






摘 要: 随着人们对应用程序的要求越来越高,单进程应用在许多场合已不能满足人们的要求。编写多进程/多线程程序成为现代程序设计的一个重要特点,在多进程程序设计中,进程间的通信是不可避免的。Microsoft Win32 API提供了多种进程间通信的方法,全面地阐述了这些方法的特点,并加以比较和分析,希望能给读者选择通信方法提供参考。
关键词 进程 进程通信 IPC Win32 API
1 进程与进程通信
进程是装入内存并准备执行的程序,每个进程都有私有的虚拟地址空间,由代码、数据以及它可利用的系统资源(如文件、管道等)组成。多进程/多线程是Windows操作系统的一个基本特征。Microsoft Win32应用编程接口(Application Programming Interface, API)提供了大量支持应用程序间数据共享和交换的机制,这些机制行使的活动称为进程间通信(InterProcess Communication, IPC),进程通信就是指不同进程间进行数据共享和数据交换。
正因为使用Win32 API进行进程通信方式有多种,如何选择恰当的通信方式就成为应用开发中的一个重要问题,下面本文将对Win32中进程通信的几种方法加以分析和比较。
2 进程通信方法
2.1 文件映射
文件映射(Memory-Mapped Files)能使进程把文件内容当作进程地址区间一块内存那样来对待。因此,进程不必使用文件I/O操作,只需简单的指针操作就可读取和修改文件的内容。
Win32 API允许多个进程访问同一文件映射对象,各个进程在它自己的地址空间里接收内存的指针。通过使用这些指针,不同进程就可以读或修改文件的内容,实现了对文件中数据的共享。
应用程序有三种方法来使多个进程共享一个文件映射对象。
(1)继承:第一个进程建立文件映射对象,它的子进程继承该对象的句柄。
(2)命名文件映射:第一个进程在建立文件映射对象时可以给该对象指定一个名字(可与文件名不同)。第二个进程可通过这个名字打开此文件映射对象。另外,第一个进程也可以通过一些其它IPC机制(有名管道、邮件槽等)把名字传给第二个进程。
(3)句柄复制:第一个进程建立文件映射对象,然后通过其它IPC机制(有名管道、邮件槽等)把对象句柄传递给第二个进程。第二个进程复制该句柄就取得对该文件映射对象的访问权限。
文件映射是在多个进程间共享数据的非常有效方法,有较好的安全性。但文件映射只能用于本地机器的进程之间,不能用于网络中,而开发者还必须控制进程间的同步。
2.2 共享内存
Win32 API中共享内存(Shared Memory)实际就是文件映射的一种特殊情况。进程在创建文件映射对象时用0xFFFFFFFF来代替文件句柄(HANDLE),就表示了对应的文件映射对象是从操作系统页面文件访问内存,其它进程打开该文件映射对象就可以访问该内存块。由于共享内存是用文件映射实现的,所以它也有较好的安全性,也只能运行于同一计算机上的进程之间。
2.3 匿名管道
管道(Pipe)是一种具有两个端点的通信通道:有一端句柄的进程可以和有另一端句柄的进程通信。管道可以是单向-一端是只读的,另一端点是只写的;也可以是双向的-管道的两端点既可读也可写。
匿名管道(Anonymous Pipe)是 在父进程和子进程之间,或同一父进程的两个子进程之间传输数据的无名字的单向管道。通常由父进程创建管道,然后由要通信的子进程继承通道的读端点句柄或写 端点句柄,然后实现通信。父进程还可以建立两个或更多个继承匿名管道读和写句柄的子进程。这些子进程可以使用管道直接通信,不需要通过父进程。
匿名管道是单机上实现子进程标准I/O重定向的有效方法,它不能在网上使用,也不能用于两个不相关的进程之间。
2.4 命名管道
命名管道(Named Pipe)是服务器进程和一个或多个客户进程之间通信的单向或双向管道。不同于匿名管道的是命名管道可以在不相关的进程之间和不同计算机之间使用,服务器建立命名管道时给它指定一个名字,任何进程都可以通过该名字打开管道的另一端,根据给定的权限和服务器进程通信。
命名管道提供了相对简单的编程接口,使通过网络传输数据并不比同一计算机上两进程之间通信更困难,不过如果要同时和多个进程通信它就力不从心了。
2.5 邮件槽
邮件槽(Mailslots)提供进程间单向通信能力,任何进程都能建立邮件槽成为邮件槽服务器。其它进程,称为邮件槽客户,可以通过邮件槽的名字给邮件槽服务器进程发送消息。进来的消 息一直放在邮件槽中,直到服务器进程读取它为止。一个进程既可以是邮件槽服务器也可以是邮件槽客户,因此可建立多个邮件槽实现进程间的双向通信。
通过邮件槽可以给本地计算机上的邮件槽、其它计算机上的邮件槽或指定网络区域中所有计算机上有同样名字的邮件槽发送消息。广播通信的消息长度不能超过400字节,非广播消息的长度则受邮件槽服务器指定的最大消息长度的限制。
邮件槽与命名管道相似,不过它传输数据是通过不可靠的数据报(如TCP/IP协议中的UDP包)完成的,一旦网络发生错误则无法保证消息正确地接收,而命名管道传输数据则是建立在可靠连接基础上的。不过邮件槽有简化的编程接口和给指定网络区域内的所有计算机广播消息的能力,所以邮件槽不失为应用程序发送和接收消息的另一种选择。
2.6 剪贴板
剪贴板(Clipped Board)实质是Win32 API中一组用来传输数据的函数和消息,为Windows应用程序之间进行数据共享提供了一个中介,Windows已建立的剪切(复制)-粘贴的机制为不同应用程序之间共享不同格式数据提供了一条捷径。当用户在应用程序中执行剪切或复制操作时,应用程序把选取的数据用一种或多种格式放在剪贴板上。然后任何其它应用程序都可以从剪贴板上拾取数据,从给定格式中选择适合自己的格式。
剪贴板是一个非常松散的交换媒介,可以支持任何数据格式,每一格式由一无符号整数标识,对标准(预定义)剪贴板格式,该值是Win32 API定义的常量;对非标准格式可以使用Register Clipboard Format函数注册为新的剪贴板格式。利用剪贴板进行交换的数据只需在数据格式上一致或都可以转化为某种格式就行。但剪贴板只能在基于Windows的程序中使用,不能在网络上使用。
2.7 动态数据交换
动态数据交换(DDE)是使用共享内存在应用程序之间进行数据交换的一种进程间通信形式。应用程序可以使用DDE进行一次性数据传输,也可以当出现新数据时,通过发送更新值在应用程序间动态交换数据。
DDE和剪贴板一样既支持标准数据格式(如文本、位图等),又可以支持自己定义的数据格式。但它们的数据传输机制却不同,一个明显区别是剪贴板操作几乎总是用作对用户指定操作的一次性应答-如从菜单中选择Paste命令。尽管DDE也可以由用户启动,但它继续发挥作用一般不必用户进一步干预。DDE有三种数据交换方式:
(1) 冷链:数据交换是一次性数据传输,与剪贴板相同。
(2) 温链:当数据交换时服务器通知客户,然后客户必须请求新的数据。
(3) 热链:当数据交换时服务器自动给客户发送数据。
DDE交换可以发生在单机或网络中不同计算机的应用程序之间。开发者还可以定义定制的DDE数据格式进行应用程序之间特别目的IPC,它们有更紧密耦合的通信要求。大多数基于Windows的应用程序都支持DDE。
2.8 对象连接与嵌入
应用程序利用对象连接与嵌入(OLE)技术管理复合文档(由多种数据格式组成的文档),OLE提供使某应用程序更容易调用其它应用程序进行数据编辑的服务。例如,OLE支持的字处理器可以嵌套电子表格,当用户要编辑电子表格时OLE库可自动启动电子表格编辑器。当用户退出电子表格编辑器时,该表格已在原始字处理器文档中得到更新。在这里电子表格编辑器变成了字处理器的扩展,而如果使用DDE,用户要显式地启动电子表格编辑器。
同DDE技术相同,大多数基于Windows的应用程序都支持OLE技术。
2.9 动态连接库
Win32动态连接库(DLL)中的全局数据可以被调用DLL的所有进程共享,这就又给进程间通信开辟了一条新的途径,当然访问时要注意同步问题。
虽然可以通过DLL进行进程间数据共享,但从数据安全的角度考虑,我们并不提倡这种方法,使用带有访问权限控制的共享内存的方法更好一些。
2.10 远程过程调用
Win32 API提供的远程过程调用(RPC)使应用程序可以使用远程调用函数,这使在网络上用RPC进行进程通信就像函数调用那样简单。RPC既可以在单机不同进程间使用也可以在网络中使用。
由于Win32 API提供的RPC服从OSF-DCE(Open Software Foundation Distributed Computing Environment)标准。所以通过Win32 API编写的RPC应用程序能与其它操作系统上支持DEC的RPC应用程序通信。使用RPC开发者可以建立高性能、紧密耦合的分布式应用程序。
2.11 NetBios函数
Win32 API提供NetBios函数用于处理低级网络控制,这主要是为IBM NetBios系统编写与Windows的接口。除非那些有特殊低级网络功能要求的应用程序,其它应用程序最好不要使用NetBios函数来进行进程间通信。
2.12 Sockets
Windows Sockets规范是以U.C.Berkeley大学BSD UNIX中流行的Socket接口为范例定义的一套Windows下的网络编程接口。除了Berkeley Socket原有的库函数以外,还扩展了一组针对Windows的函数,使程序员可以充分利用Windows的消息机制进行编程。
现在通过Sockets实现进程通信的网络应用越来越多,这主要的原因是Sockets的跨平台性要比其它IPC机制好得多,另外WinSock 2.0不仅支持TCP/IP协议,而且还支持其它协议(如IPX)。Sockets的唯一缺点是它支持的是底层通信操作,这使得在单机的进程间进行简单数据传递不太方便,这时使用下面将介绍的WM_COPYDATA消息将更合适些。
2.13 WM_COPYDATA消息
WM_COPYDATA是一种非常强大却鲜为人知的消息。当一个应用向另一个应用传送数据时,发送方只需使用调用SendMessage函数,参数是目的窗口的句柄、传递数据的起始地址、WM_COPYDATA消息。接收方只需像处理其它消息那样处理WM_COPY DATA消息,这样收发双方就实现了数据共享。
WM_COPYDATA是一种非常简单的方法,它在底层实际上是通过文件映射来实现的。它的缺点是灵活性不高,并且它只能用于Windows平台的单机环境下。
3 结束语
Win32 API为应用程序实现进程间通信提供了如此多种选择方案,那么开发者如何进行选择呢?通常在决定使用哪种IPC方法之前应考虑以下一些问题:
(1)应用程序是在网络环境下还是在单机环境下工作。
附:
在我学windows编程的时候,对进程间如何通信总是感觉很神秘,网络上介绍的方法很多,但是很少有一个系统的介绍,五花八门的说法让人总是一头雾水,在这里,我整理一下各通信方法,梳理了一下这些方法的优缺点,希望能对各位看官起到抛砖引玉的作用。 非标准的进程间通信技术有:Windows消息,内存映射,内存共享等等。
1. Windows消息实现进程间通信。 消息的接受进程和发送进程都要定义相同的消息。但是,如果发送方仅仅是发送消息,那么发送方可以不实现消息映射,不用定义消息响应函数。接受方需要定义映射和相应函数。 自定义消息的实现进程间通信的缺陷是,由于消息的传递参数是个长整形 lparam, 因此,只能传递整形的数据,而不能传递字符串。有个可以的思路是,传递字符串所在的地址,然后另一个程序通过获得发送方的进程句柄,用函数ReadProcessMemory与WriteProcessMemory操作发送方的内存空间来读取内容。
2. 使用MFC定义的WM_COPYDATA消息 该消息其实与普通的自定义消息通信类似,区别是,传送的是一个指向COPYDATASTRUCT 结构的指针,要传递的字符串就保存在这个结构体里。这个结构的第一个变量 dwData可以设置为0即可。 这个消息与 上面的那个思路的不同是,获得了结构体的指针后,接受进程不需要其他的处理就能获取到指针的数据,就好像在同一个进程里通信一样. 另外注意,该消息的接受有时并不能获得所需要的长度,有可能只接收到了一部分。 因此,该方式只适合于传递是少量的数据。
3.使用进程内存读写函数 基本上与方法一得后面猜想部分相同。关键是,要使用GlobalAlloc()或者VirtualAllocEx来分配内存空间存放数据。把数据写入接收方的进程内存,然后接着就发消息告诉他数据的地址。由于是在发送方申请的内存,那么,最好等待sleep一定时间再VirtualFreeEx申请到得内存。 GlobalAlloc()或者VirtualAllocEx可以实现在另一个进程的内存空间来申请内存,这就为什么上面能进行的原因。也就是说,发送方并不在自己的内存空间申请内存,而是在接收方进程内存空间来申请内存。然后写入输入数据。当然,也可以在发送方的进程空间来申请内存,接收方通过跨进程读写的方式来读。这只是处理方式不同而已。
4.使用内存映射文件的方法 内存映射的好处就是,可以像对待一个文件一样来对待一块内存区。文件时可以被不同的进程来读写的。既然那块内存 区像文件一样,那么这块内存区就可以被不同的进程来读写。
5.使用DLL进行通信 Win32 DLL 只能共享代码不能共享数据,不同的进程载入同一个DLL文件,DLL的代码都只载入了一份到内存,这只载入一份代码仅指同一个DLL文件,如果相同的DLL文件在不同的盘符下,也不是同一个DLL,而是同一DLL多个副本。 Win16 DLL 被载入了系统内存,所以调用它的进程都可以访问到它的全局变量,因此可以很容易的实现进程间通信。但是对于win32 DLL , 操作系统会把该DLL映射到每个调用它的进程的地址空间,DLL成为该进程的一部分。 可以用下面的方法来将DLL的数据区设置为共享区。
#pragma da
char m_strString[256]=TEXT(""); // 共享的数据。特别要注意需要初始化,因为编译器会把未初始化的变量保存在bss数据段。
volatile bool bInCriticalSection=FALSE; // 同步标示
#pragma da
#pragma comment(linker,"/SECTION:SHARED,RWS") // 将要共享的数据段通知编译器。
CCriticalSection cs; // 临界区,控制同步的 上面控制了同步问题。
6.使用操作系统提供的剪贴板实现通信 使用剪贴板是一中开销较小的进程通信机制。剪贴板机制的原理是,剪贴板是系统预留的一块全局内存,用来暂存进程间进行数据交换的数据。 提供数据的进程需要先创建一个全局内存块,然后将要传送的数据移到或复制到该内存块。 接收进程需要获得此内存块的句柄,完成数据读取。
下面的程序标明怎么在剪贴板写数据
CString strData=m_strClipBoard; // 获得数据.
// 打开系统剪贴板.
if (!OpenClipboard()) return;
// 使用之前,清空系统剪贴板.
EmptyClipboard();
// 分配一内存,大小等于要拷贝的字符串的大小,返回该内存控制句柄.
HGLOBAL hClipboardData;
hClipboardData = GlobalAlloc(GMEM_DDESHARE, strData.GetLength()+1);
// 内存控制句柄加锁,返回值为指向那内存控制句柄所在的特定数据格式的指针.
char * pchData; pchData = (char*)GlobalLock(hClipboardData);
// 将本地变量的值赋给全局内存.
strcpy(pchData, LPCSTR(strData));
// 给加锁的全局内存控制句柄解锁.
GlobalUnlock(hClipboardData);
// 通过全局内存句柄将要拷贝的数据放到剪贴板上.
SetClipboardData(CF_TEXT,hClipboardData);
// 使用完后关闭剪贴板.
CloseClipboard();
从剪贴板读取数据的代码如下:
// 打开系统剪贴板.
if (!OpenClipboard()) return;
// 判断剪贴板上的数据是否是指定的数据格式.
if (IsClipboardFormatAvailable(CF_TEXT)|| IsClipboardFormatAvailable(CF_OEMTEXT)) {
// 从剪贴板上获得数据.
HANDLE hClipboardData = GetClipboardData(CF_TEXT);
// 通过给内存句柄加锁,获得指向指定格式数据的指针.
char *pchData = (char*)GlobalLock(hClipboardData);
// 本地变量获得数据.
m_strClipBoard = pchData;
// 给内存句柄解锁.
