采用自方法,去掉api。如http://0.0.0.0:18000/newsList














 2346
2346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









