






这是OA第4天学习内容的总结,这个是写于3月4号的,所以有部分内容刚刚第三天的19号写的,里面已经介绍了。
第四天的内容是从28集到34集,先是讲了处理3个细节的问题.1.回到上一级,2.删除/修改/添加之后回到当前页面,而不是顶级页面;还有懒加载问题的解决,通过配置OpenSessionInViewFilter达到Session在Service之后不关闭,而是在结束Filter或者Interceptor之后再结束.
还有就是添加/修改页面的部门的树形结构的选择,使用了递归的方式来生成树,并且设置了树的排序方式.
以及在多次写Action之后,抽取BaseAction,将继承ActionSupport和实现ModelDriven都交由BaseAction来处理,当前getModel也通过泛型和反射来处理了.而使用的各种Service也在BaseAction中声明,因为Service本身就是单例的,所以只要在BaseAction中实例过一次,继承BaseAction的子类就不用再实例化了.
并且,同样理由,整理了页面,将导入js和css样式和引入标签都抽取放在了公共片段文件中,用的时候只需要将该.jspf片段文件导入.
其中,将介绍各个点的内容.

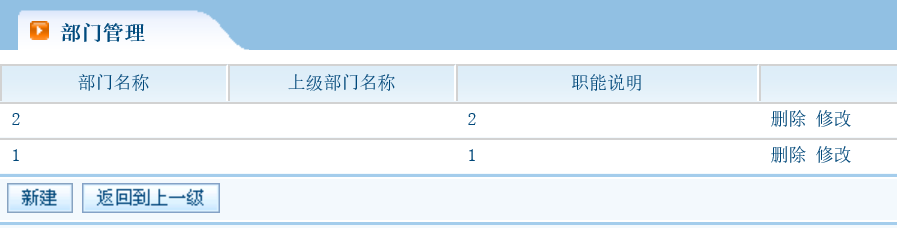
从第二级 点击返回上一级到顶级部门
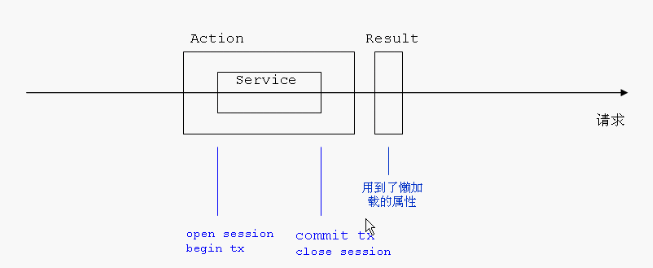
图像表示就是上图,在Action中需要调用Service,在Service中会开启和关闭Session,并会返回一个Result,而对于带有懒加载功能的Result,若在页面上使用,此时session已经关闭,则访问异常.所以只要session的不关闭,问题就可以解决了.当然去掉懒加载问题也可以解决,只是懒加载在提高性能方面有很好的效果,关掉实在可惜。
解决的图像就是,将session的关闭延迟到Filter或者是Interceptor结束之后再关闭.
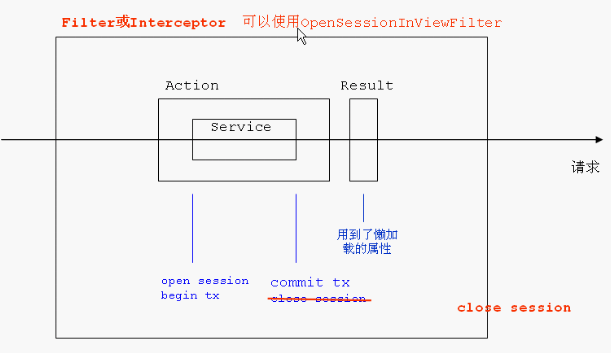
OpenSessionInViewFilter的处理,就是在web.xml文件中配置一个过滤器,就可以实现了.只是要注意这个filter一定要在struts2的过滤器前面.