GlobalUnlock(hClipboardData);
}
else
{
AfxMessageBox("There is no text (ANSI) da
// 使用完后关闭剪贴板.
CloseClipboard();
// 更新数据.
UpdateData(FALSE);
7.DDE (Dynamic Da
8. 消息管道 Message Pipes又分为匿名管道(anonymous Pipes),和 命名管道(Named Pipes), 匿名管道主要用于本地系统上父进程与他启动的子进程间的通信。命名管道高级些,可以再不同的系统上的进程间通信,因为UNIX, LINUX等都支持这项技术,因此,命名管道技术是比较理想的C/S结构通信技术。 命名管道原理是,一个进程把数据放进管道中,另一个知道管道名字的经常来把数据取走。其他不知道管道名字的进程不可能能把数据取走。 因此,管道实际上就是一块进程间的共享内存。 创建管道的进程叫管道服务器,链接管道的进程就是客户机。创建管道的函数是HANDLE CreateNamedPipe(….); 连接管道 CallNamedPipe(); 读入或写入数据后腰关闭它 ConnectNamedPipe(); 服务器准备好一个连接到客户进程的管道,并一直等待知道客户连接上为止。 DisconnectNamedPipe(); 服务器中断与客户的连接 GetNamedPipeHandleState(); 获取一个命名管道的状态信息 GetNamedPipeInfo();获取一个命名管道的信息 PeekNamedPipe(); 从一个管道中复制数据到一个缓冲区 SetNamedPipeHandleState(); 设置一个管道的状态信息以及管道类型 TransactNamedPipe(); 从一个消息管道读消息或写消息 WaitNamedPipe(); 使服务器等待来自客户的实例连接。 管道通信基本流程
(1)连接建立 服务器端通过ConnectNamedPipe函数建立以个命名管道实例,然后通过ConnectNamedPipe()函数来侦听来自客户端得请求。这个函数可以设置等待时间。 客户端只需使用函数WaitNamedPipe()来连接服务器。
(2)通信实现 建立连接后,就可以通过得到管道的文件句柄利用ReadFile()与WriteFile()进行彼此间的通信。
(3)连接终止 客户端调用CloseFile(), 服务器端调用DisconnectNamedPipe()终止连接。且都需要CloseHandle来关闭管道。
9.邮槽通信
10.套接字通信 套接字通信过程可简单的描述为,主要调用5个函数,socket(),bind(), Listen(), connect(), accept(). 服务器端主要调用socket(),bind(), Listen(),accept()。 客户端主要调用socket(),connect()。 双方的数据传送就是通过send() 与recv()完成。 套接字类型主要有5种,SOCK_STREAM, SOCK_DGRAM, SOCK_RAW, SOCK_SEQPACKET, SOCK_RDM.
10.1 Winsock 程序设计流程
(1)程序编译环境 有两套函数进行Winsock程序设计,Socket1.1 与Socket2.0. 可以灵活混用。Socket2.0得功能较为强大。 包含其中一个头文件及其对应的库文件即可。
// Socket2.0
#include
#pragma comment (lib, “ws2_32.lib”);
// Socket1.1
#include
#pragma comment (lib, “wsock32.lib”);
(2)选择机制(异步?非阻塞?) 默认情况下都是创建的阻塞套接字。可以通过select或者WSAAsynSelect()函数将其变为非阻塞的。特别注意,用这个函数改为非阻塞后,不能简单的利用ioctlsocket()将它再变为阻塞模式。也就是说这两个函数改变阻塞模式是由区别的。ioctlsocket()是将异步模式的套接字再改回阻塞模式,但之前要调用WSAAsynSelect()取消所有的异步事件,WSAAsynSelect(s,hWnd,0,0);
(3)启动与终止 启动函数WSAStartup()建立于Winsock DLL 的连接, 终止函数WSAClearup()终止该DLL,这两个函数必须成对使用。
(4)出错处理 Winsock为了与以后的多线程环境相兼容,提供了两个出错处理函数来获取和设置当前线程的最近错误号,即WSAGetLastError()和WSASetLastError();
- 1 Windows进程间通信的各种方法
- 进程是装入内存并准备执行的程序,每个进程都有私有的虚拟地址空间,由代码、数据以及它可利用的系统资源(如文件、管道等)组成。
- 多进程/多线程是Windows操作系统的一个基本特征。Microsoft Win32应用编程接口(Application Programming Interface, API)
- 提供了大量支持应用程序间数据共享和交换的机制,这些机制行使的活动称为进程间通信(InterProcess Communication, IPC),
- 进程通信就是指不同进程间进行数据共享和数据交换。
- 正因为使用Win32 API进行进程通信方式有多种,如何选择恰当的通信方式就成为应用开发中的一个重要问题,
- 下面本文将对Win32中进程通信的几种方法加以分析和比较。
- 2 进程通信方法
- 2.1 文件映射
- 文件映射(Memory-Mapped Files)能使进程把文件内容当作进程地址区间一块内存那样来对待。因此,进程不必使用文件I/O操作,
- 只需简单的指针操作就可读取和修改文件的内容。
- Win32 API允许多个进程访问同一文件映射对象,各个进程在它自己的地址空间里接收内存的指针。通过使用这些指针,不同进程就可以读或修改文件的内容,
- 实现了对文件中数据的共享。
- 应用程序有三种方法来使多个进程共享一个文件映射对象。
- (1)继承:第一个进程建立文件映射对象,它的子进程继承该对象的句柄。
- (2)命名文件映射:第一个进程在建立文件映射对象时可以给该对象指定一个名字(可与文件名不同)。第二个进程可通过这个名字打开此文件映射对象。
- 另外,第一个进程也可以通过一些其它IPC机制(有名管道、邮件槽等)把名字传给第二个进程。
- (3)句柄复制:第一个进程建立文件映射对象,然后通过其它IPC机制(有名管道、邮件槽等)把对象句柄传递给第二个进程。
- 第二个进程复制该句柄就取得对该文件映射对象的访问权限。
- 文件映射是在多个进程间共享数据的非常有效方法,有较好的安全性。但文件映射只能用于本地机器的进程之间,不能用于网络中
- ,而开发者还必须控制进程间的同步。
- 2.2 共享内存
- Win32 API中共享内存(Shared Memory)实际就是文件映射的一种特殊情况。进程在创建文件映射对象时用0xFFFFFFFF来代替 文件句柄(HANDLE),
- 就表示了对应的文件映射对象是从操作系统页面文件访问内存,其它进程打开该文件映射对象就可以访问该内存块。由于共享内存是用 文件映射实现的,
- 所以它也有较好的安全性,也只能运行于同一计算机上的进程之间。
- a.设定一块共享内存区域
- HANDLE CreateFileMapping(HANDLE,LPSECURITY_ATTRIBUTES, DWORD, DWORD, DWORD, LPCSTR)// 产生一个file-mapping核心对象
- LPVOID MapViewOfFile(
- HANDLE hFileMappingObject,
- DWORD dwDesiredAcess,
- DWORD dwFileOffsetHigh,
- DWORD dwFileOffsetLow,
- DWORD dwNumberOfBytesToMap
- );得到共享内存的指针
- b.找出共享内存
- 决定这块内存要以点对点(peer to peer)的形式呈现每个进程都必须有相同的能力,产生共享内存并将它初始化。每个进程都应该调用CreateFileMapping(),
- 然后调用GetLastError().如果传回的错误代码是 ERROR_ALREADY_EXISTS,那么进程就可以假设这一共享内存区 域已经被别的进程打开并初始化了,
- 否则该进程就可以合理的认为自己 排在第 一位,并接下来将共享内存初始化。还是要使用client/server架构中只有server进程才应该产生并初始化共享内存。
- 所有的进程都应该使用
- HANDLE OpenFileMapping(DWORD dwDesiredAccess,
- BOOL bInheritHandle,
- LPCTSTR lpName);
- 再调用MapViewOfFile(),取得共享内存的指针
- c.同步处理(Mutex)
- d.清理(Cleaning up) BOOL UnmapViewOfFile(LPCVOID lpBaseAddress);
- CloseHandle()
- 2.3 匿名管道
- 管道(Pipe)是一种具有两个端点的通信通道:有一端句柄的进程可以和有另一端句柄的进程通信。管道可以是单向-一端是只读的,另一端点是只写的;
- 也可以是双向的一管道的两端点既可读也可写。
- 匿名管道(Anonymous Pipe)是 在父进程和子进程之间,或同一父进程的两个子进程之间传输数据的无名字的单向管道。通常由父进程创建管 道,
- 然后由要通信的子进程继承通道的读端点句柄或写 端点句柄,然后实现通信。父进程还可以建立两个或更多个继承匿名管道读和写句柄的子进程。
- 这些子进程 可以使用管道直接通信,不需要通过父进程。
- 匿名管道是单机上实现子进程标准I/O重定向的有效方法,它不能在网上使用,也不能用于两个不相关的进程之间。
- 2.4 命名管道
- 命名管道(Named Pipe)是服务器进程和一个或多个客户进程之间通信的单向或双向管道。不同于匿名管道的是命名管道可以在不相关的进程之间和不 同计算机之间使用,
- 服务器建立命名管道时给它指定一个名字,任何进程都可以通过该名字打开管道的另一端,根据给定的权限和服务器进程通信。
- 命名管道提供了相对简单的编程接口,使通过网络传输数据并不比同一计算机上两进程之间通信更困难,不过如果要同时和多个进程通信它就力不从心了。
- 2.5 邮件槽
- 邮件槽(Mailslots)提 供进程间单向通信能力,任何进程都能建立邮件槽成为邮件槽服务器。其它进程,称为邮件槽客户,可以通过邮件槽的名字给
- 邮件槽服务器进程发送消息。进来的消 息一直放在邮件槽中,直到服务器进程读取它为止。一个进程既可以是邮件槽服务器也可以是邮件槽客户,
- 因此可建立多个 邮件槽实现进程间的双向通信。
- 通过邮件槽可以给本地计算机上的邮件槽、其它计算机上的邮件槽或指定网络区域中所有计算机上有同样名字的邮件槽发送消息。
- 广播通信的消息长度不能超过400字节,非广播消息的长度则受邮件槽服务器指定的最大消息长度的限制。
- 邮件槽与命名管道相似,不过它传输数据是通过不可靠的数据报(如TCP/IP协议中的UDP包)完成的,一旦网络发生错误则无法保证消息正确地接收,
- 而 命名管道传输数据则是建立在可靠连接基础上的。不过邮件槽有简化的编程接口和给指定网络区域内的所有计算机广播消息的能力,
- 所以邮件槽不失为应用程序发送 和接收消息的另一种选择。
- 2.6 剪贴板
- 剪贴板(Clipped Board)实质是Win32 API中一组用来传输数据的函数和消息,为Windows应用程序之间进行数据共享提供了一个 中介,
- Windows已建立的剪切(复制)-粘贴的机制为不同应用程序之间共享不同格式数据提供了一条捷径。当用户在应用程序中执行剪切或复制操作时,
- 应 用程序把选取的数据用一种或多种格式放在剪贴板上。然后任何其它应用程序都可以从剪贴板上拾取数据,从给定格式中选择适合自己的格式。
- 剪贴板 是一个非常松散的交换媒介,可以支持任何数据格式,每一格式由一无符号整数标识,对标准(预定义)剪贴板格式,该值是Win32 API定义的常量;
- 对非 标准格式可以使用Register Clipboard Format函数注册为新的剪贴板格式。利用剪贴板进行交换的数据只需在数据格式上一致或都可以
- 转化为某种格式就行。但剪贴板只能在基于Windows的程序中使用,不能在网络上使用。
- 2.7 动态数据交换
- 动态数据交换(DDE)是使用共享内存在应用程序之间进行数据交换的一种进程间通信形式。应用程序可以使用DDE进行一次性数据传输,也可以当出现新数据时,
- 通过发送更新值在应用程序间动态交换数据。
- DDE和剪贴板一样既支持标准数据格式(如文本、位图等),又可以支持自己定义的数据格式。但它们的数据传输机制却不同,一个明显区别是剪贴板操作几乎
- 总是用作对用户指定操作的一次性应答-如从菜单中选择Paste命令。尽管DDE也可以由用户启动,但它继续发挥作用一般不必用户进一步干预。DDE有三 种数据交换方式:
- (1) 冷链:数据交换是一次性数据传输,与剪贴板相同。
- (2) 温链:当数据交换时服务器通知客户,然后客户必须请求新的数据。
- (3) 热链:当数据交换时服务器自动给客户发送数据。
- DDE交换可以发生在单机或网络中不同计算机的应用程序之间。开发者还可以定义定制的DDE数据格式进行应用程序之间特别目的IPC,它们有更紧密耦合的通信要求。
- 大多数基于Windows的应用程序都支持DDE。
- 2.8 对象连接与嵌入
- 应用程序利用对象连接与嵌入(OLE)技术管理复合文档(由多种数据格式组成的文档),OLE提供使某应用程序更容易调用其它应用程序进行数据编辑的服 务。
- 例如,OLE支持的字处理器可以嵌套电子表格,当用户要编辑电子表格时OLE库可自动启动电子表格编辑器。当用户退出电子表格编辑器时,
- 该表格已在原 始字处理器文档中得到更新。在这里电子表格编辑器变成了字处理器的扩展,而如果使用DDE,用户要显式地启动电子表格编辑器。
- 同DDE技术相同,大多数基于Windows的应用程序都支持OLE技术。
- 2.9 动态连接库
- Win32动态连接库(DLL)中的全局数据可以被调用DLL的所有进程共享,这就又给进程间通信开辟了一条新的途径,当然访问时要注意同步问题。
- 虽然可以通过DLL进行进程间数据共享,但从数据安全的角度考虑,我们并不提倡这种方法,使用带有访问权限控制的共享内存的方法更好一些。
- 2.10 远程过程调用
- Win32 API提供的远程过程调用(RPC)使应用程序可以使用远程调用函数,这使在网络上用RPC进行进程通信就像函数调用那样简单。
- RPC既可以在单机不同进程间使用也可以在网络中使用。
- 由于Win32 API提供的RPC服从OSF-DCE (Open Software Foundation Distributed Computing Environment)标准。
- 所以通过 Win32 API编写的RPC应用程序能与其它操作系统上支持DEC的RPC应用程序通信。使用RPC开发者可以建立高性能、紧密耦合的分布式应用程 序。
- 2.11 NetBios函数
- Win32 API提供NetBios函数用于处理低级网络控制,这主要是为IBM NetBios系统编写与Windows的接口。除非那些有特殊低级网络功能要求的应用程序,
- 其它应用程序最好不要使用NetBios函数来进行进程间通信。
- 2.12 Sockets
- Windows Sockets规范是以U.C.Berkeley大学BSD UNIX中流行的Socket接口为范例定义的一套Windows下的网 络编程接口。除了Berkeley Socket原有的库函数以外
- ,还扩展了一组针对Windows的函数,使程序员可以充分利用Windows的消息机 制进行编程。
- 现在通过Sockets实现进程通信的网络应用越来越多,这主要的原因是Sockets的跨平台性要比其它IPC机制好得多,另 外WinSock 2.0不仅支持TCP/IP协议,
- 而且还支持其它协议(如IPX)。Sockets的唯一缺点是它支持的是底层通信操作,这使得在单机 的进程间进行简单数据传递不太方便,
- 这时使用下面将介绍的WM_COPYDATA消息将更合适些。
- 2.13 WM_COPYDATA消息
- WM_COPYDATA是一种非常强大却鲜为人知的消息。当一个应用向另一个应用传送数据时,发送方只需使用调用SendMessage函数,
- 参数是目 的窗口的句柄、传递数据的起始地址、WM_COPYDATA消息。接收方只需像处理其它消息那样处理WM_COPY DATA消息,这样收发双方就实现了 数据共享。
- WM_COPYDATA是一种非常简单的方法,它在底层实际上是通过文件映射来实现的。
- 它的缺点是灵活性不高,并且它只能用于Windows平台的单机环境下。
- 3 结束语
- Win32 API为应用程序实现进程间通信提供了如此多种选择方案,
- 那么开发者如何进行选择呢?通常在决定使用哪种IPC方法之前应考虑以下一些问题:
- (1)应用程序是在网络环境下还是在单机环境下工作。
- 方法一:WM_COPYDATA
- HWND hReceiveDataWindow = FindWindow(NULL,....)
