







https://www.researchgate.net/publication/326621822_Bilingual_Expert_Can_Find_Translation_Errors
“双语专家”可以发现翻译错误
Github:https://github.com/lovecambi/qebrain
Abstract
机器翻译 MT 系统的性能一般用 BLEU 评估,然而参考翻译通常是昂贵的。为了在没有参考翻译时解决质量评估 QE 问题,首先使用双向 Transformer(neural bilingual expert)模型构建条件目标语言模型,该模型使用大型平行语料预训练以进行特征提取。QE 预测时,基于从平行数据中学到的先验知识,双语专家模型可以同时生成源和翻译之间的联合潜在表征、以及可能错误的词。随后,将这些特征输入一个简单的 Bi-LSTM 预测模型进行质量评估。实验表明,本方法在 WMT 2017/2018 QE 任务的大多数公共可用数据集中均达到了最先进的水平。
Introduction
当前的 MT 系统在没有人工后编辑的情况下不能完美地应用,即使是简单的翻译输出,也可能需要进行额外的纠错,即计算机辅助翻译 CAT 中与人工翻译结合,QE 在 CAT 中至关重要,可以减少人的工作量,从而提高生产力。句子质量得分或细粒度的单词 OK / BAD 标签都可以指导 CAT,以表明机器翻译输出是否需要进一步的后编辑。
QE 方法是将句子级或词级预测得分转为回归或序列标注问题,经典基线模型是 QuEst++ 基于规则的特征提取器和 SVM。Predictor-Estimator 是基于 RNN 的特征提取器和质量估计模型,在 WMT 2017 QE 排名第一。另一个有希望的方向是建立多任务学习模型,将质量评估任务与自动后编辑 APE 结合。
本文首先采用传统的单任务框架,在实验部分提出一种扩展方法,以同时支持 QE 和 APE 的多任务学习。由于存在许多公开可用的双语语料库,因此可以随时将条件语言模型构建为健壮的特征提取器。在平行对中源和目标的高度联合潜在表征可以捕获对齐或语义信息,而将源和低质量的机器翻译输入预训练模型时,潜在特征的分布很可能与语法正确的分布不同。