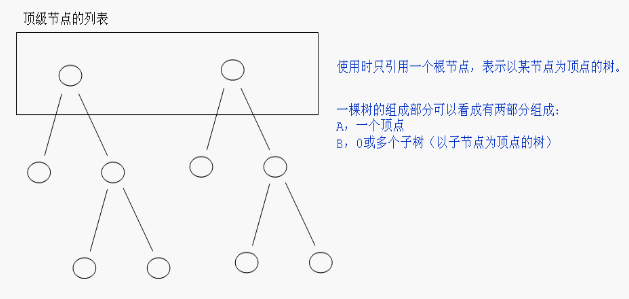
如需按照层次打印各个节点的名称.就可以将根节点传入,然后先打印根节点的名称,再用getChildren获取根节点的0个或多个子节点,遍历各个子节点,可以再来一遍,将子节点传入,打印子节点的名称,在获取子子节点.
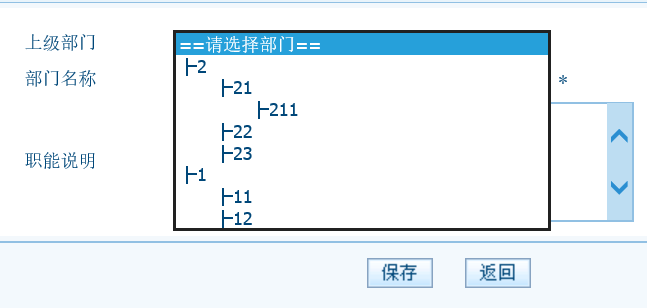
其中显示的代码是这样的,接收到回显的部门列表数据,id作为key,name作为value显示到下拉框中。
并且由于department的getChildren()的结果类型是Set类型,是无序的,所以在显示下级部门的时候,顺序是不定的.不过,只要在实体的配置文件中,加上order-by属性就可以解决了 .
代码就是如下,主要就是需要使用泛型,在BaseAction的构造函数中,通过反射创建model的实例.
先是获取this也就是BaseAction的子类,如DepartmentAction的对象,getClass().getGenerisSuperClass()获取DepartmentAction传入的泛型的参数类型,其中对于实体来说参数只有1个,对于键值对key,value,参数有两个.所以这里只需要取第一个参数的类型,就是泛型实体的真正类型.
第四天的内容是从28集到34集,先是讲了处理3个细节的问题.1.回到上一级,2.删除/修改/添加之后回到当前页面,而不是顶级页面;还有懒加载问题的解决,通过配置OpenSessionInViewFilter达到Session在Service之后不关闭,而是在结束Filter或者Interceptor之后再结束.
还有就是添加/修改页面的部门的树形结构的选择,使用了递归的方式来生成树,并且设置了树的排序方式.
以及在多次写Action之后,抽取BaseAction,将继承ActionSupport和实现ModelDriven都交由BaseAction来处理,当前getModel也通过泛型和反射来处理了.而使用的各种Service也在BaseAction中声明,因为Service本身就是单例的,所以只要在BaseAction中实例过一次,继承BaseAction的子类就不用再实例化了.
并且,同样理由,整理了页面,将导入js和css样式和引入标签都抽取放在了公共片段文件中,用的时候只需要将该.jspf片段文件导入.
其中,将介绍各个点的内容.
回到上一级
这个代码很简单,只需要在页面上添加一段链接的html语句就可以了.在list.jsp页面中,添加这一段,其中图片内容就是"返回到上一级",并且需要带上参数parentId作为参数,他是上级部门的上级部门的id.就是当在第三级部门,返回到上一级,也就是第二级部门,而第二级部门的parentId就是第一级部门的id.<s:a action="department_list?parentId=%{#parent.parent.id}"><img src="${pageContext.request.contextPath}/style/blue/images/button/ReturnToPrevLevel.png"/></s:a>下面是代码分析:
点击该图片的时候,会根据action到struts.xml配置的action中来处理,department_list,对应的method为list.所以去执行list方法.<!-- 部门管理 -->
<action name="department_*" class="departmentAction" method="{1}">
<result name="list">/WEB-INF/jsp/departmentAction/list.jsp</result>
<result name="saveUI">/WEB-INF/jsp/departmentAction/saveUI.jsp</result>
<result name="toList" type="redirectAction">department_list?parentId=${parentId}</result>
</action>private Long parentId;
/**
* 列表
* @return
* @throws Exception
*/
public String list() throws Exception {
//回显到前台的部门列表
List<Department> departmentList = null;
//根据传递上级部门id是否为空,查询所有顶级部门还是该上级部门的所有子部门.