- COPYDATASTRUCT data;
- data.cbdata = strlen(pStr);
- data.lpData = pStr;
- SendMessage(hReceiveDataWindow ,WM_COPYDATA,(WPARAM)GetFocus(),(LPARAM)&data);
- REF.最简单的方式
- http://www.cppblog.com/TechLab/archive/2005/12/30/2272.aspx
- 方法二:dll共享
- #pragma data_seg (".ASHARE")
- int iWhatYouUseInTwo = 0;
- #pragma data_seg()
- 方法三:映象文件
- REF.最基础,效率最高的方法
- 最好的参考书《Windows核心编程》第17章 内存映射文件
- http://blog.codingnow.com/2005/10/interprocess_communications.html
- 方法四:匿名管道:CreatePipe
- 方法五:命名管道:createnamedpipe
- REF.
- http://www.pediy.com/bbshtml/bbs8/pediy8-724.htm
- 方法六:邮件通道
- 方法七:网络接口,socket,但要求有网卡。可以实现不同主机间的IPC
- 另一篇总结的比较好的文章
- http://www.seeitco.com/doc/Html/Visual%20C++/205637623.html
- 进程通常被定义为一个正在运行的程序的实例,它由两个部分组成:
- 一个是操作系统用来管理进程的内核对象。内核对象也是系统用来存放关于进程的统计信息的地方
- 另一个是地址空间,它包含所有的可执行模块或DLL模块的代码和数据。它还包含动态分配的空间。
- 如线程堆栈和堆分配空间。每个进程被赋予它自己的虚拟地址空间,当进程中的一个线程正在运行时,该线程可以访问只属于它的进程的内存。
- 属于其它进程的内存则是隐藏的,并不能被正在运行的线程访问。
- 为了能在两个进程之间进行通讯,由以下几种方法可供参考:
- 0。剪贴板Clipboard: 在16位时代常使用的方式,CWnd中提供支持
- 1。窗口消息 标准的Windows消息以及专用的WM_COPYDATA消息 SENDMESSAGE()接收端必须有一个窗口
- 2。使用共享内存方式(Shared Memory)
- a.设定一块共享内存区域
- HANDLE CreateFileMapping(HANDLE,LPSECURITY_ATTRIBUTES, DWORD, DWORD, DWORD, LPCSTR)
- 产生一个file-mapping核心对象
- LPVOID MapViewOfFile(
- HANDLE hFileMappingObject,
- DWORD dwDesiredAcess,
- DWORD dwFileOffsetHigh,
- DWORD dwFileOffsetLow,
- DWORD dwNumberOfBytesToMap
- );
- 得到共享内存的指针
- b.找出共享内存
- 决定这块内存要以点对点(peer to peer)的形式呈现
- 每个进程都必须有相同的能力,产生共享内存并将它初始化。每个进程
- 都应该调用CreateFileMapping(),然后调用GetLastError().如果传回的
- 错误代码是ERROR_ALREADY_EXISTS,那么进程就可以假设这一共享内存区 域已经被别的进程打开并初始化了,否则该进程就可以合理的认为自己 排在第 一位,并接下来将共享内存初始化。
- 还是要使用client/server架构中
- 只有server进程才应该产生并初始化共享内存。所有的进程都应该使用
- HANDLE OpenFileMapping(DWORD dwDesiredAccess,
- BOOL bInheritHandle,
- LPCTSTR lpName);
- 再调用MapViewOfFile(),取得共享内存的指针
- c.同步处理(Mutex)
- d.清理(Cleaning up) BOOL UnmapViewOfFile(LPCVOID lpBaseAddress);
- CloseHandle()
- 3。动态数据交换(DDE)通过维护全局分配内存使的应用程序间传递成为可能
- 其方式是再一块全局内存中手工放置大量的数据,然后使用窗口消息传递内存 指针.这是16位WIN时代使用的方式,因为在WIN32下已经没有全局和局部内存
- 了,现在的内存只有一种就是虚存。
- 4。消息管道(Message Pipe)
- 用于设置应用程序间的一条永久通讯通道,通过该通道可以象自己的应用程序
- 访问一个平面文件一样读写数据。
- 匿名管道(Anonymous Pipes)
- 单向流动,并且只能够在同一电脑上的各个进程之间流动。
- 命名管道(Named Pipes)
- 双向,跨网络,任何进程都可以轻易的抓住,放进管道的数据有固定的格 式,而使用ReadFile()只能读取该大小的倍数。
- 可以被使用于I/O Completion Ports
- 5 邮件槽(Mailslots)
- 广播式通信,在32系统中提供的新方法,可以在不同主机间交换数据,在 WIN9X下只支持邮件槽客户
- 6。Windows套接字(Windows Socket)
- 它具备消息管道所有的功能,但遵守一套通信标准使的不同操作系统之上的应 用程序之间可以互相通信。
- 7。Internet通信 它让应用程序从Internet地址上载或下载文件
- 8。RPC:远程过程调用,很少使用,因其与UNIX的RPC不兼容。
- 9。串行/并行通信(Serial/Parallel Communication)
- 它允许应用程序通过串行或并行端口与其他的应用程序通信
- 10。COM/DCOM
- 通过COM系统的代理存根方式进行进程间数据交换,但只能够表现在对接口
- 函数的调用时传送数据,通过DCOM可以在不同主机间传送数据。
Windows系统编程之进程间通信
作者:北极星2003
来源:看雪论坛(www.pediy.com)
附件:windowipc.rar
Windows 的IPC(进程间通信)机制主要是异步管道和命名管道。(至于其他的IPC方式,例如内存映射、邮槽等这里就不介绍了)
管道(pipe)是用于进程间通信的共享内存区域。创建管道的进程称为管道服务器,而连接到这个管道的进程称为管道客户端。一个进程向管道写入信息,而另外一个进程从管道读取信息。
异步管道是基于字符和半双工的(即单向),一般用于程序输入输出的重定向;命名管道则强大地多,它们是面向消息和全双工的,同时还允许网络通信,用于创建客户端/服务器系统。
一、异步管道(实现比较简单,直接通过实例来讲解)
实验目标:当前有sample.cpp, sample.exe, sample.in这三个文件,sample.exe为sample.cpp的执行程序,sample.cpp只是一个简单的程序示例(简单求和),如下:
代码:
#include <iostream.h> int main() { int a, b ; while ( cin >> a >> b && ( a || b ) ) cout << a + b << endl ; return 0; }
Sample.in文件是输入文件,内容:
32 433
542 657
0 0
要求根据sample.exe和它的输入数据,把输出数据重定向到sample.out
流程分析:实际这个实验中包含两个部分,把输入数据重定向到sample.exe 和把输出数据重定向到sample.out。在命令行下可以很简单的实现这个功能“sample <sample.in >sample.out”,这个命令也是利用管道特性实现的,现在我们就根据异步管道的实现原理自己来实现这个功能。
管道是基于半双工(单向)的,这里有两个重定向的过程,显然需要创建两个管道,下面给出流程图:
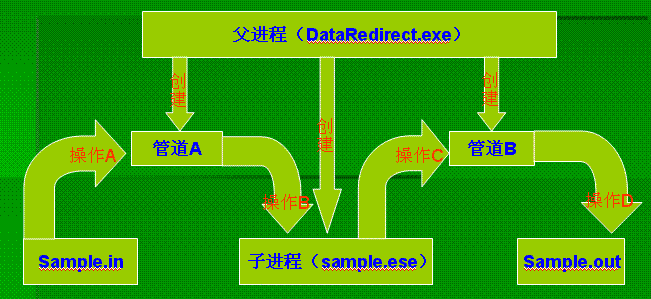
异步管道实现的流程图说明:
1)。父进程是我们需要实现的,其中需要创建管道A,管道B,和子进程,整个实现流程分为4个操作。
2)。管道A:输入管道
3)。管道B:输出管道
4)。操作A:把输入文件sample.in的数据写入输入管道(管道A)
5)。操作B:子进程从输入管道中读取数据,作为该进程的加工原料。通常,程序的输入数据由标准的输入设备输入,这里实现输入重定向,即把输入管道作为输入设备。
6)。操作C:子进程把加工后的成品(输出数据)输出到输出管道。通常,程序的输出数据会输出到标准的输出设备,一般为屏幕,这里实现输出重定向,即把输出管道作为输出设备。
7)。操作D:把输出管道的数据写入输出文件
需要注意的是,管道的本质只是一个共享的内存区域。这个实验中,管道区域处于父进程的地址空间中,父进程的作用是提供环境和资源,并协调子进程进行加工。
程序源码:
代码:
#include <windows.h> #include <iostream.h> const int BUFSIZE = 4096 ; HANDLE hChildStdinRd, hChildStdinWr, hChildStdinWrDup, hChildStdoutRd,hChildStdoutWr,hChildStdoutRdDup, hSaveStdin, hSaveStdout; BOOL CreateChildProcess(LPTSTR); VOID WriteToPipe(LPTSTR); VOID ReadFromPipe(LPTSTR); VOID ErrorExit(LPTSTR); VOID ErrMsg(LPTSTR, BOOL); void main( int argc, char *argv[] ) { // 处理输入参数 if ( argc != 4 ) return ; // 分别用来保存命令行,输入文件名(CPP/C),输出文件名(保存编译信息) LPTSTR lpProgram = new char[ strlen(argv[1]) ] ; strcpy ( lpProgram, argv[1] ) ; LPTSTR lpInputFile = new char[ strlen(argv[2]) ]; strcpy ( lpInputFile, argv[2] ) ; LPTSTR lpOutputFile = new char[ strlen(argv[3]) ] ; strcpy ( lpOutputFile, argv[3] ) ; SECURITY_ATTRIBUTES saAttr; saAttr.nLength = sizeof(SECURITY_ATTRIBUTES); saAttr.bInheritHandle = TRUE; saAttr.lpSecurityDescriptor = NULL; /************************************************ * redirecting child process's STDOUT * ************************************************/ hSaveStdout = GetStdHandle(STD_OUTPUT_HANDLE); if (! CreatePipe(&hChildStdoutRd, &hChildStdoutWr, &saAttr, 0)) ErrorExit("Stdout pipe creation failed\n"); if (! SetStdHandle(STD_OUTPUT_HANDLE, hChildStdoutWr)) ErrorExit("Redirecting STDOUT failed"); BOOL fSuccess = DuplicateHandle( GetCurrentProcess(), hChildStdoutRd, GetCurrentProcess(), &hChildStdoutRdDup , 0, FALSE, DUPLICATE_SAME_ACCESS); if( !fSuccess ) ErrorExit("DuplicateHandle failed"); CloseHandle(hChildStdoutRd); /************************************************ * redirecting child process's STDIN * ************************************************/ hSaveStdin = GetStdHandle(STD_INPUT_HANDLE); if (! CreatePipe(&hChildStdinRd, &hChildStdinWr, &saAttr, 0)) ErrorExit("Stdin pipe creation failed\n"); if (! SetStdHandle(STD_INPUT_HANDLE, hChildStdinRd)) ErrorExit("Redirecting Stdin failed"); fSuccess = DuplicateHandle( GetCurrentProcess(), hChildStdinWr, GetCurrentProcess(), &hChildStdinWrDup, 0, FALSE, DUPLICATE_SAME_ACCESS); if (! fSuccess) ErrorExit("DuplicateHandle failed"); CloseHandle(hChildStdinWr); /************************************************ * 创建子进程(即启动SAMPLE.EXE) * ************************************************/ fSuccess = CreateChildProcess( lpProgram ); if ( !fSuccess ) ErrorExit("Create process failed"); // 父进程输入输出流的还原设置 if (! SetStdHandle(STD_INPUT_HANDLE, hSaveStdin)) ErrorExit("Re-redirecting Stdin failed\n"); if (! SetStdHandle(STD_OUTPUT_HANDLE, hSaveStdout)) ErrorExit("Re-redirecting Stdout failed\n"); WriteToPipe( lpInputFile ) ; ReadFromPipe( lpOutputFile ); delete lpProgram ; delete lpInputFile ; delete lpOutputFile ; } BOOL CreateChildProcess( LPTSTR lpProgram ) { PROCESS_INFORMATION piProcInfo; STARTUPINFO siStartInfo; BOOL bFuncRetn = FALSE; ZeroMemory( &piProcInfo, sizeof(PROCESS_INFORMATION) ); ZeroMemory( &siStartInfo, sizeof(STARTUPINFO) ); siStartInfo.cb = sizeof(STARTUPINFO); bFuncRetn = CreateProcess ( NULL, lpProgram, NULL, NULL, TRUE, \ 0, NULL, NULL, &siStartInfo, &piProcInfo); if (bFuncRetn == 0) { ErrorExit("CreateProcess failed\n"); return 0; } else { CloseHandle(piProcInfo.hProcess); CloseHandle(piProcInfo.hThread); return bFuncRetn; } } VOID WriteToPipe( LPTSTR lpInputFile ) { HANDLE hInputFile = CreateFile(lpInputFile, GENERIC_READ, 0, NULL, OPEN_EXISTING, FILE_ATTRIBUTE_READONLY, NULL); if (hInputFile == INVALID_HANDLE_VALUE) return ; BOOL fSuccess ; DWORD dwRead, dwWritten; CHAR chBuf[BUFSIZE] = {0} ; for (;;) { fSuccess = ReadFile( hInputFile, chBuf, BUFSIZE, &dwRead, NULL) ; if ( !fSuccess || dwRead == 0) break; fSuccess = WriteFile( hChildStdinWrDup, chBuf, dwRead, &dwWritten, NULL) ; if ( !fSuccess ) break; } if (! CloseHandle(hChildStdinWrDup)) ErrorExit("Close pipe failed\n"); CloseHandle ( hInputFile ) ; } VOID ReadFromPipe( LPTSTR lpOutputFile ) { HANDLE hOutputFile = CreateFile( lpOutputFile, GENERIC_READ|GENERIC_WRITE, FILE_SHARE_WRITE, NULL, CREATE_ALWAYS, FILE_ATTRIBUTE_NORMAL, NULL); if (hOutputFile == INVALID_HANDLE_VALUE) return ; BOOL fSuccess ; DWORD dwRead, dwWritten; CHAR chBuf[BUFSIZE] = { 0 }; if (!CloseHandle(hChildStdoutWr)) ErrorExit("Closing handle failed"); for (;;) { fSuccess = ReadFile( hChildStdoutRdDup, chBuf, BUFSIZE, &dwRead, NULL) ; if( !fSuccess || dwRead == 0) { break; } fSuccess = WriteFile( hOutputFile, chBuf, dwRead, &dwWritten, NULL) ; if ( !fSuccess ) break; } CloseHandle ( hOutputFile ) ; } VOID ErrorExit (LPTSTR lpszMessage) { MessageBox( 0, lpszMessage, 0, 0 ); }