此外,用预训练模型设计了4-d token mis-matching 特征,测量双语专家的预测与机器翻译输出的词之间的差异,条件语言模型双语专家使用 Transformer 构建。条件语言模型也可以起到自动后编辑的作用,不将 shifts 标注为词序错误(而是作为删除和插入),以避免在标注中引入噪音,像 TER 工具的方法一样,在句子中的每个标记之后和句子开始处,放置 gap tag,使用相同的条件语言模型网络结构来预测 gap,词级标记中使用删除操作(通过添加类 D 而不是 OK / BAD),实际上是在尝试预测 PE。
本文贡献:i)使用双向 Transformer 构建条件语言模型,在大型双语语料库上预训练,进一步可作为 APE 模型。 ii)引入4d mis-match 特征,接近 WMT17 QE 第一名的结果。 iii)词级 QE 支持 BPE 预处理。 iv)在真实数据集(IT和药学领域语料库)上的广泛实验证明方法有效,并且在大多数任务中均达到了最先进的性能。
Background
Quality Estimation for Machine Translation 给定双语语料库,可以将机器翻译系统表示为 p(t|s) = p(t|z)*p(z|s),s/t 为源句/目标句,z 为潜在变量,表示已编码的源句,因此,p(z|s) 和 p(t|z) 实际上可认为是编码器和解码器。在 QE 任务中,机器翻译系统是不可知的,训练集以三元组 (s, m, t) 的形式给出,将 s 输入未知机器翻译系统,输出为 m,t 为基于 s 和 m 的人工后编辑(混用 t 表示 golden ref 和 pe)。
可以从全局句子级或细粒度单词级评估 m 的质量。句子级分数通过对 m 进行编辑所需的百分比计算,即 HTER。词级评估为序列二分类问题,将 m 中每个词分为 OK 或 BAD。当同时存在 m 和 t 时,句子 HTER 和词标签可以通过 TER 工具确定。但是在预测时仅 s 和 m 可用。
假设训练数据包含元组 (s, m, t, h, y),h 为 HTER 标量,y 为二分类向量 OK / BAD。考虑预测情况,任务是学习回归模型 p(h|s, m) 和序列标记模型 p(y|s, m)。
Methodology
Bilingual Expert Model
首先使用 (s, t) 平行语料对训练双语专家模型,默认翻译系统 p(t|z) p(z|s) 是未知的,但在表征学习中,通常对潜在变量 z 感兴趣,其后验可能包含源和目标语言之间的深层语义信息,对下游任务是有益的。根据贝叶斯算法,可以将隐变量的后验分布写为:
![]()