if(parentId == null) {
departmentList = departmentService.findTopList();
}else {
departmentList = departmentService.findChildren(parentId);
//根据该Id,获取上级部门对象,并设置到值栈的map中.
Department parent = departmentService.getById(parentId);
ActionContext.getContext().put("parent", parent);
}
//将部门列表页设置到map中,到前台回显
ActionContext.getContext().put("departmentList", departmentList);
return "list";
}
public Long getParentId() {
return parentId;
}
public void setParentId(Long parentId) {
this.parentId = parentId;
}从第二级 点击返回上一级到顶级部门
懒加载的问题OpenSessionInViewFilter
懒加载的问题原因是因为hibernate允许关联对象,而为了提高效率,所以默认这种都是带有延迟加载的.若Service层返回了一个启动了懒加载功能的对象给web层,当web层访问到那些需要延迟加载的数据时,由于Session 已经关闭了,所以没法在用hibernate的级联查询来获取值,导致延迟加载的数据访问异常.图像表示就是上图,在Action中需要调用Service,在Service中会开启和关闭Session,并会返回一个Result,而对于带有懒加载功能的Result,若在页面上使用,此时session已经关闭,则访问异常.所以只要session的不关闭,问题就可以解决了.当然去掉懒加载问题也可以解决,只是懒加载在提高性能方面有很好的效果,关掉实在可惜。
解决的图像就是,将session的关闭延迟到Filter或者是Interceptor结束之后再关闭.
OpenSessionInViewFilter的处理,就是在web.xml文件中配置一个过滤器,就可以实现了.只是要注意这个filter一定要在struts2的过滤器前面.
<!-- 配置spring的用于解决懒加载问题的过滤器 -->
<filter>
<filter-name>OpenSessionInViewFilter</filter-name>
<filter-class>org.springframework.orm.hibernate3.support.OpenSessionInViewFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>OpenSessionInViewFilter</filter-name>
<url-pattern>*.action</url-pattern>
</filter-mapping>递归的树形结构
递归,感觉就是不停的调用自己.而什么情况下,会用递归,我也挺晕的,不过据说树形结构中使用递归是很方便.如需按照层次打印各个节点的名称.就可以将根节点传入,然后先打印根节点的名称,再用getChildren获取根节点的0个或多个子节点,遍历各个子节点,可以再来一遍,将子节点传入,打印子节点的名称,在获取子子节点.