二、命名管道
命名管道具有以下几个特征:
(1)命名管道是双向的,所以两个进程可以通过同一管道进行交互。
(2)命名管道不但可以面向字节流,还可以面向消息,所以读取进程可以读取写进程发送的不同长度的消息。
(3)多个独立的管道实例可以用一个名称来命名。例如几个客户端可以使用名称相同的管道与同一个服务器进行并发通信。
(4)命名管道可以用于网络间两个进程的通信,而其实现的过程与本地进程通信完全一致。
实验目标:在客户端输入数据a和b,然后发送到服务器并计算a+b,然后把计算结果发送到客户端。可以多个客户端与同一个服务器并行通信。
界面设计:
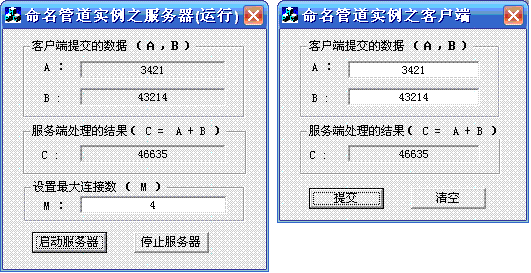
难点所在:
实现的过程比较简单,但有一个难点。原本当服务端使用ConnectNamedPipe函数后,如果有客户端连接,就可以直接进行交互。原来我在实现过程中,当管道空闲时,管道的线程函数会无限(INFINITE)阻塞。若现在需要停止服务,就必须结束所有的线程,TernimateThread可以作为一个结束线程的方法,但我基本不用这个函数。一旦使用这个函数之后,目标线程就会立即结束,但如果此时的目标线程正在操作互斥资源、内核调用、或者是操作共享DLL的全局变量,可能会出现互斥资源无法释放、内核异常等现象。这里我用重叠I/0来解决这个问题,在创建PIPE时使用FILE_FLAG_OVERLAPPED标志,这样使用ConnectNamedPipe后会立即返回,但线程的阻塞由等待函数WaitForSingleObject来实现,等待OVERLAPPED结构的事件对象被设置。
客户端主要代码:
代码:
void CMyDlg::OnSubmit() { // 打开管道 HANDLE hPipe = CreateFile("\\\\.\\Pipe\\NamedPipe", GENERIC_READ | GENERIC_WRITE, \ 0, NULL, OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL, NULL) ; if ( hPipe == INVALID_HANDLE_VALUE ) { this->MessageBox ( "打开管道失败,服务器尚未启动,或者客户端数量过多" ) ; return ; } DWORD nReadByte, nWriteByte ; char szBuf[1024] = {0} ; // 把两个整数(a,b)格式化为字符串 sprintf ( szBuf, "%d %d", this->nFirst, this->nSecond ) ; // 把数据写入管道 WriteFile ( hPipe, szBuf, strlen(szBuf), &nWriteByte, NULL ) ; memset ( szBuf, 0, sizeof(szBuf) ) ; // 读取服务器的反馈信息 ReadFile ( hPipe, szBuf, 1024, &nReadByte, NULL ) ; // 把返回信息格式化为整数 sscanf ( szBuf, "%d", &(this->nResValue) ) ; this->UpdateData ( false ) ; CloseHandle ( hPipe ) ; }
服务端主要代码:
代码:
// 启动服务 void CMyDlg::OnStart() { CString lpPipeName = "\\\\.\\Pipe\\NamedPipe" ; for ( UINT i = 0; i < nMaxConn; i++ ) { // 创建管道实例 PipeInst[i].hPipe = CreateNamedPipe ( lpPipeName, PIPE_ACCESS_DUPLEX|FILE_FLAG_OVERLAPPED, \ PIPE_TYPE_BYTE|PIPE_READMODE_BYTE|PIPE_WAIT, nMaxConn, 0, 0, 1000, NULL ) ; if ( PipeInst[i].hPipe == INVALID_HANDLE_VALUE ) { DWORD dwErrorCode = GetLastError () ; this->MessageBox ( "创建管道错误!" ) ; return ; } // 为每个管道实例创建一个事件对象,用于实现重叠IO PipeInst[i].hEvent = CreateEvent ( NULL, false, false, false ) ; // 为每个管道实例分配一个线程,用于响应客户端的请求 PipeInst[i].hTread = AfxBeginThread ( ServerThread, &PipeInst[i], THREAD_PRIORITY_NORMAL ) ; } this->SetWindowText ( "命名管道实例之服务器(运行)" ) ; this->MessageBox ( "服务启动成功" ) ; } // 停止服务 void CMyDlg::OnStop() { DWORD dwNewMode = PIPE_TYPE_BYTE|PIPE_READMODE_BYTE|PIPE_NOWAIT ; for ( UINT i = 0; i < nMaxConn; i++ ) { SetEvent ( PipeInst[i].hEvent ) ; CloseHandle ( PipeInst[i].hTread ) ; CloseHandle ( PipeInst[i].hPipe ) ; } this->SetWindowText ( "命名管道实例之服务器" ) ; this->MessageBox ( "停止启动成功" ) ; } // 线程服务函数 UINT ServerThread ( LPVOID lpParameter ) { DWORD nReadByte = 0, nWriteByte = 0, dwByte = 0 ; char szBuf[MAX_BUFFER_SIZE] = {0} ; PIPE_INSTRUCT CurPipeInst = *(PIPE_INSTRUCT*)lpParameter ; OVERLAPPED OverLapStruct = { 0, 0, 0, 0, CurPipeInst.hEvent } ; while ( true ) { memset ( szBuf, 0, sizeof(szBuf) ) ; // 命名管道的连接函数,等待客户端的连接(只针对NT) ConnectNamedPipe ( CurPipeInst.hPipe, &OverLapStruct ) ; // 实现重叠I/0,等待OVERLAPPED结构的事件对象 WaitForSingleObject ( CurPipeInst.hEvent, INFINITE ) ; // 检测I/0是否已经完成,如果未完成,意味着该事件对象是人工设置,即服务需要停止 if ( !GetOverlappedResult ( CurPipeInst.hPipe, &OverLapStruct, &dwByte, true ) ) break ; // 从管道中读取客户端的请求信息 if ( !ReadFile ( CurPipeInst.hPipe, szBuf, MAX_BUFFER_SIZE, &nReadByte, NULL ) ) { MessageBox ( 0, "读取管道错误!", 0, 0 ) ; break ; } int a, b ; sscanf ( szBuf, "%d %d", &a, &b ) ; pMyDlg->nFirst = a ; pMyDlg->nSecond = b ; pMyDlg->nResValue = a + b ; memset ( szBuf, 0, sizeof(szBuf) ) ; sprintf ( szBuf, "%d", pMyDlg->nResValue ) ; // 把反馈信息写入管道 WriteFile ( CurPipeInst.hPipe, szBuf, strlen(szBuf), &nWriteByte, NULL ) ; pMyDlg->SetDlgItemInt ( IDC_FIRST, a, true ) ; pMyDlg->SetDlgItemInt ( IDC_SECOND, b, true ) ; pMyDlg->SetDlgItemInt ( IDC_RESULT, pMyDlg->nResValue, true ) ; // 断开客户端的连接,以便等待下一客户的到来 DisconnectNamedPipe ( CurPipeInst.hPipe ) ; } return 0 ; }
漫谈兼容内核之十六:Windows的进程间通信
对于任何一个现代的操作系统,进程间通信都是其系统结构的一个重要组成部分。而说到Windows的进程(线程)间通信,那就要看是在什么意义上说了。因为正如“Windows的跨进程操作”那篇漫谈中所述,在Windows上一个进程甚至可以“打开”另一个进程,并在对方的用户空间分配内存、再把程序或数据拷贝过去,最后还可以在目标进程中创建一个线程、让它为所欲为。显然,这已经不只是进程间的“通信”,而是进程间“操纵”了。但是这毕竟属于另类,我们在这里要谈论的是“正规”的进程间通信。
不管是两个甚么样的实体,凡是要通信就得满足一个必要条件,那就是存在双方都可以访问的介质。顾名思义,进程间通信就是在不同进程之间传播或交换信息,那么不同进程之间存在着什么双方都可以访问的介质呢?进程的用户空间是互相独立的,一般而言是不能互相访问的,唯一的例外是共享内存区。但是,系统空间却是“公共场所”,所以内核显然可以提供这样的条件。除此以外,那就是双方都可以访问的外设了。在这个意义上,两个进程当然也可以通过磁盘上的普通文件交换信息,或者通过“注册表”或其它数据库中的某些表项和记录交换信息。广义上这也是进程间通信的手段,但是一般都不把这算作“进程间通信”。因为那些通信手段的效率太低了,而人们对进程间通信的要求是要有一定的实时性。
但是,对于实际的应用而言,光有信息传播的实时性往往还不够。不妨以共享内存区(Section)为例来说明这个问题。共享内存区显然可以用作进程间通信的手段,两个进程把同一组物理内存页面分别映射到自己的用户空间,然后一个进程往里面写,另一个进程就可以读到所写入的内容。从信息传播的角度看,这个过程是“即时”的,有着很高的实时性,但是读取者怎么知道写入者已经写入了一些数据呢?要是共享内存区的物理页面能产生中断请求就好了,可是它不能。让读取者轮询、或者定时轮询、那当然也可以,但是效率就降下来了。所以,这里还需要有通信双方行为上的协调、或称进程间的“同步”。注意所谓“同步”并不是说双方应该同时读或同时写,而是让双方的行为得以有序、紧凑地进行。
综上所述,一般所说的“进程间通信”其实是狭义的、带限制条件的。总的来说,对于进程间通信有三方面的要求:
l 具有不同进程之间传播或交换信息的手段
l 进程间传播或交换信息的手段应具有一定程度的实时性
l 具有进程间的协调(同步)机制。
此外,“进程间通信”一般是指同一台机器上的进程间通信。通过网络或通信链路进行的跨主机的通信一般不归入进程间通信的范畴,虽然这种通信通常也确实是发生于进程之间。不过网络通信往往也可以作用于本机的不同进程之间,这里并没有明确的界线。这样一来范围就广了,所以本文在介绍Windows的进程间通信时以其内核是否专门为具体的机制提供了系统调用为准。这样,例如用于网络通信的Winsock机制是作为设备驱动实现的,内核并没有为此提供专门的系统调用,所以本文就不把它算作进程间通信。
先看上面三方面要求的第一项,即同一机器上的不同进程之间传播或交换信息的手段,这无非就是几种可能:
l 通过用户空间的共享内存区。
l 通过内核中的变量、数据结构、或缓冲区。
l 通过外设的存储效应。但是一般所讲操作系统内核的“进程间通信”机制都把这排除在外。
由于通过外设进行的进程间通信一般而言实时性不是很好,所以考虑到上述第二方面的要求就把它给排除掉了。
再看进程间的同步机制。如前所述,进程间同步的目的是要让通信的双方(或多方) 行为得以有序、紧凑地进行。所以本质上就是双方(或多方)之间的等待(睡眠)/唤醒机制,这就是为什么要在上一篇漫谈中先介绍等待/唤醒机制的原因。注意这里的“等待”意味着主动进入睡眠,一般而言,所谓“进程间同步”就是建立在(主动)睡眠/唤醒机制基础上的同步。不主动进入睡眠的同步也是有的,例如“空转锁(Spinlock)”就是,但是那样太浪费CPU资源了。再说,在单CPU的系统中,如果是在调度禁区中使用Spinlock,还会引起死锁。所以,一般不把Spinlock算作进程间同步手段。在操作系统理论中,“信号量(Semaphore)”是基本的进程间同步机制,别的大都是在此基础上派生出来的。
另一方面,进程间同步的实现本身就需要有进程间的信息传递作为基础,例如“唤醒”这个动作就蕴含着信息的传递。所以,进程间同步其实也是进程间通信,只不过是信息量比较小、或者很小的进程间通信。换言之,带有进程间同步的进程间通信,实际上就是先以少量信息的传递使双方的行为得到协调,再在此基础上交换比较大量的信息。如果需要传递的信息量本来就很小,那么这里的第二步也就不需要了。所以,进程间同步就是(特殊的)进程间通信。
注意这里所说的进程间通信实际上是线程间通信,特别是分属于不同进程的线程之间的通信。因为在Windows中线程才是运行的实体,而进程不是。但是上述的原理同样适用于同一进程内部的线程间通信。属于同一进程的线程共享同一个用户空间,所以整个用户空间都成了共享内存区。如果两个线程都访问同一个变量或数据结构,那么实际上就构成了线程间通信(或许是在不知不觉间)。这里仍有双方如何同步的问题,但是既然是共享用户空间,就有可能在用户空间构筑这样的同步机制。所以,一般而言,进程间通信需要内核的支持,而同一进程中的线程间通信则也可以在用户空间(例如在DLL中)实现。在下面的叙述中,“进程间通信”和“线程间通信”这两个词常常是混用的,读者应注意领会。
Windows内核所支持的进程间通信手段有:
l 共享内存区(Section)。
l 信号量(Semaphore)。
l 互斥门(Mutant)。
l 事件(Event)。
l 特殊文件“命名管道(Named Pipe)”和“信箱(Mail Slot)”。
此外,本地过程调用、即LPC,虽然并非以进程间通信机制的面貌出现,实际上却是建立在进程间通信的基础上,并且本身就是一种独特的进程间通信机制。还有,Windows的Win32K模块提供了一种线程之间的报文传递机制,一般用作“窗口”之间的通信手段,显然也应算作进程间通信,只不过这是由Win32K的“扩充系统调用”支持的,而并非由基本的系统调用所支持。所以,还应增加以下两项。
l 端口(Port)和本地过程调用(LPC)。
l 报文(Message)。
注:“Undocumented Windows 2000 Secrets”书中还列出了另一组用于“通道(Channel)”的系统调用,例如NtOpenChannel()、NtListenChannel()、NtSendWaitReplyChannel()等等,从这些系统调用函数名看来,这应该也是一种进程间通信机制,但是“Windows NT/2000 Native API Reference”书中说这些函数均未实现,调用后只是返回出错代码“STATUS_NOT_IMPLEMENTED”,“Microsoft Windows Internals”书中则并未提及。在ReactOS的代码中也未见实现。
下面逐一作些介绍。
1. 共享内存区(Section)
如前所述,共享内存区是可以用于进程间通信的。但是,离开进程间同步机制,它的效率就不会高,所以共享内存区单独使用并不是一种有效的进程间通信机制。
使用的方法是:先以双方约定的名字创建一个Section对象,各自加以打开,再各自将其映射到自己的用户空间,然后就可以通过常规的内存读写(例如通过指针)进行通信了。
要通过共享内存区进行通信时,首先要通过NtCreateSection()创建一个共享内存区对象。从程序的结构看,几乎所有对象的创建、即所有形似NtCreateXYZ()的函数的代码都是基本相同的,所以下面列出NtCreateSection()的代码,以后对类似的代码就不再列出了。
[code]NTSTATUS STDCALL
NtCreateSection (OUT PHANDLE SectionHandle,
IN ACCESS_MASK DesiredAccess,
IN POBJECT_ATTRIBUTES ObjectAttributes OPTIONAL,
IN PLARGE_INTEGER MaximumSize OPTIONAL,
IN ULONG SectionPageProtection OPTIONAL,
IN ULONG AllocationAttributes,
IN HANDLE FileHandle OPTIONAL)
{
. . . . . .
