







Log-linear Combinations of Monolingual and Bilingual Neural Machine Translation Models for Automatic Post-Editing
https://arxiv.org/pdf/1605.04800.pdf
本文介绍了AMU (Adam Mickiewicz University) 团队提交的 WMT 2016 自动后编辑 APE 任务,探索神经翻译模型在 APE 中的应用,使用不同的模型作为对数线性模型的组成部分,将多个输入 (MT-output 和 source) 解码为相同的目标语言 (post-edited translations),从而获得良好的结果。对数线性模型中集成一个简单的字符串匹配惩罚,用于使原始机器翻译输出的可靠性更高。为了克服训练数据太少的问题,生成大量的人工数据。最终提交比基准 TER-3.2%、BLEU+5.5%。
1 Introduction
APE 任务是黑盒纠正未知机器翻译系统错误的方法,评估部分使用 TER 和 BLEU、部分使用人工。神经翻译模型用于 APE 任务的效果良好:
• 创建可用于训练神经模型的 PE 数据;
• 将单语和双语模型进行对数线性集成;
• 在对数线性模型中增加了特定于任务的特征,控制 APE 输出与输入之间的一致性。
2 Related work
2.1 Post-Editing
以前的 APE 系统使用 mt 和 pe 对 phrase-based SMT 系统进行训练,这种方法的变体“source-context aware”进行单词对齐用于创建新的源(由 mt 和 src 词对组成),可以提高 APE 效果。
PB-SMT-based APE 系统的改进,例如 phrase-table filtering 和 specialized features;a pipeline,通过特定于任务的密集特征选择最佳语言模型和修剪短语表,克服了数据稀疏的问题;Abu-MaTran 在后处理时结合句子级分类器,在给定的 mt 和 PB-SMT APE 的 pe 之间进行选择,使用单词级 Seq2Seq 分类器将句子中的每个单词标记为“good”或“bad”,选择 bad 词数较少的作为最终的 pe。
2.2 Neural machine translation
注意力模型观察源句中任何位置的单词状态,容易学习何时进行复制,这对 APE 很重要。
3 Data and data preparation
3.1 Used corpora
APE 任务使用的数据:
(1)官方提供的训练/验证数据,包括12000/1000个三元组;
(2)WMT-16 IT 领域翻译任务的 en-de 双语训练数据;
(3)WMT-16 新闻翻译任务的 en-de 平行双语数据;
(4)WMT-16 新闻和 IT 翻译任务的德语单语通用语料库。
3.2 Pre- and post-processing