其中积分 p(t|s) = ∫ p(t|z) p(z|s) dz 通常难以计算,使用变分分布 q(z|t, s) 最小化 KL 散度逼近真实后验:
![]()
优化上面的目标函数,等价于最大化:
![]()
新目标函数一个好的特性是,不必参数化或估计机器翻译模型 p(t|s)。 如果在优化过程中使用一个样本蒙特卡洛积分,则可以很容易地将(3)中的第一个期望项视为条件自动编码器系统,且如果将先验 p(z|s) 设为高斯分布,作为潜在变量的模型正则化,则可以通过分析计算出第二个 KL 项。此外,如果省略条件信息 s,则该目标正好简化为 amortized variational inference 或者变分自动编码器 VAE 框架。与大多数VAE模型类似,期望的对数似然通常近似为:
![]()
接下来,构造(3)中基于自注意的 Transformer 的两个概率分布。
Bidirectional Transformer
Transformer 完全基于注意力机制,无需循环和卷积,是大多数机器翻译竞赛中最先进的 NMT 模型。 自注意机制的优点有:(1) 其门控或乘积可以使损失传播更加清晰;(2) 可以完全取代序列对齐的循环结构;(3) 从实现的角度,训练时的并行化不重要。
双向 Transformer 的总架构如图1所示,共三个模块,输入源句的自注意编码器、输入目标句的前向/后向自注意编码器、以及目标句的重构器,其中前两个模块表示后验近似 q(z|s, t),第三个模块对应 p(t|z)。为了使预测高效,使用因式分解明确假设条件独立性:
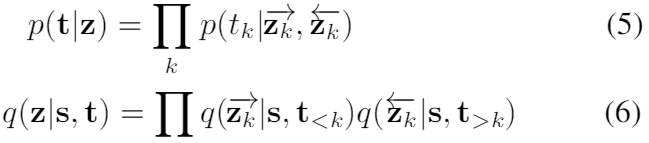
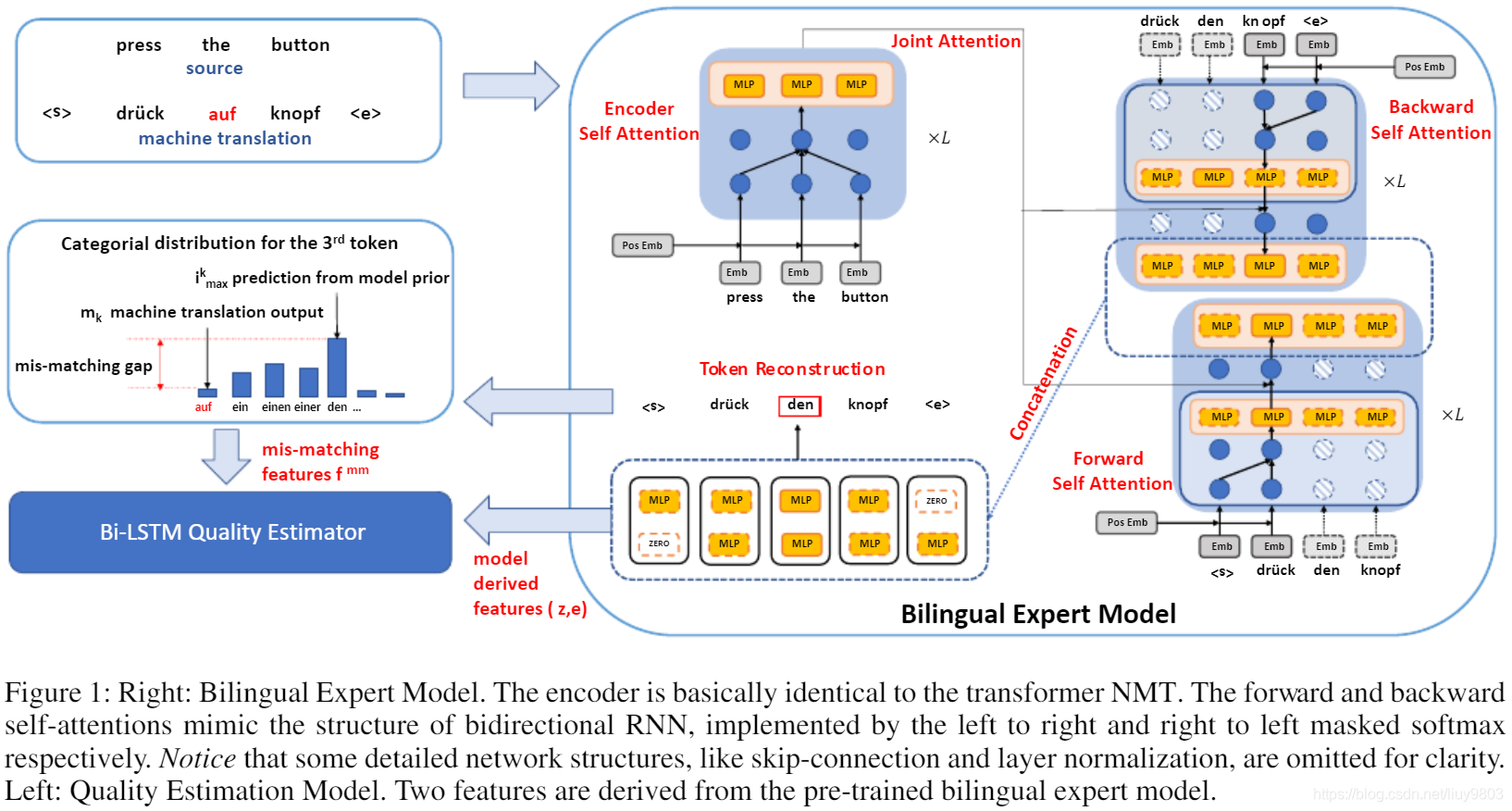
其中双向潜在变量 z 包含所有 {→zk, ←zk},因式分解与 ELMO 不同,后者使用更细粒度的形式∏_k p(tk|→zk) p(tk|←zk),但正向和反向共享参数 p(tk|·)。潜在变量→zk, ←zk 分别从 q(→zk|s, t<k) 和 q(←zk|s, t>k) 采样,假定服从高斯分布,q(·|·)〜N(μ(s, t), σ^2I)。同时,通过分摊的方式学习 µ(s, t),即每对 s, t 通过共享模型生成自己的均值。通过将 σ 固定为超参数,训练时加入高斯噪声的 dropout 可以有效地将随机层实现为确定性层(Srivastava et al. 2014)。随机层会增加潜在表征的不确定性,从而有可能防止过拟合,一般建议使用一个小的 σ。由于预测时并不是生成模型,因此并未遵循 NMT 的说法将双向自注意 transformer 称为“解码器”。