PreviousMode = ExGetPreviousMode();
if(MaximumSize != NULL && PreviousMode != KernelMode)
{
_SEH_TRY
{
ProbeForRead(MaximumSize,
sizeof(LARGE_INTEGER),
sizeof(ULONG));
/* make a copy on the stack */
SafeMaximumSize = *MaximumSize;
MaximumSize = &SafeMaximumSize;
}
_SEH_HANDLE
{
Status = _SEH_GetExceptionCode();
}
_SEH_END;
if(!NT_SUCCESS(Status))
{
return Status;
}
}
/*
* Check the protection
*/
if ((SectionPageProtection & PAGE_FLAGS_VALID_FROM_USER_MODE) !=
SectionPageProtection)
{
return(STATUS_INVALID_PAGE_PROTECTION);
}
Status = MmCreateSection(&SectionObject, DesiredAccess, ObjectAttributes,
MaximumSize, SectionPageProtection,
AllocationAttributes, FileHandle, NULL);
if (NT_SUCCESS(Status))
{
Status = ObInsertObject ((PVOID)SectionObject, NULL,
DesiredAccess, 0, NULL, SectionHandle);
ObDereferenceObject(SectionObject);
}
return Status;
}[/code]
虽然名曰“Create”,实际上却是“创建并打开”,参数SectionHandle就是用来返回打开后的Handle。参数DesiredAccess说明所创建的对象允许什么样的访问,例如读、写等等。ObjectAttributes则说明对象的名称,打开以后是否允许遗传,以及与对象保护有关的特性、例如访问权限等等。这几个参数对于任何对象的创建都一样,而其余几个参数就是专为共享内存区的特殊需要而设的了。其中MaximumSize当然是共享内存区大小的上限,而SectionPageProtection与页面的保护有关。AllocationAttributes通过一些标志位说明共享区的性质和用途,例如可执行映像或数据文件。最后,共享缓冲区往往都是以磁盘文件作为后盾的,为此需要先创建或打开相应的文件,然后把FileHandle作为参数传给NtCreateSection()。不过用于进程间通信的共享内存区是空白页面,其内容并非来自某个文件,所以FileHandle为NULL。
显然,创建共享内存区的实质性操作是由MmCreateSection()完成的。对于其它的对象,往往也都有类似的函数。我们看一下MmCreateSection()的代码:
[code][NtCreateSection() > MmCreateSection()]
NTSTATUS STDCALL
MmCreateSection (OUT PSECTION_OBJECT * SectionObject,
IN ACCESS_MASK DesiredAccess,
IN POBJECT_ATTRIBUTES ObjectAttributes OPTIONAL,
IN PLARGE_INTEGER MaximumSize,
IN ULONG SectionPageProtection,
IN ULONG AllocationAttributes,
IN HANDLE FileHandle OPTIONAL,
IN PFILE_OBJECT File OPTIONAL)
{
if (AllocationAttributes & SEC_IMAGE)
{
return(MmCreateImageSection(SectionObject, DesiredAccess, ObjectAttributes,
MaximumSize, SectionPageProtection,
AllocationAttributes, FileHandle));
}
if (FileHandle != NULL)
{
return(MmCreateDataFileSection(SectionObject, DesiredAccess, ObjectAttributes,
MaximumSize, SectionPageProtection,
AllocationAttributes, FileHandle));
}
return(MmCreatePageFileSection(SectionObject, DesiredAccess, ObjectAttributes,
MaximumSize, SectionPageProtection, AllocationAttributes));
}[/code]
参数AllocationAttributes中的SEC_IMAGE标志位为1表示共享内存区的内容是可执行映像(因而必需符合可执行映像的头部结构)。而FileHandle为1表示共享内存区的内容来自文件,既然不是可执行映像那就是数据文件了;否则就并非来自文件,那就是用于进程间通信的空白页面了。最后一个参数File的用途不明,似乎并无必要。我们现在关心的是空白页面的共享内存区,具体的对象是由MmCreatePageFileSection()创建的,我们就不往下看了。注意这里还不涉及共享内存区的地址,因为尚未映射。
参与通信的双方通过同一个共享内存区进行通信,所以不能各建各的共享内存区,至少有一方需要打开已经创建的共享内存区,这是通过NtOpenSection()完成的:
[code]NTSTATUS STDCALL
NtOpenSection(PHANDLE SectionHandle,
ACCESS_MASK DesiredAccess,
POBJECT_ATTRIBUTES ObjectAttributes)
{
HANDLE hSection;
KPROCESSOR_MODE PreviousMode;
NTSTATUS Status = STATUS_SUCCESS;
PreviousMode = ExGetPreviousMode();
if(PreviousMode != KernelMode)
{
_SEH_TRY. . . . . . _SEH_END;
}
Status = ObOpenObjectByName(ObjectAttributes, MmSectionObjectType,
NULL, PreviousMode, DesiredAccess,
NULL, &hSection);
if(NT_SUCCESS(Status))
{
_SEH_TRY
{
*SectionHandle = hSection;
}
_SEH_HANDLE
{
Status = _SEH_GetExceptionCode();
}
_SEH_END;
}
return(Status);
}[/code]
这里实质性的操作是ObOpenObjectByName(),读者想必已经熟悉。
双方都打开了一个共享内存区对象以后,就可以各自通过NtMapViewOfSection()将其映射到自己的用户空间。
[code]NTSTATUS STDCALL
NtMapViewOfSection(IN HANDLE SectionHandle,
IN HANDLE ProcessHandle,
IN OUT PVOID* BaseAddress OPTIONAL,
IN ULONG ZeroBits OPTIONAL,
IN ULONG CommitSize,
IN OUT PLARGE_INTEGER SectionOffset OPTIONAL,
IN OUT PULONG ViewSize,
IN SECTION_INHERIT InheritDisposition,
IN ULONG AllocationType OPTIONAL,
IN ULONG Protect)
{
. . . . . .
PreviousMode = ExGetPreviousMode();
if(PreviousMode != KernelMode)
{
SafeBaseAddress = NULL;
SafeSectionOffset.QuadPart = 0;
SafeViewSize = 0;
_SEH_TRY. . . . . . _SEH_END;
. . . . . .
}
else
{
SafeBaseAddress = (BaseAddress != NULL ? *BaseAddress : NULL);
SafeSectionOffset.QuadPart = (SectionOffset != NULL ? SectionOffset->QuadPart : 0);
SafeViewSize = (ViewSize != NULL ? *ViewSize : 0);
}
Status = ObReferenceObjectByHandle(ProcessHandle,
PROCESS_VM_OPERATION,
PsProcessType,
PreviousMode,
(PVOID*)(PVOID)&Process,
NULL);
. . . . . .
AddressSpace = &Process->AddressSpace;
Status = ObReferenceObjectByHandle(SectionHandle,
SECTION_MAP_READ,
MmSectionObjectType,
PreviousMode,
(PVOID*)(PVOID)&Section,
NULL);
. . . . . .
Status = MmMapViewOfSection(Section, Process,
(BaseAddress != NULL ? &SafeBaseAddress : NULL),
ZeroBits, CommitSize,
(SectionOffset != NULL ? &SafeSectionOffset : NULL),
(ViewSize != NULL ? &SafeViewSize : NULL),
InheritDisposition, AllocationType, Protect);
ObDereferenceObject(Section);
ObDereferenceObject(Process);
. . . . . .
return(Status);
}[/code]
以前讲过,NtMapViewOfSection()并不是专为当前进程的,而是可以用于任何已打开的进程,所以参数中既有共享内存区对象的Handle,又有进程对象的Handle。从这个意义上说,两个进程之间通过共享内存区的通信完全可以由第三方撮合、包办而成,但是一般还是由通信双方自己加以映射的。显然,这里实质性的操作是MmMapViewOfSection(),那是存储管理底层的事了,我们就不再追究下去了。
一旦把同一个共享内存区映射到了通信双方的用户空间(可能在不同的地址上),出现在这双方用户空间的特定地址区间就落实到了同一组物理页面。这样,一方往里面写的内容就可以为另一方所见,于是就可以通过普通的内存访问(例如通过指针)实现进程间通信了。
但是,如前所述,通过共享内存区实现的只是原始的、低效的进程间通信,因为共享内存区只满足了前述三个条件中的两个,只是提供了信息的(实时)传输,但是却缺乏进程间的同步。所以实际使用时需要或者结合别的进程间通信(同步)手段,或者由应用程序自己设法实现同步(例如定时查询)。
2. 信号量(Semaphore)
学过操作系统原理的读者想必知道“临界区”和“信号量”、以及二者之间的关系。如果没有学过,那也不要紧,不妨把临界区想像成一个凭通行证入内的工作场所,作为对象存在的“信号量”则是发放通行证的“票务处”。但是,通行证的数量是有限的,一般只有寥寥几张。一旦发完,想要领票的进程(线程)就只好睡眠等待,直到已经在里面干活的进程(线程)完成了操作以后退出临界区并交还通行证,才会被唤醒并领到通行证进入临界区。之所以称之为(翻译为)“信号量”,是因为“票务处”必须维持一个数值,表明当前手头还有几张通行证,这就是作为数值的“信号量”。所以,“信号量”是一个对象,对象中有个数值,而信号量这个名称就是因这个数值而来。那么,为什么要到临界区里面去进行某些操作呢?一般是因为这些操作不允许受到干扰,必须排它地进行,或者说有互斥要求。
在操作系统理论中,“领票”操作称为P操作,具体的操作如下:
l 递减信号量的数值。
l 如果递减后大于或等于0就说明领到了通行证,因而就进入了临界区,可以接着进行想要做的操作了。
l 反之如果递减后小于0,则说明通行证已经发完,当前线程只好(主动)在临界区的大门口睡眠,直至有通行证可发时才被唤醒。
l 如果信号量的数值小于0,那么其绝对值表明正在睡眠等待的线程个数。
领到票进入了临界区的线程,在完成了操作以后应从临界区退出、并交还通行证,这个操作称为V操作,具体的操作如下:
l 递增信号量的数值。
l 如果递增以后的数值小于等于0,就说明有进程正在等待,因而需要加以唤醒。
这里,执行了P操作的进程稍后就会执行V操作,但是也可以把这两种操作分开来,让有的进程光执行V操作,另一些进程则光执行P操作。于是,这两种进程就成了供应者/消费者的关系,前者是供应者,后者是消费者,而信号量的P/V操作正好可以被用作进程间的睡眠/唤醒机制。例如,假定最初时“通行证”的数量为0,并把它理解为筹码。每当写入方在共享内存区中写入数据以后就对信号量执行一次V操作,而每当读出方想要读出新的数据时就先执行一次P操作。所以,许多别的进程间同步机制其实只是“信号量”的变种,是由“信号量”派生、演变而来的。
注意在条件不具备时进入睡眠、以及在条件具备时加以唤醒,是P操作和V操作固有的一部分,否则就退化成对于标志位或数值的测试和设置了。当然,“测试和设置”也是进程间同步的手段之一,但是那只相当于轮询,一般而言效率是很低的。所以,离开(睡眠)等待和唤醒,就不足于构成高效的进程间通信机制。但是也有例外,那就是如果能肯定所等待的条件在一个很短的时间内一定会得到满足,那就不妨不断地反复测试直至成功,这就是“空转锁(SpinLock)”的来历。不过空转锁一般只是在内核中使用,而不提供给用户空间。
信号量对象的创建和打开是由NtCreateSemaphore()和NtOpenSemaphore()实现的,我们看一下NtCreateSemaphore():
[code]NTSTATUS
STDCALL
NtCreateSemaphore(OUT PHANDLE SemaphoreHandle,
IN ACCESS_MASK DesiredAccess,
IN POBJECT_ATTRIBUTES ObjectAttributes OPTIONAL,
IN LONG InitialCount,
IN LONG MaximumCount)
{
. . . . . .
KPROCESSOR_MODE PreviousMode = ExGetPreviousMode();
. . . . . .
if(PreviousMode != KernelMode) {
_SEH_TRY . . . . . ._SEH_END;
if(!NT_SUCCESS(Status)) return Status;
}
. . . . . .
/* Create the Semaphore Object */
Status = ObCreateObject(PreviousMode, ExSemaphoreObjectType,
ObjectAttributes, PreviousMode, NULL,
sizeof(KSEMAPHORE), 0, 0, (PVOID*)&Semaphore);
/* Check for Success */
if (NT_SUCCESS(Status)) {
/* Initialize it */
KeInitializeSemaphore(Semaphore, InitialCount, MaximumCount);
/* Insert it into the Object Tree */
Status = ObInsertObject((PVOID)Semaphore, NULL,
DesiredAccess, 0, NULL, &hSemaphore);
ObDereferenceObject(Semaphore);
/* Check for success and return handle */
if(NT_SUCCESS(Status)) {
_SEH_TRY . . . . . ._SEH_END;
}
}
/* Return Status */
return Status;
}[/code]
这个函数可以说是对象创建函数的样板(Template)。一般而言,创建对象的过程总是涉及三步主要操作:
1. 通过ObCreateObject()创建对象,对象的类型代码决定了具体的对象种类。对于信号量,这个类型代码是ExSemaphoreObjectType。所创建的对象被挂入内核中该种类型的对象队列(类似于文件系统的目录),以备别的进程打开。这个函数返回一个指向具体对象数据结构的指针,数据结构的类型取决于对象的类型代码。
2. 类似于KeInitializeSemaphore()那样的初始化函数,对所创建对象的数据结构进行初始化。
3. 通过ObInsertObject()将所创建对象的数据结构指针填入当前进程的打开对象表,并返回相应的Handle。所以,创建对象实际上是创建并打开一个对象。
对于信号量,ObCreateObject()返回的是KSEMAPHORE数据结构指针:
[code]typedef struct _KSEMAPHORE {
DISPATCHER_HEADER Header;
LONG Limit;
} KSEMAPHORE, *PKSEMAPHORE, *RESTRICTED_POINTER PRKSEMAPHORE;[/code]
这里的Limit是信号量数值的上限,来自前面的调用参数MaximumCount。而参数InitialCount的数值、即信号量的初值,则记录在DISPATCHER_HEADER内的SignalState字段中。所以,信号量对象将其头部的SignalState字段用作了“信号量”。
NtOpenSemaphore()的代码就不看了,所有的打开对象操作都是一样的,基本上就是通过内核函数ObOpenObjectByName()根据对象名(路径名)找到目标对象,然后将它的数据结构指针填入本进程的打开对象表,并返回相应的Handle。
读者可能已经在急切想要知道信号量的P/V操作是怎么实现的。也许会使读者感到意外,Windows并没有专为信号量的P操作而设的系统调用,信号量的P操作就是通过NtWaitForSingleObject()或NtWaitForMultipleObjects()实现的。事实上,所有与P操作类似、会使调用者阻塞的操作都是由这两个函数实现的。读者已经在上一篇漫谈中看过NtWaitForSingleObject()的代码,这里就不重复了。
信号量的V操作倒是有专门的系统调用,那就是NtReleaseSemaphore()。
[code]NTSTATUS
STDCALL
NtReleaseSemaphore(IN HANDLE SemaphoreHandle,
IN LONG ReleaseCount,
OUT PLONG PreviousCount OPTIONAL)
{
KPROCESSOR_MODE PreviousMode = ExGetPreviousMode();
. . . . . .
if(PreviousCount != NULL && PreviousMode == UserMode) {
_SEH_TRY . . . . . ._SEH_END;
if(!NT_SUCCESS(Status)) return Status;
}
. . . . . .
/* Get the Object */
Status = ObReferenceObjectByHandle(SemaphoreHandle,
SEMAPHORE_MODIFY_STATE,
ExSemaphoreObjectType, PreviousMode,
(PVOID*)&Semaphore, NULL);
/* Check for success */
if (NT_SUCCESS(Status)) {
/* Release the semaphore */
LONG PrevCount = KeReleaseSemaphore(Semaphore, IO_NO_INCREMENT,
ReleaseCount, FALSE);
ObDereferenceObject(Semaphore);
/* Return it */
if(PreviousCount) {
_SEH_TRY . . . . . ._SEH_END;
}
}
/* Return Status */
return Status;
}[/code]
此类函数都是先调用ObReferenceObjectByHandle(),以取得指向目标对象数据结构的指针,然后就对此数据结构执行具体对象类型的具体操作,在这里是KeReleaseSemaphore()。
常规的V操作只使信号量加1,可以理解为只提供一张通行证,而KeReleaseSemaphore()则对此作了推广,可以使信号量加N,即同时提供好几张通行证,参数ReleaseCount就是这个增量,而PreviousCount则用来返回原来(V操作之前)的信号量数值。这里的常数IO_NO_INCREMENT定义为0,表示不需要提高被唤醒进程的调度优先级。
[code][NtReleaseSemaphore() > KeReleaseSemaphore()]
LONG STDCALL
KeReleaseSemaphore(PKSEMAPHORE Semaphore,
KPRIORITY Increment,
LONG Adjustment,
BOOLEAN Wait)
{
ULONG InitialState;
KIRQL OldIrql;
PKTHREAD CurrentThread;
. . . . . .
