







论文:《The Factual Inconsistency Problem in Abstractive Text Summarization: A Survey》
Yichong Huang , Xiachong Feng , Xiaocheng Feng and Bing Qin
Research Center for Social Computing and Information Retrieval
Harbin Institute of Technology, China
{ychuang, xiachongfeng, xcfeng, qinb}@ir.hit.edu.cn,中国哈尔滨理工大学社会计算与信息检索研究中心黄一冲、冯夏冲、冯晓成和秦冰
arXiv:2104.14839v2 [cs.CL] 10 May 2021
<2104.14839.pdf>
目录
摘要
最近,已经提出了由Seq2Seq框架开创的各种神经编码器-解码器模型,以通过学习将输入文本映射到输出文本来实现生成更抽象摘要的目标。在高水平上,这种神经模型可以自由地生成摘要,而不受所用单词或短语的限制。此外,它们的格式更接近人类编辑的摘要,输出更可读和流畅。然而,神经模型的抽象能力是一把双刃剑。生成摘要的一个常见问题是文章中的事实信息失真或捏造。原文与摘要之间的这种不一致性引起了人们对其适用性的各种担忧,而以往的文本摘要评估方法并不适用于这一问题。针对上述问题,当前的研究方向主要分为两类,一类是设计有事实意识的评估指标,以选择没有事实不一致错误的输出,另一类是开发新的事实一致性总结系统。在本次调查中,我们重点对这些特定于事实的评估方法和文本摘要模型进行了全面回顾。
1.Introduction
文本摘要是自然语言处理(NLP)领域中最重要但最具挑战性的任务之一。它旨在将一段文本浓缩为包含原始文件主要信息的较短版本[Mani和Maybury,1999;Nallapati等人,2016]。
文本摘要方法可分为两类:提取式和抽象式。
提取摘要是通过考虑统计特征,从文本中找出最突出的句子,然后对提取的句子进行排列以创建摘要。另一方面,抽象摘要是一种通过改写或使用新词生成新句来生成摘要的技术,而不是简单地提取重要句子[Gupta,2019]。
随着深度学习的巨大进步,基于神经的抽象摘要模型能够生成流畅且可读的摘要[参见等人,2017]。
然而,现有的神经抽象摘要模型很容易产生事实不一致性错误。
它是指摘要有时歪曲或捏造文章中的事实的现象。最近的研究表明,高达30%的抽象模型生成的摘要包含此类事实不一致[Kryscinski等人,2020;Falke等人,2019]。这给抽象摘要系统的可信性和可用性带来了严重的问题。图1展示了一篇示例文章和生成的摘要摘要。如图所示,“4.8级地震”被夸大为“强烈地震”,将造成不利的社会影响。

图1:事实不一致错误示例。源文档支持的事实用绿色标记。事实不一致错误用红色标记。
另一方面,大多数现有的摘要评估工具将生成的摘要和人类书面参考摘要之间的N-gram重叠计算为生成的摘要的质量,而忽略了两个文本之间的事实级一致性。Zhu等人[2020]指出,生成的摘要通常在令牌级度量中较高,如ROUGE[Lin,2004],但缺乏事实正确性。例如,句子 “I am having vacation in Hawaii.”和 “I am not having vacation in Hawaii.” 共享几乎所有的unigram和bigram,尽管它们具有相反的含义。
父词条:n-gram.