Model Derived Features
当双语专家模型在大型平行语料库上充分训练后,给定源和其他目标上下文,就可以假设该模型预测正确目标词的可能性更高。因此使用双语专家学到的先验知识提取特征,用于预测翻译错误。首先输入 (s, m) 对到预训练模型来设计序列(token-wise)模型的特征,潜在表征 zk = Concat(→zk, ←zk) ,整个潜在变量 z 总体上概括了源和目标的信息。在方程(6)中,zk 的分布被定义为包含源以及目标中第k个词周围的上下文,例如图1右边的计算图中,需要预测目标词“den”,将源和目标中其他词的信息传播到最终预测层,这对手动提取的 mis-match 特征有利。
在 ELMO 中,词嵌入也被用作一个线性分量来计算最终特征,但在我们的情况下,如果将翻译输出喂入模型,不能保证每个词都是正确的,因此根据潜在变量 zk 的信息设计一种不同的词嵌入,即使用两个相邻词的 Concat(etk-1, etk+1)。由于潜在的错误翻译可能会在下游质量估计任务中误导模型,因此不从当前词 tk 中提取任何信息,应翻译的词的正确语法表征应来自源句,该源句已通过联合注意编码为 z。
Mis-matching Features
一种衡量双语专家模型先验的特征,p(tk|·) 服从类别数等于词汇量的类别分布,双语专家预训练后应使 (3) 的每个 p(tk|·) 的似然最大,当 tk 为 GT 时最大。如图1左上所示,对于最优模型如果 mk ≠ tk,应该使 p(mk|·) ≤ p(tk|·)。
令 lk 是 softmax 之前的 logits 向量,p(tk|·)〜Categorical(softmax(lk)),将4维 mis-match 特征定义为:
![]()
其中,mk 表示翻译输出中的第k个词的 id,i^k_max = arg max xi lk 是双语专家预测的 id,空心的 I 是指示函数,这四个值将直接反映差异或错误。 如果机器翻译与双语专家预测相符,则 f^mm_k 的前两个元素应该相同,而代表软/硬差异的最后两个元素都应为0。
Bi-LSTM Quality Estimation
质量评估任务使用双向 LSTM(Bi-LSTM-CRF 的性能不比香草 Bi-LSTM 更好;传统编码器的自注意力或前/后向自注意力不能替代 Bi-LSTM,结果更糟,可能的原因是带标记的质量评估数据的数量级无法与大量的平行语料相比)。