/* Lock the Dispatcher Database */
OldIrql = KeAcquireDispatcherDatabaseLock();
/* Save the Old State */
InitialState = Semaphore->Header.SignalState;
/* Check if the Limit was exceeded */
if (Semaphore->Limit < (LONG) InitialState + Adjustment ||
InitialState > InitialState + Adjustment) {
/* Raise an error if it was exceeded */
KeReleaseDispatcherDatabaseLock(OldIrql);
ExRaiseStatus(STATUS_SEMAPHORE_LIMIT_EXCEEDED);
}
/* Now set the new state */
Semaphore->Header.SignalState += Adjustment;
/* Check if we should wake it */
if (InitialState == 0 && !IsListEmpty(&Semaphore->Header.WaitListHead)) {
/* Wake the Semaphore */
KiWaitTest(&Semaphore->Header, Increment);
}
/* If the Wait is true, then return with a Wait and don't unlock the Dispatcher Database */
if (Wait == FALSE) {
/* Release the Lock */
KeReleaseDispatcherDatabaseLock(OldIrql);
} else {
/* Set a wait */
CurrentThread = KeGetCurrentThread();
CurrentThread->WaitNext = TRUE;
CurrentThread->WaitIrql = OldIrql;
}
/* Return the previous state */
return InitialState;
}[/code]
参数Adjustment就是信号量数值的增量,另一个参数Increment如为非0则表示要为被唤醒的线程暂时增加一些调度优先级,使其尽快得到运行的机会。还有个参数Wait的作用下面就会讲到。
程序中KeAcquireDispatcherDatabaseLock()的作用是提升程序的运行级别(称为IRQL,以后在别的漫谈中会讲到这个问题),以禁止线程调度,直至执行与之配对的函数KeReleaseDispatcherDatabaseLock()为止。这样,在这两个函数调用之间就形成了一个“调度禁区”。可是我们从代码中看到,KeReleaseDispatcherDatabaseLock()之是否执行实际上取决于参数Wait。这是为什么呢?我在上一篇漫谈中讲到,在Windows中,当一个线程要在某个或某几个对象上等待某些事态的发生时,有两个系统调用可资调用,一个是NtWaitForSingleObject(),另一个是NtWaitForMultipleObjects()。可是其实还有一个,就是NtSignalAndWaitForSingleObject(),只是这个系统调用有些特殊。正如其函数名所示,这个系统调用一方面是“Signal”一个对象,就是对其执行类似于KeReleaseSemaphore()这样的操作;另一方面自己又立即在另一个对象上等待,类似于执行NtWaitForSingleObject();而且这二者应该是一气呵成的。这样就来了问题,如果在KeReleaseSemaphore()一类的函数中一律调用KeReleaseDispatcherDatabaseLock(),然后在NtWaitForSingleObject()中又调用KeAcquireDispatcherDatabaseLock(),那么在此二者之间就有个间隙,在此间隙中是可以发生线程调度的。再说,从程序效率的角度,那样不必要地(且不说有害)来回折腾,也是不可取的,理应加以优化。像现在这样有条件地执行KeReleaseDispatcherDatabaseLock(),就避免了这个问题。
对信号量本身的操作倒很简单,就是改变Semaphore->Header.SignalState的数值。同时,如果有线程在睡眠等待(队列非空),并且此前信号量的数值是0,那么既然现在退还了若干张通行证(增加了信号量的数值),就可以放几个正在等待的进程进入临界区了,所以通过KiWaitTest()唤醒等待中的进程。至于KiWaitTest(),读者在上一篇漫谈中已经看过它的代码了。注意这里对于睡眠/唤醒的处理与传统的P/V操作略有些不同。在传统的P操作中,每执行一次P操作、不管能否进入临界区、都使信号量的值递减,所以信号量可以有负值,而且此时其绝对值就是正在睡眠等待的进程的数量。另一方面,当事进程之能否进入临界区也是按递减了以后的信号量数值判定的。而在NtWaitForSingleObject()、KiIsObjectSignaled()、KiSatisfyObjectWait()、以及KiWaitTest()的代码中,则当事进程只有在信号量大于0时才能获准进入临界区,这样的P操作才使信号量的值递减,否则当事进程就被挂入等待队列并进入睡眠,因此信号量不会有负值。所以,NtWaitForSingleObject()是变了形的P操作。
如前所述,信号量既可以用来实现临界区,也可以使进程(线程)之间形成供应者/消费者的关系和互动。所以,虽然从表面上看信号量操作本身并不携带数据,但是它为高效的进程间通信提供了同步手段。另一方面,进程间同步也蕴含着信息的交换,也属于进程间通信的范畴,所以信号量同时又是一种进程间通信机制。
3. 互斥门(Mutant)
互斥门(Mutant,又称Mutex,实现于内核中称Mutant,实现于用户空间称Mutex)是“信号量”的一个特例和变种。在信号量机制中,如果把信号量的最大值和初始值都设置成1,就成了互斥门。把信号量的最大值和初始值都设置成1,就相当于一共只有一张通行证,自然就只能有一个线程可以进入临界区;在它退出临界区之前,别的线程想要进入临界区就只好在大门口睡眠等候。所谓“互斥”,就是因此而来。我的朋友胡希明老师曾把这样的临界区比作列车上的厕所(当时他常坐火车出差,想必屡屡为此所苦),二十多年过去了,当年的学生聚在一起还会因此事津津乐道。
不过,倘若纯粹就是两个参数的事,那就没有必要另搞一套了。事实上互斥门机制有一些特殊性,下面读者就会看到。
为互斥门的创建和打开提供了NtCreateMutant()和NtOpenMutant()两个系统调用,代码就不用看了。下面是互斥门对象的数据结构:
[code]typedef struct _KMUTANT {
DISPATCHER_HEADER Header;
LIST_ENTRY MutantListEntry;
struct _KTHREAD *RESTRICTED_POINTER OwnerThread;
BOOLEAN Abandoned;
UCHAR ApcDisable;
} KMUTANT, *PKMUTANT, KMUTEX, *PKMUTEX;[/code]
这个数据结构的定义见之于Windows NT的DDK,所以是“正宗”的。可见,这数据结构就与信号量对象的不同。
跟信号量机制一样,请求(试图)通过互斥门进入临界区的操作就是系统调用NtWaitForSingleObject()或NtWaitForMultipleObjects()。不过,在NtWaitForSingleObject()内部,特别是在判定能否进入临界区时所调用的函数KiIsObjectSignaled()中,其实是按不同的对象类型分别处置的。我们不妨看一下。
[code][NtWaitForSingleObject() > KeWaitForSingleObject() > KiIsObjectSignaled()]
BOOLEAN inline FASTCALL
KiIsObjectSignaled(PDISPATCHER_HEADER Object, PKTHREAD Thread)
{
/* Mutants are...well...mutants! */
if (Object->Type == MutantObject) {
/*
* Because Cutler hates mutants, they are actually signaled if the Signal State is <= 0
* Well, only if they are recursivly acquired (i.e if we own it right now).
* Of course, they are also signaled if their signal state is 1.
*/
if ((Object->SignalState <= 0 && ((PKMUTANT)Object)->OwnerThread == Thread) ||
(Object->SignalState == 1)) {
/* Signaled Mutant */
return (TRUE);
} else {
/* Unsignaled Mutant */
return (FALSE);
}
}
/* Any other object is not a mutated freak, so let's use logic */
return (!Object->SignalState <= 0);
}[/code]
可见,互斥门在这里是作为一种特殊情况处理的,使KiIsObjectSignaled()返回TRUE、从而允许当事进程进入临界区的条件之一是SignalState为1。另一个条件表明,只要是互斥门对象当前的“业主(Owner)”,就不受这个限制,即使没有通行证也可以进入。那么谁是互斥门对象当前的业主呢?那就是当前已经在此临界区中的线程,这一点读者看了下面的代码就会清楚。可是既然是已经在临界区中的线程,怎么又会企图通过同一个互斥门进入同一个临界区呢?这意味着一个线程可能递归地多次通过同一个互斥门。这个问题先搁一下,等一下再来探讨。
在上一篇漫谈中,我们看了KeWaitForSingleObject()的代码,这是NtWaitForSingleObject()的主体,正是这个函数调用了KiIsObjectSignaled()。如果KiIsObjectSignaled()返回TRUE,那就说明当前进程可以领到通行证而进入临界区,此时需要执行KiSatisfyObjectWait(),一方面是进行“账面”上的处理,一方面也还有一些附加的操作需要进行,而这些附加的操作是因具体的对象而异的。我们再重温一下这个函数的代码。
[code][NtWaitForSingleObject() > KeWaitForSingleObject() > KiSatisfyObjectWait()]
VOID FASTCALL
KiSatisfyObjectWait(PDISPATCHER_HEADER Object, PKTHREAD Thread)
{
/* Special case for Mutants */
if (Object->Type == MutantObject) {
/* Decrease the Signal State */
Object->SignalState--;
/* Check if it's now non-signaled */
if (Object->SignalState == 0) {
/* Set the Owner Thread */
((PKMUTANT)Object)->OwnerThread = Thread;
/* Disable APCs if needed */
Thread->KernelApcDisable -= ((PKMUTANT)Object)->ApcDisable;
/* Check if it's abandoned */
if (((PKMUTANT)Object)->Abandoned) {
/* Unabandon it */
((PKMUTANT)Object)->Abandoned = FALSE;
/* Return Status */
Thread->WaitStatus = STATUS_ABANDONED;
}
/* Insert it into the Mutant List */
InsertHeadList(&Thread->MutantListHead,
&((PKMUTANT)Object)->MutantListEntry);
}
} else if ((Object->Type & TIMER_OR_EVENT_TYPE) == EventSynchronizationObject) {
/* These guys (Syncronization Timers and Events) just get un-signaled */
Object->SignalState = 0;
} else if (Object->Type == SemaphoreObject) {
/* These ones can have multiple signalings, so we only decrease it */
Object->SignalState--;
}
}[/code]
我们只看对于互斥门对象的处理。首先是递减SignalState,这就是所谓“账面”上的处理,也是P操作的一部分。由于前面已经通过KiIsObjectSignaled()进行过试探,如果当时的SignalState数值为1,或者说如果当时的临界区是空的,那么现在的SignalState数值必定变成了0。所以,下面if语句中的代码是在一个线程首次进入一个互斥门时执行的。这里说的“首次进入”并不是指退出以后又进去那样的反复进出中的首次,而是指嵌套多次进入中的首次。当一个线程首次顺利进入互斥门时,它就成了这个互斥门当前的业主,直至退出;所以把互斥门数据结构中的OwnerThread字段设置成指向当前线程的KTHREAD数据结构。此外,如果Abandoned字段显示这个互斥门行将被丢弃,则暂时将其改成继续使用(因为又有线程进来了),但是把这情况记录在当前线程的KTHREAD数据结构中。互斥门数据结构中的ApcDisable字段表明通过互斥门进入临界区的线程是否需要关闭APC请求,现在当前进程通过了互斥门,所以要把这信息记录在它的数据结构中。注意这里是从Thread->KernelApcDisable的数值中减去互斥门的ApcDisable的值,结果为非0(负数)表示关闭APC请求,而ApcDisable的值则非1即0。举例言之,假定Thread->KernelApcDisable原来是0,而ApcDisable为1,则相减以后的结果为-1,表示关闭APC请求。最后,当前进程既已成为这个互斥门的主人,二者之间就有了连系,所以通过队列把它们结合起来,这是因为一个线程有可能同时存在于几个临界区中。
应该说这里别的都还好理解,成为问题的是为什么要允许嵌套进入互斥门。据“Programming the Microsoft Windows Driver Model”书中说,互斥门的特点之一就是允许嵌套进入,而优点之一则是可以防止死锁。书中并没有明确讲这二者之间是否存在因果关系,所以我们只能分析和猜测。首先,如过互斥门不允许嵌套进入(在前面的代码中取消允许当前业主进入的条件),而已经通过互斥门进入临界区的线程又对同一个互斥门进行P操作,那么肯定是会引起死锁的。这个线程会因为在P操作中不能通过互斥门而进入睡眠,能唤醒其睡眠的是已经在这个临界区中的线程(如果它执行V操作的话),可是这正是已经在睡眠等待的那个线程本身,所以就永远不会被唤醒。反之,有了前面KiIsObjectSignaled()中那样的安排,即允许互斥门当前的业主递归通过,那确实就可以避免由此而导致的死锁。
可是,为什么要企图递归通过同一个互斥门呢?既然已经通过这个具体的互斥门进入了临界区,为什么还要再一次试图进入同一个互斥门呢?应该说,在精心设计和实现的软件中是不应该有这种情况出现的。可是,考虑到应用软件的可重用(reuse),有时候也许会有这种情况。例如,一个线程在临界区内可能调用某个软件模块所提供的操作,而这个软件模块可能需要通过NtWaitForMultipleObjects()进入由多个互斥门保护的复合临界区,可是其中之一就是已经进入的那个互斥门。在这种情况下,对于已经进入的那个互斥门而言,就构成了递归进入。当然,我们可以通过修改那个软件模块来避免此种递归,但这可能又不是很现实。在这样的条件下,允许递归进入不失为一个简单的解决方案。
还要说明,允许递归通过互斥门固然可以防止此种特定形式的死锁,却并不是对所有的死锁都有效。真要防止死锁,还是得遵守有关的准则,精心设计,精心实现。
读者也许会问:这里所引的代码出自ReactOS,所反映的是ReactOS的作者们对Windows互斥门的理解,但是他们的理解是否正确呢?确实,Windows的代码是不公开的,所以也无从对比。可是,虽然Windows的代码不公开,它的一些数据结构的定义却是公开的,这里面就包括KMUTANT,所以前面特地说明了这是来自Windows DDK(其实ReactOS的许多数据结构都可以在DDK中找到)。既然我们知道互斥门允许递归进入,又看到KMUTANT中确有OwnerThread这个指针,那么我们就有理由相信ReactOS的这些代码离“真相”不会太远。当然,我们还可以、也应该、设计出一些实验来加以对比、验证。
再看从临界区退出并交还“通行证”的操作、即V操作,这就是系统调用NtReleaseMutant()。
[code]NTSTATUS STDCALL
NtReleaseMutant(IN HANDLE MutantHandle, IN PLONG PreviousCount OPTIONAL)
{
PKMUTANT Mutant;
KPROCESSOR_MODE PreviousMode = ExGetPreviousMode();
NTSTATUS Status = STATUS_SUCCESS;
. . . . . .