unigram: 单个word
bigram: 双word
trigram:3 word
比如:
unigram 形式为:西/安/交/通/大/学
bigram形式为: 西安/安交/交通/通大/大学
trigram形式为:西安交/安交通/交通大/通大学
为了解决事实一致性问题,提出了许多自动的事实一致性评估指标和这些指标的元评估(§3)。此外,许多工作致力于优化摘要系统的事实一致性(§4)。在过去的三年中,已经提出了二十多项关于摘要事实一致性的研究。考虑到致力于解决事实不一致问题的大量努力以及NLP社区对抽象摘要的极大兴趣,在这项工作中,我们首先向读者介绍抽象摘要领域。然后,我们通过对事实一致性评估和事实一致性优化方法的广泛概述来关注事实一致性问题。在整个调查过程中,我们概述了从介绍的方法中吸取的经验教训,并对未来可能的方向提出了看法。
2.背景
在本节中,我们首先向读者介绍抽象摘要方法,以更好地理解产生事实不一致错误的原因。然后我们给出了事实不一致错误的定义和相应的类别。
2.1抽象摘要方法
传统的抽象摘要方法通常从源文档中提取一些关键词,然后重新排序并对这些关键词进行语言驱动的转换[Zajic等人,2004]。然而,以前基于转述的生成方法很容易生成有影响的句子[Hahn和Mani,2000]。
Nallapati等人[2016]首次提出使用RNN(即。编码器)以将源文档编码为单词向量序列,并使用另一RNN(即解码器)以基于来自编码器的单词向量生成单词序列作为生成的摘要。CNN[Narayan等人,2018]和Transformer[V aswani等人,2017]也可以实现编码器和解码器。基于序列到序列的神经文本生成的解码器是一种条件语言模型,它使得生成可读和流畅的文本成为可能[Fan等人,2018]。然而,大多数摘要系统都被训练为在单词水平上最大化参考摘要的对数似然性,这并不一定会奖励模型忠实[Maynez等人,2020]。
2.2事实不一致错误
事实不一致错误,即与源文件不一致的事实,可分为两类:
内在错误:与源文件相矛盾的事实,在Maynez等人[2020]中也称为“内在幻觉”。在图1中,与源文件中的“北方”相矛盾的“中央”一词属于这种情况。
外在错误:与源文档无关的事实(即源文档既不支持也不矛盾的内容),也称为“外在幻觉”。如图1所示,源文件中未报告的“至少7人死亡,100多人受伤”属于本案。
值得一提的是,现有的事实一致性优化方法主要关注内在误差,而这两类在事实一致性评估指标中没有区分。
3.事实一致性指标
我们盘点了事实一致性度量,然后将其分为两类:无监督和弱监督,如图2所示。无监督度量使用现有工具来评估摘要的事实一致性。
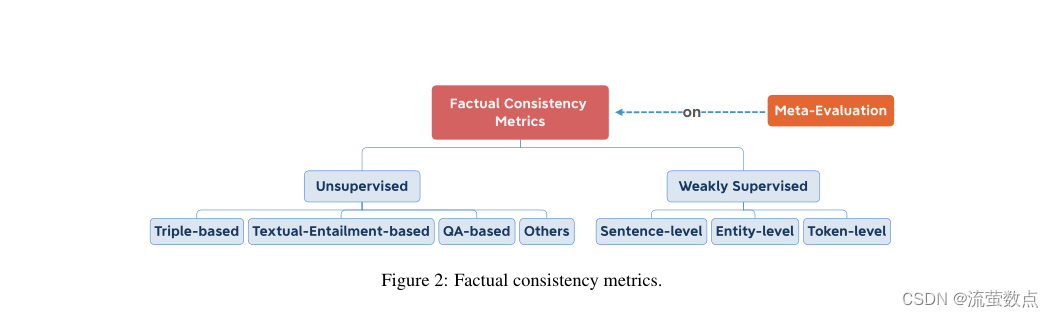
图2:事实一致性度量。
根据Unsupervised metrics无监督度量所基于的工具,我们进一步将无监督度量分为四种类型:基于三重、基于文本蕴涵、基于QA和其他。Weakly supervised metrics弱监督度量需要对事实一致性数据进行训练,该数据由文档和模型生成的摘要以及每个摘要的事实一致性得分组成。为了相互比较事实一致性指标,对事实一致性的Meta-evaluations元评估上升。我们介绍了两个关于事实一致性的元评估工作。此外,我们将现有指标组织到表1中。
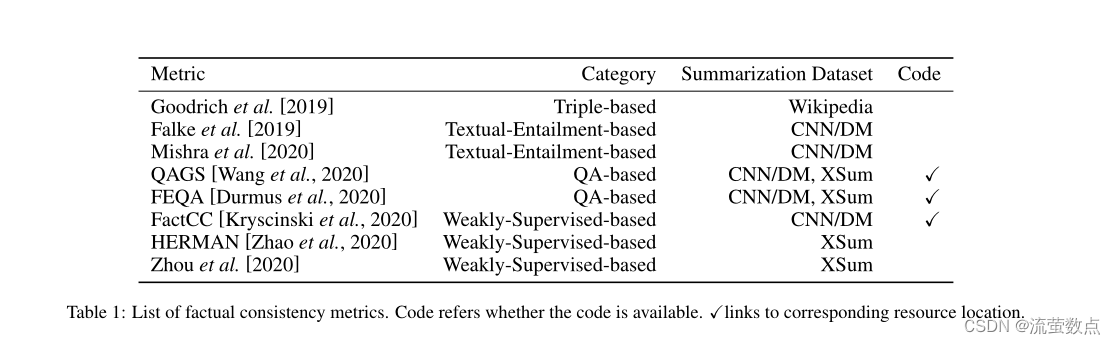
表1:事实一致性指标列表。代码指代码是否可用。√links到相应的资源位置。
3.1无监督指标
Triple-based
评估事实一致性的最直观方法是计算生成的摘要和源文档之间的事实重叠,如图3所示。事实通常由关系三元组(主题、关系、对象)表示,其中主题与对象有关系。为了提取三元组,Goodrich等人[2019]首先尝试使用OpenIE工具[Banko等人,2007]。然而,OpenIE提取具有未指定模式而非固定模式的三元组。在非特定模式提取中,从文本中提取主语和宾语之间的关系。在固定模式提取中,根据预定义的关系集预测关系,可以将其视为分类任务。非特定模式提取使得提取的三元组难以相互比较。如示例1所示,从表达相同事实的两个句子中,我们将得到彼此不匹配的不同三元组。

图3:基于三重的事实一致性度量。
Example 1 (Relation Extraction with Unspecific Schema).