三元组使用 Moses tokenizer 分词,转义特殊字符,使用字节对编码 BPE 将词分为子词单元,可以有效地将未知单词的数量减少到零,该方法可以处理德语复合名词(免去了使用特殊方法处理)以及俄语-英语的音译。避免神经模型遇到未知词时产生的“幻觉”输出,忠实的音译更可取。
4 Artificial post-editing data
由于提供的 pe 数据量太小,无法训练神经模型,很快就过拟合。因此使用 back-translated 单语数据来丰富双语训练语料库。
4.1 Bootstrapping monolingual data
将 cross-entropy filtering 用于德语常用语料库:
• 过滤语料库,保留格式良好的行——大写 Unicode 字符开头,句子末尾有结束标点,至少包含30个 Unicode 字符;
• 语料库按上述方法进行预处理,可以对未知单词打分;
• 使用德语 pe 和 IT-task 数据建立域内三元语言模型 (Heafield et al., 2013),并使用常用的抓取数据建立一个类似大小的域外语言模型;
• 使用两种语言模型计算语料库前10亿行的交叉熵;
• 按照交叉熵对语料库升序排序,保留前1000万用于 round-trip 翻译,前1亿用于语言模型。
4.2 Round-trip translation
使用 IT 任务可接受的平行训练数据,创建两个基于短语的翻译模型 en-de、de-en,使用 fast-align 对齐单词,使用 dynamic-suffix array (Germann, 2015) 保存翻译模型。前10%的自举单语数据用于 en-de 建模,对于 de-en 仅用平行域内语料库的目标端构建。前1%的自举数据首先从德语翻译成英语,然后从英语翻译回德语,中间的英语翻译要被保留。为了快速翻译这1000万个句子两次,使用 small stack-size 和约100的 cube-pruning-pop-limits,在约24小时内完成了 roundtrip 翻译。这个过程生成了1000万个人工后编辑的三元组,其中 de src 作为 pe,de→en 翻译作为 en src,roundtrip 翻译作为 mt。
4.3 Filtering for TER
希望 roundtrip 翻译过程产生的字面翻译或多或少类似于 pe 三元组,其中 mt 和 pe 之间的距离通常小于 mt 和同一 src 的人工翻译之间的距离。有了这么多可用的数据后,尝试模拟 APE 训练语料的 TER 继续进行过滤,虽然 TER 只考虑了三元组中两个德语的部分,但是过滤出更好的 de-de 对会产生更高质量的中间英语。为了实现这一点,将 APE 训练数据中的每一个三元组表示为计算 mt 和 pe 的基本 TER 统计量的向量,例如句子长度、编辑频率和句子级 TER 分数,对待过滤的人工三元组语料也做同样的处理,相似性度量是这些向量的逆欧氏距离。
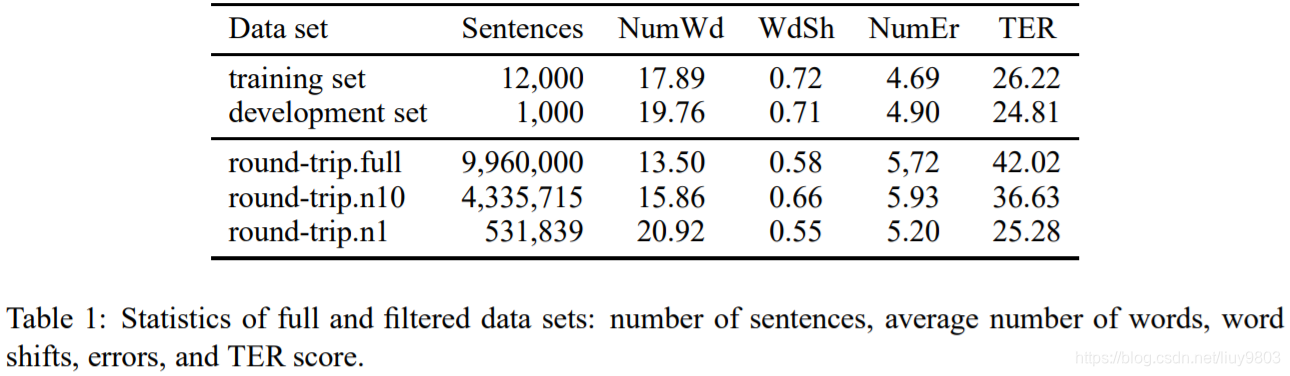