if(PreviousMode == UserMode && PreviousCount) {
_SEH_TRY . . . . . . _SEH_END;
if(!NT_SUCCESS(Status)) return Status;
}
/* Open the Object */
Status = ObReferenceObjectByHandle(MutantHandle, MUTANT_QUERY_STATE,
ExMutantObjectType, PreviousMode, (PVOID*)&Mutant, NULL);
/* Check for Success and release if such */
if(NT_SUCCESS(Status)) {
LONG Prev;
/* Save the Old State */
DPRINT("Releasing Mutant\n");
Prev = KeReleaseMutant(Mutant, MUTANT_INCREMENT, FALSE, FALSE);
ObDereferenceObject(Mutant);
/* Return it */
if(PreviousCount) {
_SEH_TRY . . . . . . _SEH_END;
}
}
/* Return Status */
return Status;
}[/code]
显然,这里实质性的操作是KeReleaseMutant(),我们顺着往下看。
[code][NtReleaseMutant() > KeReleaseMutant()]
LONG
STDCALL
KeReleaseMutant(IN PKMUTANT Mutant, IN KPRIORITY Increment,
IN BOOLEAN Abandon, IN BOOLEAN Wait)
{
KIRQL OldIrql;
LONG PreviousState;
PKTHREAD CurrentThread = KeGetCurrentThread();
/* Lock the Dispatcher Database */
OldIrql = KeAcquireDispatcherDatabaseLock();
/* Save the Previous State */
PreviousState = Mutant->Header.SignalState;
/* Check if it is to be abandonned */
if (Abandon == FALSE) {
/* Make sure that the Owner Thread is the current Thread */
if (Mutant->OwnerThread != CurrentThread) {
DPRINT1("Trying to touch a Mutant that the caller doesn't own!\n");
ExRaiseStatus(STATUS_MUTANT_NOT_OWNED);
}
/* If the thread owns it, then increase the signal state */
Mutant->Header.SignalState++;
} else {
/* It's going to be abandonned */
DPRINT("Abandonning the Mutant\n");
Mutant->Header.SignalState = 1;
Mutant->Abandoned = TRUE;
}
/* Check if the signal state is only single */
if (Mutant->Header.SignalState == 1) {
if (PreviousState <= 0) {
DPRINT("Removing Mutant\n");
RemoveEntryList(&Mutant->MutantListEntry);
}
/* Remove the Owning Thread and wake it */
Mutant->OwnerThread = NULL;
/* Check if the Wait List isn't empty */
DPRINT("Checking whether to wake the Mutant\n");
if (!IsListEmpty(&Mutant->Header.WaitListHead)) {
/* Wake the Mutant */
DPRINT("Waking the Mutant\n");
KiWaitTest(&Mutant->Header, Increment);
}
}
/* If the Wait is true, then return with a Wait and don't unlock the Dispatcher Database */
if (Wait == FALSE) {
/* Release the Lock */
KeReleaseDispatcherDatabaseLock(OldIrql);
} else {
/* Set a wait */
CurrentThread->WaitNext = TRUE;
CurrentThread->WaitIrql = OldIrql;
}
/* Return the previous state */
return PreviousState;
}[/code]
参数Abandon表示在退出临界区以后是否要废弃这个互斥门。我们从NtReleaseMutant()的代码中可以看出,实际传下来的参数值是FALSE。那么什么情况下这个参数会是TRUE呢?据“Native API”书中说,这发生于互斥门的业主、就是已经通过这个互斥门进入了临界区的线程突然要结束其生命的时候。
既然临界区中的线程要退出,这个互斥门就变成无主的了,所以把Mutant->OwnerThread设置成NULL。其余的代码就留给读者自己去理解了。
4. 事件(Event)
信号量机制的另一个变种是“事件”,这是通过事件对象实现的。Windows为事件对象的创建和打开提供了NtCreateEvent()和NtOpenEvent()两个系统调用。由于所有此类函数的相似性,这两个系统调用的代码就不用看了,只要知道内核中代表着事件对象的数据结构是KEVENT就可以了:
[code]typedef struct _KEVENT {
DISPATCHER_HEADER Header;
} KEVENT, *PKEVENT, *RESTRICTED_POINTER PRKEVENT;[/code]
这就是说,除DISPATCHER_HEADER以外,KEVENT就不需要有别的什么字段了。
Windows定义和提供了两种不同类型的事件,每个事件对象也因此而分成两种类型,这就是:
[code]typedef enum _EVENT_TYPE {
NotificationEvent,
SynchronizationEvent
} EVENT_TYPE;[/code]
事件对象的类型是在创建的时候(通过参数)设定的,记录在对象头部的Type字段中,设定以后就不能改变。为不同的应用和目的需要使用不同类型的事件对象。
类型为NotificationEvent的事件代表着“通知”。通知是广播式的,其作用就是通知公众某个事件业已发生(Header中的SignalState为1),一个观看者看了这个布告并不影响别的观看者继续观看。所以,在通知型事件对象上的P操作并不消耗资源,也就是不改变其数值。在这一点上它就像是一个全局(跨进程)的变量。但是,如果事件尚未发生(SignalState为0),则所有的观看者、即对此对象执行P操作的线程全都被阻塞而进入睡眠,直到该事件发生,在这一点上又不太像“通知”,而反倒是起着同步的作用了(设想你去看高考发榜,但是还没贴出来,你就被“套住”等在那儿了)。读者也许会想到,既然P操作不改变SignalState的值,那岂不是一旦SignalState变成1就永远是1、从而事件对象只能一次性使用了?这确实是个问题,所以Windows又专门提供了一个系统调用NtResetEvent(),用来“重启(Reset)”一个事件对象、即将其SignalState清0。
类型为SynchronizationEvent的事件对象则用于同步,这就相当于初值为0、最大值为1的信号量。对于同步型的事件对象,一次P操作相当于消耗一个筹码(通行证),而V操作则相当于提供一个筹码。
回顾一下前面KiIsObjectSignaled()的代码,这是P操作中用来判断是否可以(拿到筹码)进入临界区的函数。这个函数对于除互斥门以外的所有对象都返回(!Object->SignalState <= 0)。这就是说,不管是同步型还是通知型的事件对象,执行P操作的线程能拿到筹码或看到通知的条件都是SignalState为1,否则就要睡眠等待。
再回顾一下KiSatisfyObjectWait()的代码,这是P操作中拿到筹码以后的操作:
[code]KiSatisfyObjectWait(PDISPATCHER_HEADER Object, PKTHREAD Thread)
{
/* Special case for Mutants */
if (Object->Type == MutantObject) {
. . . . . .
} else if ((Object->Type & TIMER_OR_EVENT_TYPE) == EventSynchronizationObject) {
/* These guys (Syncronization Timers and Events) just get un-signaled */
Object->SignalState = 0;
} else if (Object->Type == SemaphoreObject) {
/* These ones can have multiple signalings, so we only decrease it */
Object->SignalState--;
}
}[/code]
这里Object->Type的最低3位记录着对象的类型,如果是EventSynchronizationObject就说明是同步型的事件对象,此时把Object->SignalState置0,表示把筹码消耗掉了。由于事件对象的SignalState只有两个值0或非0,因而在SignalState为1的条件下将其设置成0跟使之递减是等价的。可是,如果是通知型的事件对象,那就没有任何操作,所以并没有把通知“消耗”掉。所以,这又是变相的P操作。
跟信号量和互斥门一样,对事件对象的P操作就是系统调用NtWaitForSingleObject()或NtWaitForMultipleObjects(),或者(如果从内核中调用)也可以是KeWaitForSingleObject(),而KiIsObjectSignaled()和KiSatisfyObjectWait()都是在P操作内部调用的函数。
事件对象的V操作是系统调用NtSetEvent(),意思是把事件对象的SignalState设置成1。就像NtReleaseMutant()的主体是KeReleaseMutant()一样,NtSetEvent()的主体是KeSetEvent()。我们跳过NtSetEvent()这一层,直接看KeSetEvent()的代码。
[code][NtSetEvent() > KeSetEvent()]
LONG STDCALL
KeSetEvent(PKEVENT Event, KPRIORITY Increment, BOOLEAN Wait)
{
. . . . . .
/* Lock the Dispathcer Database */
OldIrql = KeAcquireDispatcherDatabaseLock();
/* Save the Previous State */
PreviousState = Event->Header.SignalState;
/* Check if we have stuff in the Wait Queue */
if (IsListEmpty(&Event->Header.WaitListHead)) {
/* Set the Event to Signaled */
DPRINT("Empty Wait Queue, Signal the Event\n");
Event->Header.SignalState = 1;
} else {
/* Get the Wait Block */
WaitBlock = CONTAINING_RECORD(Event->Header.WaitListHead.Flink,
KWAIT_BLOCK, WaitListEntry);
/* Check the type of event */
if (Event->Header.Type == NotificationEvent || WaitBlock->WaitType == WaitAll) {
if (PreviousState == 0) {
/* We must do a full wait satisfaction */
DPRINT("Notification Event or WaitAll, Wait on the Event and Signal\n");
Event->Header.SignalState = 1;
KiWaitTest(&Event->Header, Increment);
}
} else {
/* We can satisfy wait simply by waking the thread, since our signal state is 0 now */
DPRINT("WaitAny or Sync Event, just unwait the thread\n");
KiAbortWaitThread(WaitBlock->Thread, WaitBlock->WaitKey, Increment);
}
}
/* Check what wait state was requested */
if (Wait == FALSE) {
/* Wait not requested, release Dispatcher Database and return */
KeReleaseDispatcherDatabaseLock(OldIrql);
} else {
/* Return Locked and with a Wait */
KTHREAD *Thread = KeGetCurrentThread();
Thread->WaitNext = TRUE;
Thread->WaitIrql = OldIrql;
}
/* Return the previous State */
return PreviousState;
}[/code]
参数Increment和Wait所起的作用与前面KeReleaseSemaphore()中的相同。所谓“设置事件”其实就是一种特殊的、变通的V操作。具体的操作分两种情况:
1. 如果IsListEmpty()为真,即等待队列是空的、没有线程在睡眠等待,就把Event->Header.SignalState设置成1。这样,如果此后有线程对此事件对象执行P操作、即NtWaitForSingleObject(),就因此而不必睡眠等待。这对于通知型和同步型的事件对象都是一样。
2. 已经有线程在这个对象上睡眠等待,那就要从中唤醒一个或所有线程。这时候的处理取决于事件对象的类型以及等待的方式:
l 对于通知型的事件对象,或者等待者的等待方式是WaitAll,而且此前SignalState为0,就将SignalState置1,并通过KiWaitTest()唤醒这个线程,以及等待队列中所有符合条件的线程。可是,要是SignalState本来就已经是1,则没有任何影响。
l 否则,对于同步型的事件对象,并且等待者的等待方式是WaitAny,就通过KiAbortWaitThread()唤醒等待队列中的第一个线程。此时并不改变SignalState的值。因为既然唤醒了一个线程,就已经把这筹码消耗掉了。
这里KiWaitTest()和KiAbortWaitThread()的区别在于:KiWaitTest()是在一个while循环中对等待队列中的所有进程执行KiAbortWaitThread(),条件是SignalState大于0。对于信号量,由于每唤醒一个线程就使SignalState减1,这循环很快就停止了,一般是只唤醒一个线程。但是如前所述,通知型事件对象在唤醒一个线程的时候不改变SignalState的值。于是,这个while循环就会唤醒等待队列中的所有进程。不过这里也有例外,如果其中的某个线程是在多个“可等待对象”上等待,而且等待方式是WaitAll,那就还要看是否别的条件也满足了,不然就只好把它跳过,这也是KiWaitTest()的代码中按排好了的。
前面讲过,一旦将通知型事件对象的SignalState设置成1,它就一直保持为1,P操作不会改变它的值。即使再对其执行一次KeSetEvent(),也不会改变它的值,因为本来就已经是1了。为了使其变成0,以便再次使用这个事件对象,就需要对其执行另一个系统调用NtResetEvent()。同样,NtResetEvent()的主体是KeResetEvent()。
[code][NtSetEvent() > KeResetEvent()]
LONG STDCALL
KeResetEvent(PKEVENT Event)
{
KIRQL OldIrql;
LONG PreviousState;
DPRINT("KeResetEvent(Event %x)\n",Event);
/* Lock the Dispatcher Database */
OldIrql = KeAcquireDispatcherDatabaseLock();
/* Save the Previous State */
PreviousState = Event->Header.SignalState;
/* Set it to zero */
Event->Header.SignalState = 0;
/* Release Dispatcher Database and return previous state */
KeReleaseDispatcherDatabaseLock(OldIrql);
return PreviousState;
}[/code]
解释就没有必要了。注意调用NtResetEvent()的不必就是NtSetEvent()的调用者,而可以是别的线程或内核模块。不过有些内核模块只能调用KeResetEvent(),而不是NtResetEvent()。
Windows还有个系统调用NtPulseEvent(),这是把NtSetEvent()和NtResetEvent()组合在了一起,相当于先NtSetEvent()、然后马上就NtResetEvent()。这样,其效果就是唤醒已经在通知型事件对象上等待的所有线程,但是下不为例。而对于同步型事件对象则大致等同于NtSetEvent()。
可见,虽然“事件”实质上是“信号量”的一种特例和变种,但是在使用上却有着明显的差别。信号量的“正宗”的用途是构筑临界区。在这种应用中,一个线程得以通过P操作进入临界区的原因可能是有另一个线程执行了V操作,但是既然进了临界区就总有从临界区退出而执行V操作的时候。这样,一个线程在P操作以后总是有个V操作。从总体上看,每个线程的P操作和V操作是平衡的、即数量相等的。但是“事件”则不同,“事件”并不是用来构筑临界区、而纯粹是用于线程间同步的。在这里,等待事件发生的一方总是执行P操作,而发出事件通知的一方则总是执行V操作。在前面对于“信号量”的比喻中把P操作比作领取通行证,把V操作比作交还通行证。相比之下,对于“事件”则相当于领取的通行证从来不交还,而另有供应者在不时地提供新的通行证。而且,特别有意义的是,发出事件通知的一方还不必非得是一个线程,也可以是内核中的某些子系统,例如设备驱动,所以也可以用于线程与内核之间的同步,特别是广泛地应用于设备驱动。当然,发出事件通知的一方更不必局限于某一个特定的线程,而是任何一个线程都可以。
为了帮助读者加深对事件机制的理解,下面是一个内核线程DebugLogThreadMain的代码:
[code]VOID STDCALL
DebugLogThreadMain(PVOID Context)
{
KIRQL oldIrql;
IO_STATUS_BLOCK Iosb;
static CHAR Buffer[256];
ULONG WLen;
for (;;)
{
LARGE_INTEGER TimeOut;
TimeOut.QuadPart = -5000000; /* Half a second. */
KeWaitForSingleObject(&DebugLogEvent, 0, KernelMode, FALSE, &TimeOut);
KeAcquireSpinLock(&DebugLogLock, &oldIrql);
while (DebugLogCount > 0)
{
if (DebugLogStart > DebugLogEnd)
{
WLen = min(256, DEBUGLOG_SIZE - DebugLogStart);
memcpy(Buffer, &DebugLog[DebugLogStart], WLen);
Buffer[WLen + 1] = '\n';
DebugLogStart = (DebugLogStart + WLen) % DEBUGLOG_SIZE;
DebugLogCount = DebugLogCount - WLen;
KeReleaseSpinLock(&DebugLogLock, oldIrql);
NtWriteFile(DebugLogFile, NULL, NULL, NULL, &Iosb, Buffer, WLen + 1,
NULL, NULL);
}
else
{
WLen = min(255, DebugLogEnd - DebugLogStart);
memcpy(Buffer, &DebugLog[DebugLogStart], WLen);
DebugLogStart =
(DebugLogStart + WLen) % DEBUGLOG_SIZE;
DebugLogCount = DebugLogCount - WLen;
KeReleaseSpinLock(&DebugLogLock, oldIrql);
NtWriteFile(DebugLogFile, NULL, NULL, NULL, &Iosb, Buffer, WLen,
NULL, NULL);
}
KeAcquireSpinLock(&DebugLogLock, &oldIrql);
}
KeResetEvent(&DebugLogEvent);
KeReleaseSpinLock(&DebugLogLock, oldIrql);
}
}[/code]
这个内核线程是为内核调试日志(Log)服务的。内核中有个环形缓冲区DebugLog[],以及用作该数组下标的变量DebugLogStart和DebugLogEnd,还有表示环形缓冲区中数据长度的变量DebugLogCount。不管是哪一个线程,只要是进入了内核,如果需要在日志中写上一笔,就可以把字符串拷贝到这个环形缓冲区中,然后要求这个内核线程把内容写到一个日志文件中。为此当然需要同步,这是通过一个(同步型)事件对象DebugLogEvent达成的。由于是在内核中,所以这里对事件对象的操作都直接调用其内核版本,例如KeResetEvent()、而不是NtResetEvent()。此外,对于环形缓冲区的使用当然还需要互锁,这是通过“空转锁”DebugLogLock实现的,不过那不是我们此刻所关心的。
每当需要生成一项日志时,可以调用DebugLogWrite():
[code]VOID
DebugLogWrite(PCH String)
{
KIRQL oldIrql;
. . . . . .