/**
* 显示一颗部门树中所有节点的信息
*
* @param top
* 树的顶点(根节点)
*/
private void showTree(Department top) {
// 顶点
System.out.println(top.getName());
// 子树
for (Department child : top.getChildren()) {
showTree(child);
}
}/**
* 显示多颗树的所有节点的信息
*
* @param topList
*/
private void showTreeList(Collection<Department> topList) {
for (Department top : topList) {
// 顶点
System.out.println(top.getName());
// 子树
showTreeList(top.getChildren());
}
}/**
* 练习二:打印所有顶层部门及其子孙部门的信息(名称),用不同的缩进表示层次(使用全角空格)。<br>
* 子部门的名称前比上级部门多一个空格,最顶层部门的名字前没有空格。 提示:假设有一个打印部门集合中所有部门信息的方法
*
* 要求打印如下效果:
*
* <pre>
* ┣市场部
* ┣宣传部
* ┣业务部
* ┣业务一部
* ┣业务二部
* ┣开发部
* ┣开发一部
* ┣开发二部
* </pre>
*/
@Test
public void printAllDepts_2() {
List<Department> topList = findTopLevelDepartmentList();
showTreeList_2(topList, "┣");
}
// 显示树
private void showTreeList_2(Collection<Department> topList, String prefix) {
for (Department top : topList) {
// 顶点
System.out.println(prefix + top.getName());
// 子树
showTreeList_2(top.getChildren(), " " + prefix);//全角字符
}
}其中显示的代码是这样的,接收到回显的部门列表数据,id作为key,name作为value显示到下拉框中。
<tr><td width="100">上级部门<br></td>
<td>
<s:select name="parentId" cssClass="SelectStyle"
list="#departmentList" listKey="id" listValue="name"
headerKey="" headerValue="==请选择部门=="/>
<br></td>
</tr>并且由于department的getChildren()的结果类型是Set类型,是无序的,所以在显示下级部门的时候,顺序是不定的.不过,只要在实体的配置文件中,加上order-by属性就可以解决了 .
<!-- children属性,本类与Department(下级)的一对多 -->
<set name="children" cascade="delete" order-by="id ASC" >
<key column="parentId"></key>
<one-to-many class="Department"/>
</set>Hibernate: select children0_.parentId as parentId3_1_, children0_.id as id1_, children0_.id as id3_0_, children0_.name as name3_0_, children0_.description as descript3_3_0_, children0_.parentId as parentId3_0_ from itcast_department children0_ where children0_.parentId=? order by children0_.id asc抽取BaseAction
由于RoleAction和DepartmentAction,都需要继承ActionSupport和实现ModelDriven,并实现getModel方法,以及需要实例化相应的Service.Action虽然是多例的,并且Action中可以有1个或多个Service,但是Service并没有设置他们的scope是多例的,所以他们是单例的,只要在BaseAction中实例化一次,那么子类就可以用,完全可以做到公用.代码就是如下,主要就是需要使用泛型,在BaseAction的构造函数中,通过反射创建model的实例.
先是获取this也就是BaseAction的子类,如DepartmentAction的对象,getClass().getGenerisSuperClass()获取DepartmentAction传入的泛型的参数类型,其中对于实体来说参数只有1个,对于键值对key,value,参数有两个.所以这里只需要取第一个参数的类型,就是泛型实体的真正类型.
public abstract class BaseAction<T> extends ActionSupport implements ModelDriven<T> {
//=============Service实例的声明=============
@Resource
protected DepartmentService departmentService;
@Resource
protected RoleService roleService;
//=============ModelDrvien的支持=============
protected T model;
public BaseAction() {
//通过反射获取model的真实类型
//通过反射创建model的实例
try {
ParameterizedType pt = (ParameterizedType) this.getClass().getGenericSuperclass();
Class<T> clazz = (Class<T>)pt.getActualTypeArguments()[0];
model = clazz.newInstance();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public T getModel() {
return model;
}
}JS和CSS样式导入的公共代码抽取
由于每个页面都需要引入js脚本文件和css样式,以及taglib的标签,所以将他们提取出来放到一个公共的片段文件中,叫common.jspf.<%@ taglib prefix="s" uri="/struts-tags" %>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<script language="javascript" src="${pageContext.request.contextPath}/script/jquery.js"></script>
<script language="javascript" src="${pageContext.request.contextPath}/script/pageCommon.js" charset="utf-8"></script>
<script language="javascript" src="${pageContext.request.contextPath}/script/PageUtils.js" charset="utf-8"></script>
<link type="text/css" rel="stylesheet" href="${pageContext.request.contextPath}/style/blue/pageCommon.css" />
<script type="text/javascript">
</script>
<head>
<title>部门列表</title>
<%@ include file="/WEB-INF/jsp/public/commons.jspf" %>
</head>














 1295
1295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









