







在创建索引库的基础上,加上中文分词器的,更好的支持中文的查询。引入jar包je-analysis-1.5.3.jar,极易分词.还是先看目录。
建立一个分词器的包,analyzer,准备一个AnalyzerTest的类.里面的代码如下,主要写了一个testAnalyzer的方法,测试多种分词器对于中文和英文的分词;为了可以看到效果,所以写了个analyze()的方法,将分词器和text文本内容传入,并将分词的效果显示出来.
package com.lucene.analyzer;
import java.io.StringReader;
import jeasy.analysis.MMAnalyzer;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.SimpleAnalyzer;
import org.apache.lucene.analysis.Token;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.cjk.CJKAnalyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.junit.Test;
/**
* 对分词器的效果进行测试
* @author liu
*
*/
public class AnalyzerTest {
String enText = "IndexWriter addDocument's a javadoc.txt";
String cnText = "我们是中国人";
//单字分词
Analyzer analyzerStanderd = new StandardAnalyzer();
//按停用词分词
Analyzer analyzerSimple = new SimpleAnalyzer();
//二分法分词
Analyzer analyzerCJK = new CJKAnalyzer();
//词库分词
Analyzer analyzerMM = new MMAnalyzer();
/**
* 测试各种分词器的分词效果
* @throws Exception
*/
@Test
public void testAnalyzer() throws Exception {
//英文分词
analyze(analyzerStanderd,enText);
analyze(analyzerSimple,enText);
analyze(analyzerCJK,enText);
analyze(analyzerMM,enText);
//中文分词
analyze(analyzerStanderd,cnText);
analyze(analyzerSimple,cnText);
analyze(analyzerCJK,cnText);
analyze(analyzerMM,cnText);
}
/**
* 将text文本内容进行分词,并将结果打印出来
* @param analyzer 分词器
* @param text 分词的文本
* @throws Exception
*/
public void analyze(Analyzer analyzer,String text) throws Exception {
System.out.println("-----------分词器:"+analyzer.getClass());
//分词器将text文本的内容分词,并打印出来
TokenStream tokensStream = analyzer.tokenStream("content",new StringReader(text));
for(Token token=new Token();(token=tokensStream.next(token)) !=null;) {
System.out.println(token);
}
}
}
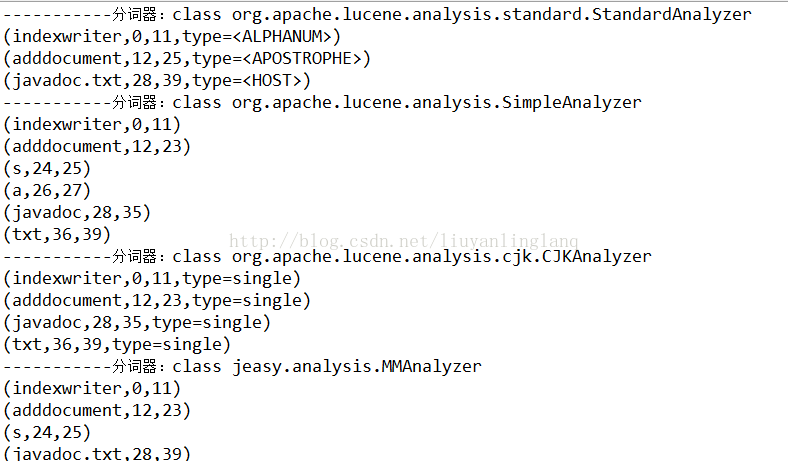
执行方法testAnalyzer, 运行效果如下.先看英文的分词的执行效果。对于标准分词器,分词的效果是将词进行了词根还原,并且全部转为小写,所以没有了adddocument's,只有adddocument.而简单分词器根据效果可以理解为根据标点符号来分割,而且只是分割.下面的CJK分词器和极易分词器主要对于中文进行分词,当然分英文也是可以的.
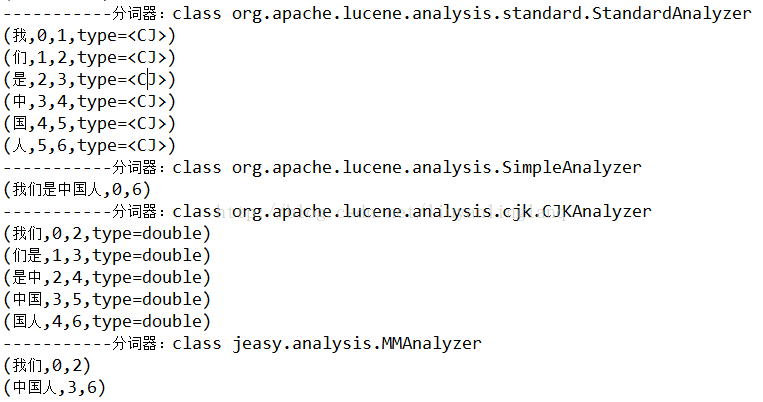
这是中文的分词效果.standardAnalyzer是单个分词,一个一个分;而simpleAnalyzer因为没有找到标点符号,分割不了;CJKAnalyzer则是二分法,将所有的都两两结合;MMAnalyzer极易分词则效果很好,根据中文的词分成了2个.
以上就是StandardAnalyzer,SimpleAnalyzer,CJKAnalyzer和MManalyzer的分词效果的显示.通过这段代码,可以测试更多的分词器的效果.下一篇是补充索引的功能的,之前直接了创建和查询,修改和删除没有介绍.所以,下一篇《全文检索之lucene的优化篇--增删改查》。















 4616
4616

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