KeAcquireSpinLock(&DebugLogLock, &oldIrql);
if (DebugLogCount == DEBUGLOG_SIZE)
{
DebugLogOverflow++;
KeReleaseSpinLock(&DebugLogLock, oldIrql);
if (oldIrql < DISPATCH_LEVEL)
{
KeSetEvent(&DebugLogEvent, IO_NO_INCREMENT, FALSE);
}
return;
}
while ((*String) != 0)
{
DebugLog[DebugLogEnd] = *String;
String++;
DebugLogCount++;
if (DebugLogCount == DEBUGLOG_SIZE)
{
DebugLogOverflow++;
KeReleaseSpinLock(&DebugLogLock, oldIrql);
if (oldIrql < DISPATCH_LEVEL)
{
KeSetEvent(&DebugLogEvent, IO_NO_INCREMENT, FALSE);
}
return;
}
DebugLogEnd = (DebugLogEnd + 1) % DEBUGLOG_SIZE;
}
KeReleaseSpinLock(&DebugLogLock, oldIrql);
if (oldIrql < DISPATCH_LEVEL)
{
KeSetEvent(&DebugLogEvent, IO_NO_INCREMENT, FALSE);
}
}[/code]
对于这段代码,以及对于DebugLogWrite()和DebugLogThreadMain()之间怎样互动,这里就不作解释了。只是要指出:DebugLogWrite()的每次执行可能都在不同线程的上下文里、代表着不同的线程,因为任何线程都可以调用DebugLogWrite()。另外,想必读者已经注意到,KeResetEvent()是由DebugLogThreadMain()自己调用、而不是由别的线程调用的。
介绍完事件对象,还应该提一下,Windows还有一种特殊的“事件对(EventPair)”对象。与此有关的系统调用有这么一些:
[code] NtCreateEventPair()
NtOpenEventPair()
NtWaitHighEventPair()
NtWaitLowEventPair()
NtSetHighWaitLowEventPair()
NtSetLowWaitHighEventPair()
NtSetHighEventPair()
NtSetLowEventPair()[/code]
顾名思义,“事件对”就是把两个事件对象紧密地组合在一起。事实上也正是如此,一个事件对由“高”、“低”两个事件对象组合构成,其设计意图是用于“点对点”的双向进程间通信。实际上这是为提高Windows进程与服务进程Csrss之间的通信效率而设置的(Csrss是Windows子系统的管理/服务进程)。早期的csrss承担着许多操作,Windows进程与Csrss之间的通信非常频繁,所以其效率至关重要。这种进程间通信的典型情景就是一方唤醒另一方、自身却又进入睡眠,反过来等待被对方唤醒,就像打乒乓球一样,为此就专门设计了NtSetHighWaitLowEventPair()和NtSetLowWaitHighEventPair()两个系统调用。不仅如此,为了尽可能地提高效率(在这种情况下的优化甚至是以CPU的时钟周期数计算的),还专门单独分配了两个中断向量0x2B和0x2C,而不跟别的系统调用合用0x2E。不过,后来Csrss的许多操作被移到了内核中,不再需要那么频繁的进程间通信了,因而在效率上的容忍度也宽松了一些,所以现在又回到了0x2E,而不再使用0x2B和0x2C这两个中断向量。
5. 命名管道(Named Pipe)和信箱(Mail Slot)
前面提到,如果从字面上理解,那么进程间通信也可以通过磁盘文件而实现。但是,把信息写入某个磁盘文件,再由另一个进程从磁盘文件读出,在速度上是很慢的。固然,由于文件缓冲区(Cache)的存在,对磁盘文件的写和读未必都经过磁盘,但是那并没有保证。再说,普通的文件操作也没有提供进程间同步的手段。所以通过普通的磁盘文件实现进程间通信是不太现实的。但是这也提示我们,如果能实现一种特殊文件,使得对文件的读写只在缓冲区中进行(而不写入磁盘),并且实现进程间的同步,那倒是个不坏的主意。命名管道就是这样一种特殊文件。实际上,命名管道还不仅是这样的特殊文件,它还是一种网络通信的机制,只是当通信的双方存在于同一台机器上时,才落入本文所说的进程间通信的范畴。
既然命名管道是一种特殊文件,它的创建、打开、读写等等操作就基本上都可以利用文件系统中的有关资源加以实现。当然,这毕竟是一种特殊文件,对于使用者来说,最大的特殊之处在于这是一个“先进先出”的字节流,不能对其执行lseek()一类的操作。
先看命名管道的创建,Windows的Win32 API上提供了一对库函数CreateNamedPipeA()和CreateNamedPipeW(),前者用于ASCII码字符串,后者用于“宽字符”即Unicode的字符串,实际上前者只是把8位字符转换成Unicode以后再调用后者。对CreateNamedPipeW()的调用大致如下:
[code] Handle = CreateNamedPipeW(L"[A]\\\\.\\pipe\\MyControlPipe[/url]",
PIPE_ACCESS_DUPLEX,
PIPE_TYPE_MESSAGE | PIPE_READMODE_MESSAGE | PIPE_WAIT,
. . . . . .);[/code]
这里的管道名实际上是“\\.\pipe\MyControlPipe”,前面的“\\.”表示本机,而“\pipe\MyControlPipe”则是路径名。如果把“.”换成主机名,那就可以是在另一台机器上的对象。参数PIPE_ACCESS_DUPLEX表示要建立的是“双工”、即可以双向通信的管道。另一个参数是一些标志位,表示要建立的管道采用“报文(message)”的方式、而不是字节流的方式读写,并且是阻塞方式、即有等待的读写。
CreateNamedPipeW()内部通过系统调用NtCreateNamedPipeFile()完成命名管道的创建,这是Windows内核为命名管道提供的唯一的系统调用:
[code]NTSTATUS STDCALL
NtCreateNamedPipeFile(PHANDLE FileHandle, ACCESS_MASK DesiredAccess,
POBJECT_ATTRIBUTES ObjectAttributes, PIO_STATUS_BLOCK IoStatusBlock,
ULONG ShareAccess, ULONG CreateDisposition, ULONG CreateOptions,
ULONG NamedPipeType, ULONG ReadMode, ULONG CompletionMode,
ULONG MaximumInstances, ULONG InboundQuota, ULONG OutboundQuota,
PLARGE_INTEGER DefaultTimeout)
{
NAMED_PIPE_CREATE_PARAMETERS Buffer;
. . . . . .
if (DefaultTimeout != NULL)
{
Buffer.DefaultTimeout.QuadPart = DefaultTimeout->QuadPart;
Buffer.TimeoutSpecified = TRUE;
}
else
{
Buffer.TimeoutSpecified = FALSE;
}
Buffer.NamedPipeType = NamedPipeType;
Buffer.ReadMode = ReadMode;
Buffer.CompletionMode = CompletionMode;
Buffer.MaximumInstances = MaximumInstances;
Buffer.InboundQuota = InboundQuota;
Buffer.OutboundQuota = OutboundQuota;
return IoCreateFile(FileHandle, DesiredAccess, ObjectAttributes, IoStatusBlock,
NULL, FILE_ATTRIBUTE_NORMAL, ShareAccess, CreateDisposition,
CreateOptions, NULL, 0, CreateFileTypeNamedPipe, (PVOID)&Buffer,
0);
}[/code]
在Windows中,文件系统是I/O子系统的一部分,文件的创建是由IoCreateFile()完成的,参数CreateFileTypeNamedPipe是个文件类型代码,它决定了所创建的是作为特殊文件的命名管道。至于IoCreateFile()如何创建此种特殊文件,那已经不在本文要讨论的范围内。
一般,命名管道是由“服务端”线程创建的,创建以后还要对其调用一个Win32 API库函数ConnectNamedPipe(),以等待“客户端”线程打开这个命名管道、从而使双方建立起点对点的连接(注意这里的Connect与Socket机制中的Connect意思完全不同)。
[code]BOOL STDCALL
ConnectNamedPipe(HANDLE hNamedPipe,
LPOVERLAPPED lpOverlapped)
{
PIO_STATUS_BLOCK IoStatusBlock;
IO_STATUS_BLOCK Iosb;
HANDLE hEvent;
NTSTATUS Status;
if (lpOverlapped != NULL)
{
lpOverlapped->Internal = STATUS_PENDING;
hEvent = lpOverlapped->hEvent;
IoStatusBlock = (PIO_STATUS_BLOCK)lpOverlapped;
}
else
{
IoStatusBlock = &Iosb;
hEvent = NULL;
}
Status = NtFsControlFile(hNamedPipe, hEvent, NULL, NULL, IoStatusBlock,
FSCTL_PIPE_LISTEN, NULL, 0, NULL, 0);
if ((lpOverlapped != NULL) && (Status == STATUS_PENDING))
return TRUE;
if ((lpOverlapped == NULL) && (Status == STATUS_PENDING))
{
Status = NtWaitForSingleObject(hNamedPipe, FALSE, NULL);
if (!NT_SUCCESS(Status))
{
SetLastErrorByStatus(Status);
return FALSE;
}
Status = Iosb.Status;
}
if ((!NT_SUCCESS(Status) && Status != STATUS_PIPE_CONNECTED) ||
(Status == STATUS_PENDING))
{
SetLastErrorByStatus(Status);
return FALSE;
}
return TRUE;
}[/code]
实际的操作是由NtFsControlFile()完成的,而NtFsControlFile()有点像Linux中的fcntl(),常常用来实现除标准的“读”、“写”等等以外的许多不同操作。
“客户端”线程通过打开文件建立与“服务端”线程的连接,所打开的就是作为特殊文件的命名管道。Windows没有特别为此提供系统调用,而是直接利用NtOpenFile(),例如:
[code] Status = NtOpenFile(&FileHandle, FILE_GENERIC_READ, &ObjectAttributes, &Iosb,
FILE_SHARE_READ | FILE_SHARE_WRITE,
FILE_SYNCHRONOUS_IO_NONALERT);[/code]
这里使用的参数FILE_SYNCHRONOUS_IO_NONALERT表示对文件的访问将是同步的、也即阻塞的。要打开的文件名在数据结构ObjectAttributes中,所以这里看不见。当然,这文件名必须与“服务端”所使用的相同。由此可见,“客户端”线程不必知道这是一个命名管道,甚至不必知道这是特殊文件,而只把它当成一般的文件看待。
在最简单的情况下,这就已经够了,下面就可以通过已经建立的连接进行通信了。具体的操作在形式上就跟普通文件的读/写一样。在读普通文件时,当事线程也会被阻塞(如果要读的内容不是已经在缓冲区中),此时它所等待的主要是磁盘完成其物理的读出过程,而磁盘完成其读出过程以后的中断则会解除它的阻塞,相当于执行了一次V操作。相比之下,对于命名管道,启动读操作的线程也会被阻塞(如果尚无已经到达的数据或报文),而此时等待的是管道的对方线程往管道中写数据。对方往管道中写数据,就解除了等待方线程的阻塞,实质上构成一次V操作。所以,普通文件的读/写同样也包含了同步机制,只不过那一般是进程与外部设备(或外部物理过程)之间的同步,而命名管道所需的是进程与进程之间的同步,但是这并没有本质上的不同。事实上,读者以后会看倒,在设备驱动程序中常常要用到NtWaitForSingleObject()之类的等待机制,而且这正是设备驱动得以实现的基础。
一般而言,如果在管道中尚无数据的时候启动读操作,当事线程就会被阻塞。但是,为避免被阻塞,也可以先通过PeekNamedPipe()查询一下是否已经有报文到达。
[code]BOOL STDCALL
PeekNamedPipe(HANDLE hNamedPipe, LPVOID lpBuffer,
DWORD nBufferSize, LPDWORD lpBytesRead,
LPDWORD lpTotalBytesAvail, LPDWORD lpBytesLeftThisMessage)
{
PFILE_PIPE_PEEK_BUFFER Buffer;
IO_STATUS_BLOCK Iosb;
ULONG BufferSize;
NTSTATUS Status;
BufferSize = nBufferSize + sizeof(FILE_PIPE_PEEK_BUFFER);
Buffer = RtlAllocateHeap(RtlGetProcessHeap(),0, BufferSize);
Status = NtFsControlFile(hNamedPipe, NULL, NULL, NULL, &Iosb,
FSCTL_PIPE_PEEK, NULL, 0, Buffer, BufferSize);
if (Status == STATUS_PENDING)
{
Status = NtWaitForSingleObject(hNamedPipe, FALSE, NULL);
if (NT_SUCCESS(Status)) Status = Iosb.Status;
}
if (Status == STATUS_BUFFER_OVERFLOW)
{
Status = STATUS_SUCCESS;
}
. . . . . .
if (lpTotalBytesAvail != NULL)
{
*lpTotalBytesAvail = Buffer->ReadDataAvailable;
}
if (lpBytesRead != NULL)
{
*lpBytesRead = Iosb.Information - sizeof(FILE_PIPE_PEEK_BUFFER);
}
if (lpBytesLeftThisMessage != NULL)
{
*lpBytesLeftThisMessage = Buffer->MessageLength -
(Iosb.Information - sizeof(FILE_PIPE_PEEK_BUFFER));
}
if (lpBuffer != NULL)
{
memcpy(lpBuffer, Buffer->Data,
min(nBufferSize, Iosb.Information - sizeof(FILE_PIPE_PEEK_BUFFER)));
}
RtlFreeHeap(RtlGetProcessHeap(),0, Buffer);
return(TRUE);
}[/code]
同样,实际的查询是由NtFsControlFile()完成的,只是用了另一个“命令码”。
除命名管道外,还有“信槽(MailSlot)”也是类似的特殊文件,只是信槽所提供的是无连接的通信机制。一般把这样无连接的通信称为“数据报”机制,而命名管道所提供的有连接通信则称为“虚电路”机制。“数据报”机制所提供的通信是“尽力传递”而不是“保证传递”,所以是不可靠的。此外,信槽所提供的通信不一定是点对点、也可以是广播式的。和命名管道一样,Windows为信槽也只提供了一个系统调用,即NtCreateMailslotFile()。而且它的内部也只是调用IoCreateFile(),不同的只是作为参数的文件类型为CreateFileTypeMailslot。既然这么相似,这里就不多说了。
6. 本地过程调用(LPC)
“本地过程调用”是建立在“端口(Port)”基础上的一种Client/Server结构的跨进程过程调用机制。而Port则是类似于Unix域Socket那样的进程间通信机制。离开了进程间通信,Client/Server结构就无从谈起。所以Port机制是基础,而LPC是建立在此种基础上的应用。
实际上,前面所讲的各种机制都是单项的手段,严格说来都不构成高效的进程间通信。例如共享内存区提供了传递数据的手段,却不具备进程间同步的功能;而信号量、互斥门、事件三者都是进程间同步的手段,却又缺少了传递数据的功能。所以,真要有高效的进程间通信,就得把这两方面结合起来。而“端口(Port)”恰恰就是把数据传递和进程间同步结合起来、集成在一起而形成的高效率进程间通信机制。
按说Port才是高效的进程间通信机制,可是Microsoft却又偏偏不把它归入进程间通信,也不作为进程间通信的手段在Win32 API上向应用软件提供,而是使它的应用局限于跨进程的过程调用。当然,本地过程调用本身确实不是进程间通信,而是进程间通信的一种应用。不过Windows内核自身倒是在利用Port作为进程间通信的手段。例如每个进程实际上都有一个Debug端口和一个Exception端口,在程序执行的某些点上、或者在发生异常时,往往会通过这两个端口给有关的进程发送信息。
由于LPC机制的复杂性,笔者将另撰专文予以介绍,这里就不多说了。
7. 报文(Message)
报文(Message)是一种用于“视窗(Window)”的线程间通信机制。在早期的Windows系统中,Message是实现于用户空间的“应用层”进程间通信机制。后来用户空间的许多基础设施都移到了内核中,成为模块Win32k.sys,并为此而对Windows的系统调用界面进行了扩充。这一扩充可真有点喧宾夺主,增加了六百多个“扩展系统调用”,而原来“正宗”的只不过是二百多个。这六百多个新增的系统调用大部分都是用于图形操作,但是也有用于Message机制的系统调用,包括NtUserGetMessage()、NtUserWaitMessage()、NtUserSendMessage()、NtUserPostMessage()等等。相应地,在Win32 API界面上则提供了GetMessage()、WaitMessage()、SendMessage()、PostMessage()等等库函数。这些库函数都在user32.dll中。
以前说过,每个线程在内核中都有个ETHREAD数据结构,此外还有个因Win32k而来的W32THREAD数据结构,其定义为:
[code]typedef struct _W32THREAD
{
PVOID MessageQueue;
FAST_MUTEX WindowListLock;
LIST_ENTRY WindowListHead;
LIST_ENTRY W32CallbackListHead;
struct _KBDTABLES* KeyboardLayout;
struct _DESKTOP_OBJECT* Desktop;
HANDLE hDesktop;
DWORD MessagePumpHookValue;
BOOLEAN IsExiting;
} W32THREAD, *PW32THREAD;[/code]
这个数据结构的第一个成分就是MessageQueue,就是用于Message传递的。
其实,要说Windows的各种进程间/线程间通信机制的“知名度”,恐怕莫过于这Message机制了。这是因为Windows应用程序的核心就是一个接收Message、处理Message的循环。典型Windows应用程序的基本结构如下:
[code]int WINAPI
WinMain(HINSTANCE hInst, HINSTANCE hPrevInstance,
LPSTR lpszCmdLine, int nCmdShow)
{
. . . . . .
RegisterClassEx(&wndclass);
/* Create main window */
hwndMain = CreateWindow(szFrameClass, szAppTitle, dwStyle, xPos, yPos,
xWidth, yHeight, 0, 0, hInstance, NULL);
ShowWindow(hwndMain, nCmdShow);
UpdateWindow(hwndMain);
while (GetMessage(&msg, NULL, 0, 0) != FALSE)
{
TranslateMessage(&msg);
DispatchMessage(&msg);
}
return(msg.wParam);
}[/code]
这里的GetMessage()就是用于Message接收的库函数,其内部就是通过扩展系统调用NtUserGetMessage()实现的。而Windows应用程序的核心就是这个while循环。















 2655
2655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