沿深度方向的所有序列特征相连接以获得单个向量,表示为 {fk}^T_k=1,其中 T 是 m 中的词数。将句子级分数 HTER 预测视为回归问题(9),将单词标签预测视为序列标记问题(10):
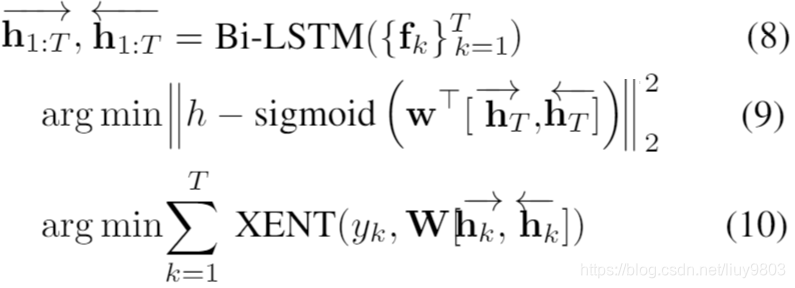
其中,w 是一个向量,W 是一个矩阵,yk 是翻译输出第 k 个词的标签,XENT 是交叉熵损失,HTER 是区间 [0,1] 上的实数,由于 HTER 是句子的整体评分,因此将前/后向 LSTM 中最后一个时间步的隐状态作为回归信号。可以使用多任务一起训练这两个损失,详见算法1。

Experiments
Setting Description
双语专家模型的训练数据有:(i) WMT17/18 新闻机器翻译任务平行语料,(ii) WMT17/18 生物医学翻译任务的 UFAL 医疗语料和 Khresmoi 数据,(iii) WMT17/18 QETask src-pe pairs。为确保语料库的质量,过滤数据保留长度≤70且长度比在1/3至3的源句和目标句,得到约900万(2017)和2500万(2018) 的英↔德平行句子对。对 WMT17 QE 语料分词,用于单词级 QE 任务;对 WMT18 语料应用字节对编码 BPE 以减少未知词数,但单词标标签预测与 BPE 之间存在差异,下一部分介绍如何弥合差距。在 CWMT 2018 中英句子 QE 任务上测试模型,由于这两种语言是不相关的,因此分别分词。双向 Transformer 层数为2,前馈子层的隐单元数为512,8头自注意。在8个 Nvidia P-100 GPU上训练双语专家模型约3天直至收敛,QE 模型为一层 Bi-LSTM,在单个 GPU 上训练。
使用 WMT17/18 的测试数据和 CWMT 2018 的验证数据评估算法,对于 WMT17 QE 任务,注意不能使用任何2018的数据,因为2018的训练数据包含2017的一些测试数据。相同的设置适用于所有以下实验。
Sentence Level Scoring And Ranking
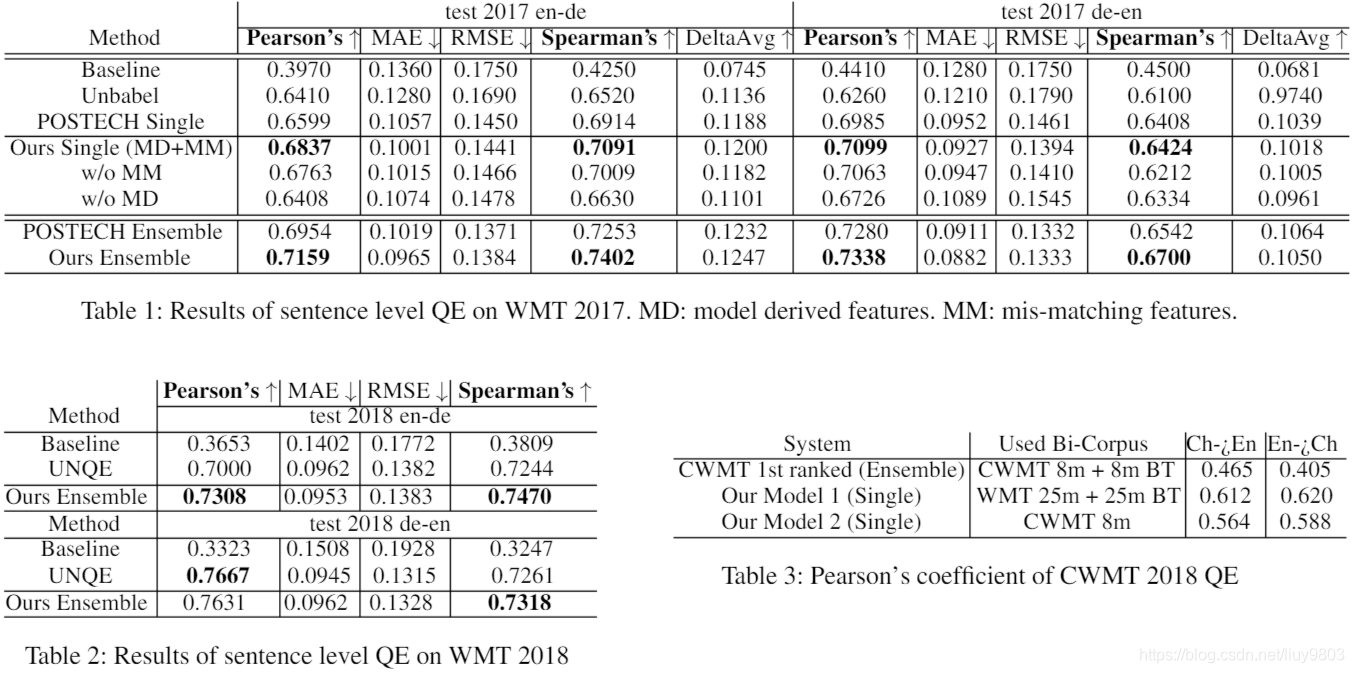
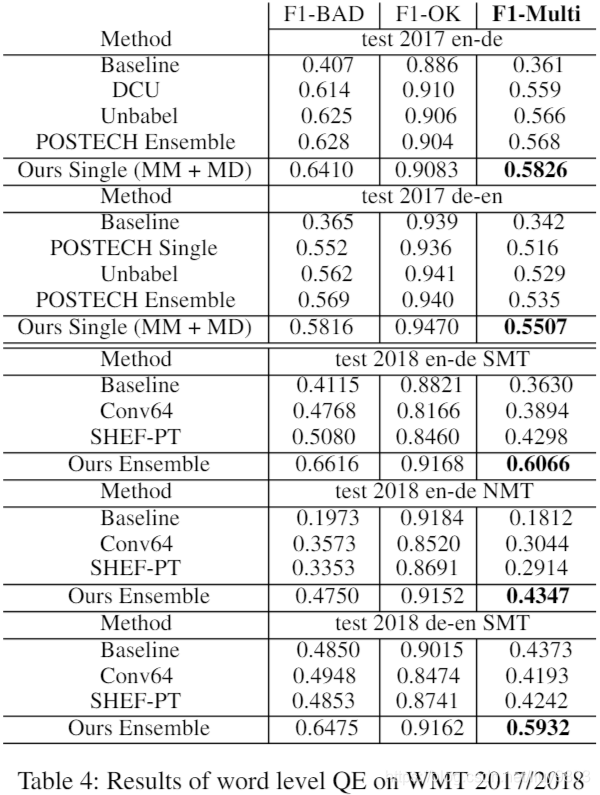