source document: “Obama was born in Hawaii” ⇒
(Obama, born in, Hawaii)
summary: “Hawaii is the birthplace of Obama” ⇒ (Hawaii,
is the birthplace of, Obama).示例1(非特定模式的关系提取)。
来源文件:“奥巴马出生于夏威夷”⇒ (奥巴马,生于夏威夷)摘要:“夏威夷是奥巴马的出生地”⇒ (夏威夷是奥巴马的出生地)。
为了解决这个问题,Goodrich等人【2019】改为使用具有固定模式的关系提取工具。仍然考虑到示例1中的两句话,无论是从源文档还是摘要中提取,在固定模式提取中提取的三元组是(Hawaii, is the birthplace of, Obama)(夏威夷,是奥巴马的出生地)。这有助于提取的三元组更容易比较。
Textual-Entailment-based
遵循源文档在语义上包含事实一致性摘要的想法,Falke等人[2019]建议使用文本蕴涵预测工具来评估摘要的事实一致性。文本蕴涵预测,也称为自然语言推理(NLI),旨在检测一个文本P(前提)是否会包含另一个文本H(假设)。然而,开箱即用的蕴涵模型还没有为文本摘要中的事实一致性评估提供所需的性能。一个原因是领域从NLI数据集转移到摘要数据集。另一个原因是,NLI模型倾向于依靠启发式,如词汇重叠来解释高隐含概率。因此,现有的NLI模型在下游任务中的通用性较差。
为了使NLI模型更具普遍性,Mishra等人[2020]首先推测,NLI数据集和下游任务之间的关键区别在于前提的长度。具体而言,大多数现有的NLI数据集都以一句或最多几句话为前提。然而,大多数下游NLP任务(如文本摘要和问答)都以较长的文本为前提,这需要对较长的文本进行推理。对较长的文本进行推理需要大量额外的能力,如共指消解和诱因推理。为了弥合这一差距,他们接下来将从现有的QA数据集中创建新的长前提NLI数据集,以训练真正可推广的NLI模型。在对这个新的NLI数据集进行训练之后,该模型在事实一致性评估任务中获得了显著的改进。
QA-based
受文本摘要中其他基于问答(QA)的自动度量的启发,Wang等人;Durmus等人【2020;2020】分别提出了基于QA的事实一致性评估指标QAGS和FEQA。这两个指标都是基于这样一种直觉:如果我们对摘要及其源文档提出问题,如果摘要与源文档事实上一致,我们会得到类似的答案。如图4所示,它们都由三个步骤组成:(1)给定生成的摘要,问题生成(QG)模型生成一组关于摘要的问题,这些问题的标准答案是摘要中的命名实体和关键短语。(2) 然后使用问答(QA)模型来回答给定源文档的这些问题。(3) 基于相应答案的相似性来计算事实一致性得分。因为在实体层面评估事实一致性,所以这些方法比基于文本蕴涵的方法更易于解释。QG和QA模型的阅读理解能力使这些方法在这项任务中表现良好。然而,这些方法的计算成本很高。
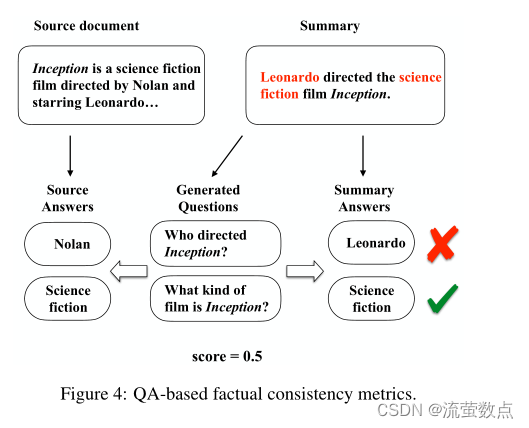
图4:基于QA的事实一致性度量。
Other Methods
其他方法
