







一 分区概念
mysql 5.1 以后支持分区, 有点类似MongoDB中的分片概念.
就是按照一定的规则, 将一个数据库表分解成很多细小的表, 这些细小的表可以是物理的分区, 就是在不同的位置. 但是站在应用的角度来看,分区又是透明的, 整体上看起来还是一个表,不影响使用.
二 分区优点
1 可以存储更多的内容, 因为物理上可以放在不同的位置.
2 提高查询效率, 如果分区的时候按照特定的规则, 将符合特定要求数据放在同一个分区内, 比如按照时间分区,查询的时候只要扫描某一个或几个分区即可.
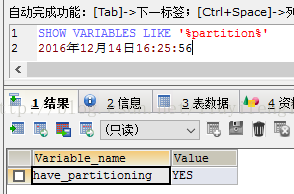
三 查看你的mysql版本库是否支持mysql分区.
使用命令 SHOW VARIABLES LIKE '%partition%' 查看
四 分区键及分区类型
mysql的表要分区, 那么问题就来了, 到底按照什么分呢,怎么分呢?
mysql分区有个分区键的概念, 根据分区键去分区的, 分区键要么是主键,或者唯一键, 要么这个表没有主键/ 唯一键.
举个栗子: 如果你创建一张表, 想按照时间字段年或者月去分区的话, 这个表要么时间字段是主键, 要么没有主键.
RANGE分区:范围分区, 基于一个给定的连续范围, 把数据分配到不同的分区, 如:时间范围, 或者id自增长的, 1-10万 ,10-20万条数据
LIST分区: 类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择。 比如: 表内10条数据, id 1-10 , 将 id等于 1,3,5,7,9 放第一个分区, 2,4,6,8,10 放第二个分区 , 分区键等于特定的某个值
· HASH分区:基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含MySQL 中有效的、产生非负整数值的任何表达式。如: 将id为字符串类型的uuid 通过hash计算, 均匀的分配到 4个分区中
· KEY分区:类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL 服务器提供其自身的哈希函数。必须有一列或多列包含整数值。
Columns分区: mysql5.5以后引入的分区,主要解决5.5以前 分区键只能是整形的问题, columns 细分为list columns 和 Range columns 分区, 支持 整型,字符串和时间类型.
RANGE分区案例:
按照日期的年分表, 通过Year函数获取分区键的具体年份, VALUES LESS 表示少于1991年的放入p0, 类推
时间函数,TO_DAYS和 TO_SECONDS(我当前版本5.5支持) 可以让你更精确的分到天甚至秒.
PARTITION p3 VALUES LESS THAN MAXVALUE 是防止超过你设置的分区的话,都会存在最后一个分区内.
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1989-01-01',
separated DATE NOT NULL DEFAULT '2016-12-14',
job_code INT,
store_id INT
)
PARTITION BY RANGE (YEAR(separated)) (
PARTITION p0 VALUES LESS THAN (1991),
PARTITION p1 VALUES LESS THAN (1996),
PARTITION p2 VALUES LESS THAN (2001),
PARTITION p3 VALUES LESS THAN MAXVALUE
);
RANGE分区应用
特别适用于有分区条件的查询和统计, 可以非常有效的避免全表扫描. 比如要查询时间范围在1991 年以前的数据, 只会扫描p0 ,可以用mysql explain命令查看.
LIST分区 案例:
按照分类的具体id分区, 如果插入的数据, 超出以下这几个固定值, 则会报错.
mysql 5.5 以后支持 非整数分区了, 下边的分类id 就可以换成具体的分类字符串了
CREATE TABLE employees2 (
id INT NOT NULL,
category INT
)PARTITION BY LIST(category)(
PARTITION p0 VALUES IN (3,5),
PARTITION p1 VALUES IN (1,2),
PARTITION p2 VALUES IN (4),
PARTITION p3 VALUES IN (7,8)
);
HASH分区案例:
主要是针对分区键进行一个散列函数计算, 来确定数据到底放到哪个分区,hash分区主要分为两种, 一种是常规的hash分区, 算法就是取模运算, 另外一种就是线性2的幂的运算.
创建的语法上后者比前者多了一个LINEAR 比如: PARTITION BY LINEAR HASH(store_id) PARTITIONS 4;
两者的优缺点: 取模运算的hash分区,在进行分区管理, 比如curd分区的时候, 处理工作会非常的浩大, 归根就是取模算法的问题.
线程运算的hash就没这个问题, 但是相对于取模运算, 这个算法导致数据的存储不是很均匀
CREATE TABLE employees3 (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1989-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY HASH(store_id) PARTITIONS 4;
Key分区案例
跟范围分区很想, 区别是范围分区是通过一个表达式将分区键进行计算得到的一个具体的值来进行分区, 而key分区直接通过一个具体的值进行计算
CREATE TABLE tk (
col1 INT NOT NULL,
col2 CHAR(5),
col3 DATE
)
PARTITION BY LINEAR KEY (col1)
PARTITIONS 3;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