表1中为 WMT17 句子级结果,单一模型在决赛中排名前三。Unbabel 是特征丰富的序列线性模型与神经网络的组合,POSTECH 是 Bi-GRU 的预测器-估计器模型,基准是官方提供的系统。句子级任务的主要指标是测试集的皮尔逊相关性和斯皮尔曼排名相关性,MAE、RMSE、 DeltaAvg 也可以衡量总体预测性能,但不能作为QE任务的排名参考。集成模型可以在两个主要指标方面胜过所有其他系统。消融研究表明了 model derived 特征 (MD) 和 mis-matching 特征 (MM) 的重要性,仅靠4维 mis-match 特征,模型仍可以实现与去年第二个单一系统相当或更好的性能,证明了低维特征也可以提供强大的预测信号。中英的结果见表3,BT 表示反向翻译,没有反向翻译的单一模型在比赛中胜过了最好的系统。
Word Level For Word Tagging
单词级指标是将 OK 和 BAD 分类的F1值,结果见表4,基线由官方提供,还比较了 WMT17 QE任务中排名前三的算法,POSTECH、Unbabel 和 DCU,DCU 是词级 QE 和 APE 协同的堆叠神经模型。作者单个模型的 F1-Multi 优于所有其他模型,包括 WMT17 中最好的集成系统,在 WMT18 单词级 QE 任务中也比其他算法明显更好。
由于标签非常不平衡,算法通常会将单词标签归类为 OK,因此分类时使用阈值调整策略。
Word Level For Gap Tagging
间隙级预测也很重要,在句子的每个词之后和句子开头,放一个 gap 标签,gap 标签总数为 T+1,将(10)修改为:
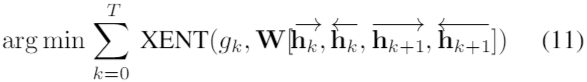
其中 gk 是第k个与第k + 1个词之间的 gap 标签,可以训练双语专家模型进行间隙预测,从而为下游任务提取更具代表性的特征。有以下分解模型 p(t, t^g|z) = p(t|z) p(t^g|z) 和 q(z|s, m),其中 p(t|z) 是先前讨论过的模型,间隙预测分布 p(t^g|z) = ∏_k p(t^g_k |→zk, ←zk, →zk+1, ←zk+1)。为 gap 预测定义一个 <blank> 标记,意味着不需要插入任何内容,这就产生了一个副产品–自动后编辑,大多数计算机辅助翻译方案都会使用质量评估模型,作为 APE 的校正指南或最终翻译输出的选择器。尽管 QE 可以起到 APE 的辅助作用,但它们从根本上被视为两个独立的任务。