第一步,将偏离任何参考向量最大或最小值超过10%的离群点移除,例如,过滤三元组中 pe 比参考最长 pe 句子长10%的个体;第二步,对参考中每个三元组,选择n个最近邻,选定的三元组从集合中排除,如果需要遍历超过100个三元组,则选择少于n甚至0个候选。表1为所获得的语料库与提供的训练/验证数据,令 n = 1、10,较小的一组 (round-trip.n1) 与提供的训练/验证数据的 TER 非常接近,但仅占 full 的5%;较大的一组 (round-trip.n10) 包含约43%的数据,但 TER 得分较低。
5 Experiments
根据 post-editing-by-machine-translation ,研究软注意神经翻译模型在 pe 中的应用,NMT 使用 Nematus 训练的注意力编码解码器模型,batch size 为80、最大句子长度为50、词向量500维、隐藏层大小为1024,优化器为 Adadelta,每个 epoch 后打乱语料库,单词被分成子单词单元,每种语言40000个。解码时使用 Nematus 训练的 AmuNMT,beam 大小为12、长度归一化。
5.1 MT-output to post-editing
使用 round-trip.n10 的 mt 和 pe 训练单语 MT-PE 模型4天,每10000步保存一次,模型快速收敛,在30万次迭代后,使用提供的训练数据和较小的 round-trip.n1 微调。原始 pe 数据上采样20倍,并与 round-trip.n1 合并,这导致了图1中性能的跳跃 (蓝色的 mt→pe),再进行100000次迭代,明显过拟合时停止训练。如果直接使用较小的训练数据,不用 round-trip.n10 会更早出现过拟合。
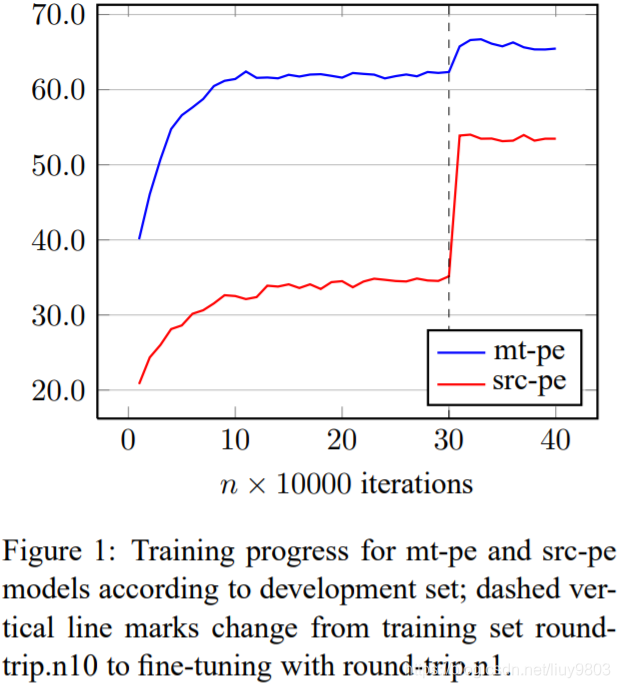
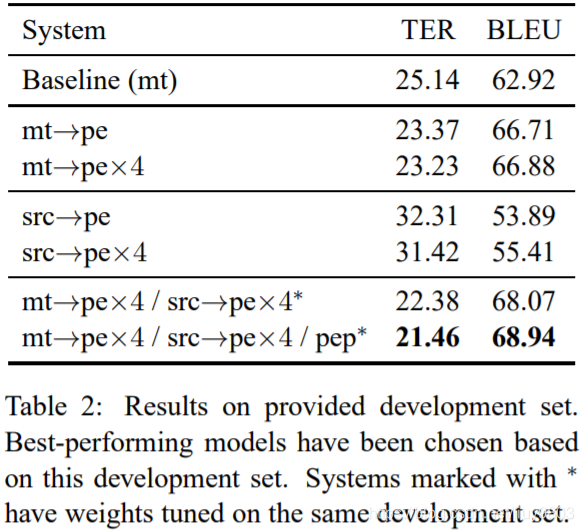
表2中的 mt→pe 是验证集上单个模型最佳的结果,显著优于基准。由四个最佳模型集成的 mt→pe×4 仅比单个模型略微提升(使用同一验证集选择最佳模型,结果可能略有偏差)。
5.2 Source to post-editing
对 en-de NMT 进行类似的处理,当使用较小语料库上采样 pe 进行微调时,还添加 IT-task 的所有域内平行训练数据,大约200,000个句子。结果比单语有更大的跳跃,但整体性能弱于它。同样评估单个最佳 src→pe 和集成模型 src→pe×4,集成好于单个,但效果仍弱于基准。
5.3 Log-linear combinations and tuning
只要目标语言词汇表是相同的,AmuNMT 可以接受集成的不同模型的不同输入,因此可以构建一个解码器,将德文 mt 和英文 src 作为平行输入,输出德文 pe。一旦输入语句被提供给一个NMT模型,它本质上就变成了一个语言模型,理论上,可以以这种方式组合无限数量的输入,而不需要专门的多输入训练程序。在集成的 NMT 中,同质模型的权重通常相等,这里异质模型的权重不能相等,因此,将每个模型视为传统对数线性模型中的一个特征,使用 Batch Mira 将权重作为参数进行调整 (Cherry and Foster, 2012)。