除了上述专门设计的方法外,还有几种简单但有效的方法来评估事实一致性,这些方法通常用作基线。Durmus等人[2020]提出,事实一致性的一个直接度量是摘要句和源文档之间的单词重叠或语义相似性。基于单词重叠的度量计算输出摘要句子和每个源句子之间的ROUGE[Lin,2004],BLEU[Papineni等人,2002]。然后计算所有源句子的平均分或最大分。
基于语义相似性的度量类似于基于单词重叠的方法。该方法使用BERTScore代替ROUGE或BLEU[Zhang*等人,2020a]。这两种方法显示了基线水平的有效性。
Durmus等人[2020]的实验表明,基于单词重叠的方法在低抽象摘要数据集(如CNN/DM)中效果更好[Hermann等人,2015],基于语义相似性的方法在高抽象摘要数据集中(如XSum)效果更好[Narayan等人,2018]。摘要数据集的抽象性意味着参考摘要相对于源文档的抽象程度。非常重要的是,如果所有参考摘要都是直接从源文档中提取的,那么摘要数据集的抽象性最低。
3.2弱监督度量
专门用于评估事实一致性的弱监督度量设计模型。这些模型是基于从摘要数据集自动生成的合成数据进行训练的,这避免了训练数据的匮乏。根据要评估的对象,现有度量分为三类:句子级、实体级和标记级。
Sentence-level
Kryscinski等人[2020]提出了FactCC,这是一种模型,用于验证摘要句子在源文件中的事实一致性。FactCC通过微调预训练语言模型BERT来实现[Devlin等人,2019],作为二进制分类器。他们还建议从摘要数据集CNN/DM自动生成合成训练数据[Hermann等人,2015]。训练示例是通过首先从源文档中抽取单个句子(后来称为索赔)来创建的。然后,声明通过一组文本转换,输出带有伪正负标签的新颖句子。正例是通过语义不变的变换(如转述)获得的。否定的例子是通过语义变化的转换获得的,如句子否定和实体交换。在测试阶段,FactCC将源文档和摘要语句作为输入,并输出该摘要语句的事实一致性标签。通过模拟不同类型的事实一致性错误,该方法在事实一致性评估中取得了一定的性能改进。但与此同时,这种基于规则的数据集构建方法带来了性能瓶颈。因为很难模拟所有类型的事实不一致错误。
Entity-level
Zhao等人[2020]提出了HERMAN,该方法侧重于评估数量实体(例如数字、日期等)的事实一致性。HERMAN基于序列标记架构,其中输入是源文档和摘要,输出是一系列标签,指示哪些令牌由事实上不一致的数量实体组成。HERMAN的合成训练数据是从摘要数据集XSum自动生成的[Narayan等人,2018]。
Zhao等人[2020]使用引用摘要作为权利要求,而不是将文档句子作为权利要求进行抽样。这些主张被直接标记为积极的总结。通过替换正汇总中的数量实体来获得负汇总。
Token-level
Zhou等人[2020]提出在标记级别上评估事实一致性,这比句子级别和实体级别的评估更细粒度,更易于解释。通过微调预先训练的语言模型来实现该标记级度量。与Zhao等人[2020]一样,参考文献摘要也被直接标记为正面示例,负面示例通过重构部分参考文献摘要获得。该方法与人类事实一致性评估具有更高的相关性。