对双语模型预训练以进行间隙预测后,将 MD 和 MM 提供给 Bi-LSTM 用于间隙估计,统一了质量估计和自动后编辑的方向。首先,表5左侧为间隙质量估计结果,右侧为经过预训练的 APE 结果示例。

Extending to BPE Tokenization
在许多 NMT 系统中,使用 BPE 或子词单元是一种处理稀有词的有效方法,尤其是在德语中,有一堆复合词,它们只是两个或两个以上的词的组合,这些词起着单一含义的作用,例如德语“handschuh”指手套,从字面上看是“hand shoe”。 BPE 在单个字符的灵活性和完整单词的解码效率之间取得了良好的平衡,避免了对未知单词特殊处理的需要。
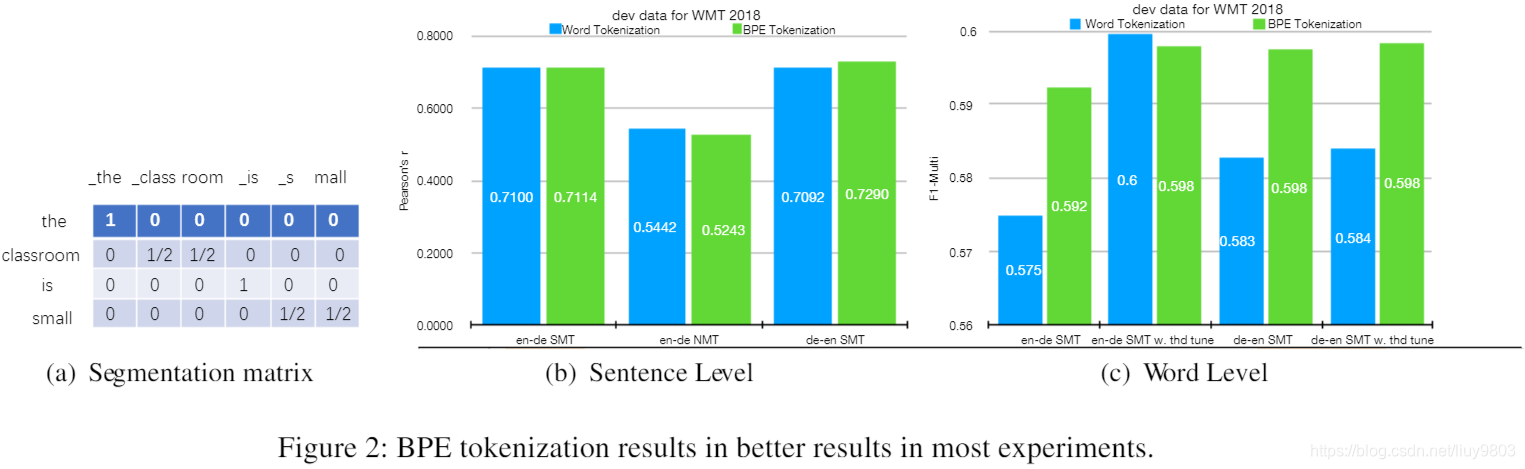
对于句子级 HTER 预测,使用 BPE 不会造成危害或冲突,因为回归只关心最后一个时间步的隐藏状态;但是对于单词级预测,BPE 分词的序列特征 Lb 的长度与单词数量 Lw 不同。建议对属于一个单词的所有子单词单元的特征求平均,类似于沿时间轴的具有动态大小的平均池化。为了使计算图可区分,需要将 BPE 分段信息存储到一个 Lw×Lb 的稀疏矩阵 S 中,如果第 j 个子词单元属于第 i 个词,则 Sij ≠ 0,见图2(a)。
在句子和单词级上比较单词和 BPE 分词的性能,并将结果绘制为直方图,如图2(b, c) 所示。与NMT系统类似,细粒度的 BPE 分词可以提高大多数任务的 QE 性能。句子级 BPE en-de NMT 的皮尔逊分数较低,这很可能是由于数据量较小 (<14000);词级如果使用默认阈值0.5,则 BPE 较好,阈值调整后,BPE 的改进程度可能较小(使用验证集调整阈值并评估,因为没有测试集的 GT)。实际上,可以在 QE 训练时联合训练这两个模型:预处理为单词或 BPE 分词,如果在分段矩阵中添加适当的列和行填充,BPE 也可以在训练 Bi-LSTM 时反向传播以更新双语专家模型,这留作以后的工作 。
Conclusion
提出一种新的估计机器翻译系统质量的方法,使用“双语专家”作为先验知识模型,然后对提取的模型特征及手动设计的 mis-match 特征使用 Bi-LSTM 作为质量估计模型,在 WMT17/18 QE 数据集上比其他算法性能更好。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









