







tf.keras CNN网络搭建笔记
这里写目录标题
基本流程,以LeNet为例
创建Sequential模型
创建Sequential模型,并添加相应神经层
model = tf.keras.Sequential([
# 卷积核数量为6,大小为3*3
keras.layers.Conv2D(6, 3),
# strides步长
keras.layers.MaxPooling2D(pool_size=2, strides=2),
keras.layers.ReLU(),
keras.layers.Conv2D(16, 3),
keras.layers.MaxPooling2D(pool_size=2, strides=2),
keras.layers.ReLU(),
# 矩阵数据拉平
keras.layers.Flatten(),
keras.layers.Dense(120, activation='relu'),
keras.layers.Dense(84, activation='relu'),
keras.layers.Dense(10, activation='softmax')
])
model.build(input_shape=(batch, 28, 28, 1))
也可将
keras.layers.Dense(10, activation='softmax')
移出,在Sequential外用以下代替
model.add(keras.layers.Dense(10, activation='softmax'))
配置模型的学习流程
model.compile(optimizer = 优化器, loss = 损失函数, metrics = ["准确率”])
model.compile(
optimizer=keras.optimizers.Adam(),
loss = keras.losses.CategoricalCrossentropy(),
metrics = ['accuracy']
)
数据预处理
tf.data.Dataset.from_tensor_slices() 函数对数据集切片
shuffle() 打乱数据,参数为样本数
batch() 函数设置 batch size 值
map() 函数进行预处理
def preprocess(x, y):
x = tf.cast(x, dtype=tf.float32) / 255
x = tf.reshape(x, [-1, 28, 28, 1])
y = tf.one_hot(y, depth=10)
return x, y
train_db = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_db = train_db.shuffle(10000)
train_db = train_db.batch(128)
train_db = train_db.map(preprocess)
test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test))
test_db = test_db.shuffle(10000)
test_db = test_db.batch(128)
test_db = test_db.map(preprocess)
模型训练与验证
# 训练
model.fit(train_db, epochs=5)
# 验证
model.evaluate(test_db)
相关函数注释
Conv2D
tf.keras.layers.Conv2D(
filters, kernel_size, strides=(1, 1), padding='valid',
data_format=None, dilation_rate=(1, 1), groups=1, activation=None,
use_bias=True, kernel_initializer='glorot_uniform',
bias_initializer='zeros', kernel_regularizer=None,
bias_regularizer=None, activity_regularizer=None, kernel_constraint=None,
bias_constraint=None, **kwargs
)
filters:卷积核通道数
kernel_size:卷积核大小,用2个整数的元组或列表表示,比如(3,3),[5,5]
strides:步长
padding可选“valid”和“same”。卷积核的尺寸为S,输入的尺寸为P,padding = ‘valid“时,卷积后的height,width结果为:height =width = (P-S)/strides +1
data_format:输入数据格式,表示通道数的位置,默认为“channels_last”。“channels_first”应将数据组织为(batch_size, channels, height, width),而“channels_last”应将数据组织为(batch_size,height,width,channels)。
activation=None:相当于经过卷积输出后,在经过一次激活函数,常见的激活函数有relu,softmax,selu等
use_bias =0 、1,偏置项,0表示没有增加bias,1表示有
MaxPooling2D
tf.keras.layers.MaxPool2D(
pool_size=(2, 2), strides=None, padding='valid', data_format=None,
**kwargs
)
其他操作
自定义卷积层
super().init()为类继承
call()第一次调用的时候会调用 build() ,然后设置self.built = True,之后每次调用时不再调用build()
class C2(tf.keras.layers.Layer):
def __init__(self):
super().__init__()
def build(self, input_shape):
self.w = tf.random.normal([5, 5, input_shape[-1], 256])
def call(self, inputs):
return tf.nn.conv2d(inputs,
filters=self.w,
strides=1,
padding=[[0, 0], [2, 2],
[2, 2], [0, 0]])
BN层
和激活函数层、卷积层、全连接层、池化层一样,BN(Batch Normalization)也属于网络的一层
主要目的加快收敛速度,减少学习率、参数初始化、权重衰减系数、Drop out比例等参数调整
keras.layers.BatchNormalization()
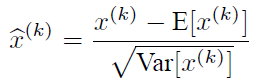
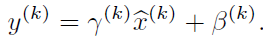
简单逻辑如下,其中gamma和beta通过学习改变
m = K.mean(X, axis=-1, keepdims=True) #计算均值
std = K.std(X, axis=-1, keepdims=True) #计算标准差
X_normed = (X - m) / (std + self.epsilon) #归一化
out = self.gamma * X_normed + self.beta #重构变换
Dropout
缓解过拟合
tf.keras.layers.Dropout(
rate, noise_shape=None, seed=None, **kwargs
)















 1384
1384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