AmuNMT 可以产生与 Moses 兼容的 n-best 列表,类似 Moses 的迭代优化。使用验证集调整权重以得到较低的 TER,两次迭代似乎就足够了。集成单个 mt→pe 和 src→pe 模型时,权重约为0.8和0.2;8个模型的线性组合 mt→pe×4 / src→pe×4 提高了性能(TER -0.9,BLEU +1.2,但权重是用同一数据进行调整的。
5.4 Enforcing faithfulness
使用简单的 Post-Editing Penalty (PEP) 扩展AmuNMT。为了确保校正时不会引入过多的新内容,对输出中没有出现在输入的每个单词惩罚。解码实现时的矩阵维数:batch size × 目标词汇表大小,与源单词匹配的所有列赋0,其他的单词为 -1,然后可以像使用另一个集成模型一样使用这个特性,并使用与之前描述的相同的过程进行调优。
PEP 在解码过程中引入 precision-like bias,使用字符串匹配强制输入具有一定的可靠性。类似的 recall-like bias(对输出中缺少输入单词的惩罚)在解码时无法实现,因为直到解码的最后才知道哪些单词被忽略了,这只能作为一个最终的重新排序的标准,没有在本文中探讨。词袋法赋予了 NMT 模型在重排序和流畅性方面的最大自由,而这些模型似乎天生就很适合这种情况。与之前一样,使用验证集调优后,得到的系统(mt→pe×4 / src→pe×4 / pep)可以再次提高 pe 质量,比 MT 基线性能提高了-3.7% TER 和+6.0% BLEU;与单语集成相比,不同特征的对数线性组合提高了-1.8% TER 和+2.1% BLEU。
6 Final results and conclusions
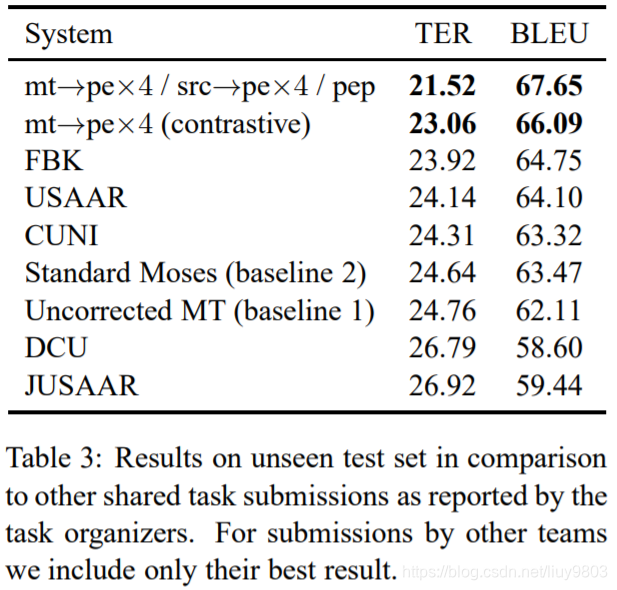
APE 共享任务的最终提交为 mt→pe×4 / src→pe×4 / pep,使用 mt→pe×4 作为对比系统。表3为各种系统的结果,按 TER 从好到差排序。作者最好的系统比 baseline 1提高了-3.2% TER 和+5.5% BLEU,对比系统也提高了-1.5% TER 和+1.5% BLEU。比赛组织者还提供了一个基于标准短语的Moses (baseline 2) 的结果,比 baseline 1 稍差 (-0.1% TER,+1.4% BLEU)。
总结如下:
• NMT 模型可以用于 APE;
• 人工 APE 三元组有助于防止早期过拟合,克服训练数据太少的问题;
• 不同输入语言的 NMT 模型的对数线性组合,可以作为 mt 与 src 结合的方法,使 APE 产生积极的效果;
• 特定任务的特征可以很容易地集成到对数线性模型中,并且可以控制APE结果的可靠性。
未来的工作:调查集成的 multi-source 方法 (Zoph and Knight, 2016) 和更好的过拟合处理方法。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









