







ZooKeeper为存储的数据提供了一致性保证,不管应用从哪个服务端获取数据,都能获取到一致的数据。ZooKeeper内部使用原子广播协议(Zab)作为其一致性复制的核心,并通过对服务端请求的排序达到数据一致性的保障要求。
ZooKeeper的数据一致性保障
ZooKeeper是高性能、可扩展的,为应用提供了以下的数据一致性保障:
1)顺序一致性
来自客户端的更新将严格按照客户端发送的顺序处理;
2)原子性
更新或者成功或者失败,不存在部分成功或者部分失败的场景;
3)单一视图
无论客户端连接到哪个服务器,看到的都是一样的视图;
4)可靠性
一旦一个更新生效,它将一直保留,直到再次更新;
5)实时性
在特定的一段时间内,任何系统的改变都能被客户端看到,或者被监听到。
Zab:原子广播协议
在ZooKeeper的集群环境中,有leader、follower和observer节点,leader负责将写操作包装为一个事务执行,follower参与写操作执行过程的投票,而observer则仅接收最后的INFORM消息,不参与更新的投票过程。
当follower收到一个写请求时,follower将其转交给leader,leader将其封装为一个事务并处理,每个事务都包含了一个zxid,zxid分为两个部分,epoch和counter。epoch用于标识当前的leader,一个新的leader产生,epoch加1;不同的epoch代表了不同的leader;counter用于事务的计数(详见”ZooKeeper集群管理“)。事务包含了更新操作所需要的所有信息。
Zab协议的交互过程如下:
1)leader发送一个PROPOSAL消息p给所有follower;
2)follower回送一个ACK给leader,表示接收PROPOSAL,follower将ACK信息持久化;
3)当收到大多数(包括leader自身)follower回复的ACK后,leader发送一个消息通知所有follower COMMIT。
follower在确认PROPOSAL之前,需要检查proposal确实来自于他所跟随的leader,方法是判断proposal的zxid的epoch部分是否和当前leader的epoch一致;并且检查确认和提交proposal的顺序和leader广播的顺序是否一致。
Zab保障了:
1)如果leader先后广播了T和T’,每个server都必须按T、T’的顺序提交;
2)如果任何一个server按T、T’的顺序提交了事务,那么所有server都必须按T、T’的顺序提交事务。
第一点保障了leader和server按相同顺序处理事务,而第二点保障了所有server都不会遗漏事务。
由于无法保障leader一直正常运转,因此需要考虑到leader异常后的情况。当leader异常后,将会触发leader的重新选择(详见”ZooKeeper集群管理“),新选择的leader必须满足:
1)新leader在广播消息之前,需要先提交完上一个leader发送的所有事物;
2)在任何时刻,都应该仅有一个leader拥有多数支持者。
Observer
因为observer不参与投票,因此不接收proposal,而commit消息中仅包含zxid,因此observer使用新的消息INFORM,INFORM中包含proposal的内容和提交事务的通知。
服务端处理流程
ZooKeeper包含多种类型的服务端,leader、follower和observer,下面介绍每种服务端对消息的处理流程。
leader
leader的处理流程如下:

1)PrepRequestProcessor:接收请求并将其封装为一个事务;
2)ProposalRequestProcessor:将事务封装为proposal,并广播给follower;ProposalRequestProcessor会前转所有的请求给CommitRequestProcessor,并前转所有写请求到SyncRequestProcessor;
3)SyncRequestProcessor:持久化事务,并将消息交由AckRequestProcessor处理;
4)AckRequestProcessor:产生一个确认并转交给自己;
5)CommitRequestProcessor:等待收到足够的确认(超过一半)后,提交proposal;
6)ToBeAppliedRequestProcessor:获取等待处理的请求,并交给FinalRequestProcessor处理;
7)FinalRequestProcessor:执行请求,包括写请求和读请求。
在持久化事务时,ZooKeeper为了加快持久化的效率,使用了:
1)一次存储多个事务,减少磁盘I/O;
2)为文件预分配磁盘块。
follower
follower需要接收3中不同的消息:客户端请求、proposal和commit。
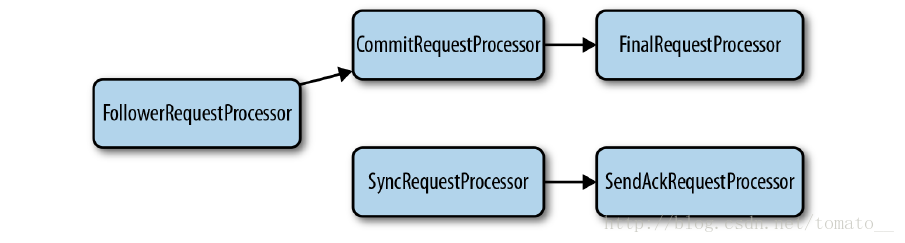
1)FollowerRequestProcessor:接收和处理客户端请求,前转所有请求到CommitRequestProcessor,并前转写请求到leader;
2)CommitRequestProcessor:直接将读请求交由FinalRequestProcessor处理,而对于写请求,等待leader的commit通知;当收到commit通知后,将写请求交给
3)SyncRequestProcessor:接收来自leader的proposal,持久化事务,并将其交给SendAckRequestProcessor;
4)SendAckRequestProcessor:向leader发送确认消息;
5)FinalRequestProcessor:执行请求,包括写请求和读请求。
observer
observer的处理方式和follower是类似的,observer不参与确认proposal,因此比起follower,缺少了发送确认消息到leader和持久化事务的流程。
请求的按序处理
ZooKeeper服务端需要保证请求的按序处理,在ZooKeeper的服务端收到一个请求后,会将其放到一个队列中,包括读请求和写请求,然后按序处理。对于读请求,当前服务端直接处理并返回结果(参考上面介绍的服务端流程);而对于写请求,当前服务端会等待直到该写请求处理完成,才继续处理下一个请求,通过该等待机制,ZooKeeper保证了请求的按序处理。
快照
ZooKeeper的每个服务端都频繁地序列化整个数据到文件来生成快照,快照包含最后处理的事务的zxid,当服务端重启后,服务端可以获取该快照,并根据最后处理的事务的zxid从leader获取到增量的事务并处理,就可以达到最新的状态。
服务端生成快照的流程为:
1)记录当前最后处理的事务的zxid;
2)将服务端的整个信息逐步序列化并持久化到文件中。
在持久化的过程中,服务端并不会停止消息的处理,因此可能出现记录的最后处理的zxid并不一定真正是最后处理的事务。例如,假定存在两个znode节点/z和/z1,假定初始/z和/z1的数据都为1,现在按一下步骤生成快照:
1)获取最后处理的事务t0;
2)序列化/z的数据1到快照;
3)设置/z的数据为2(事务t1);
4)设置/z1的数据为2(事务t2);
5)序列化/z1的数据2到快照。
这样,最终的快照是:最后处理的事务t0,/z的数据为1,/z1的数据为2.
然而这样并不会导致问题,当该快照被重新使用时,事务t1和t2都会被重新执行,由于ZooKeeper要求所有的事务都是幂等的,即按序多次重复处理一批事务会得到同样的结果,因此服务端仍然会得到正确的数据。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