这些弱监督度量最近引起了广泛关注。但他们仍然需要大量人工注释的数据(源文档、模型生成的摘要以及每个摘要的事实一致性标签)来实现更高的性能。然而,从资金和时间两方面来看,这些数据的制作都非常昂贵。尽管现有的弱监督方法通过启发式自动生成训练数据,但它们使用文档语句或参考摘要来构造正面和负面示例。然而,两者都不同于摘要模型生成的摘要。因此,尽管现有的基于模型的方法在训练数据集中显示出有效性,但当应用于实际一致性评估场景时,效果非常有限。
3.3元评估Meta Evaluation
为了验证上述事实一致性度量的有效性,大多数相关工作通常报告自己的度量与人类注释的事实一致性得分之间的相关性。然而,由于注释设置的多样性,很难通过相关性来比较每个指标不同的作品和不同的注释组之间的分歧。为了衡量不同类型的事实一致性度量的有效性,Gabriel等人;Koto等人【2020;2020】对摘要中的事实一致性进行了元评估。他们通过计算这些指标给出的分数与同一组注释员测量的分数之间的相关性,来评估几个事实一致性指标的质量。
通过元评估,Koto等人[2020]发现,通过在高度抽象的摘要数据集XSum中搜索最佳模型参数(即BERTScore中预训练语言模型的模型层),基于语义相似性的方法可以达到最先进的事实一致性评估性能[Narayan等人,2018]。即使如此,与人类评价的相关性也不超过0.5。因此,事实一致性评价仍然是一个有待探索的问题。
4.事实一致性优化
在本节中,我们概述了优化摘要系统以实现事实一致性的方法。如图5所示,根据每个方法所基于的原则,我们将现有方法大致分为4类:基于事实编码、基于文本蕴涵、基于后期编辑和其他方法。此外,我们将这些方法组织到表2中。
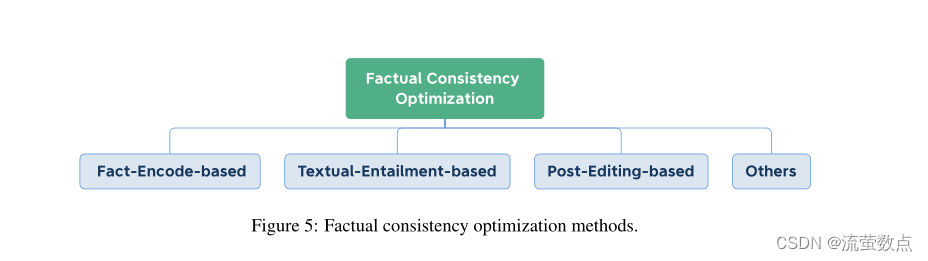
图5:实际一致性优化方法。
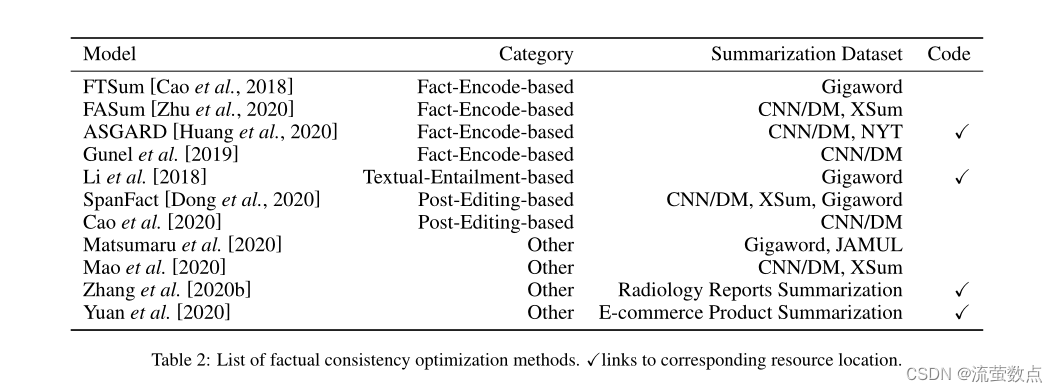
表2:事实一致性优化方法列表。√links到相应的资源位置。
4.1Fact-Encode-based
在最早的关于事实一致性的研究中,大多数作品主要关注内在的事实不一致错误,即与源文件不一致的事实。内在事实不一致错误错误地传达了源文档的事实,这通常表现为不同事实中语义单元的交叉组合。例如,“珍妮喜欢跳舞。鲍勃喜欢踢足球。”⇒ “珍妮喜欢踢足球”。模型误解源文档中的事实是导致固有错误的根本原因。
为了帮助摘要系统正确理解事实,最直观的方法是对源文档中的事实进行显式建模,以增强事实的表示。遵循这个想法,基于事实编码的方法首先提取源文档中的事实,这些事实通常由 (subject; relation; object)(主题;关系;对象)组成的关系三元组表示。然后,这些方法还将提取的事实编码为摘要模型。根据编码事实的方式,这些方法分为两类:顺序编码和基于图的编码。
sequential fact encode
顺序事实编码
Cao等人[2018]介绍了FTSum,它由两个RNN编码器和一个RNN解码器组成。FTSum将源文档中的事实连接到一个名为事实描述的字符串中。一个编码器编码源文档,另一个编码器对事实描述进行编码。解码器在生成摘要时处理这两个编码器的输出。尽管实验结果表明FTSum显著减少了事实不一致的错误,但FTSum很难捕捉所有事实中实体之间的相互作用。
graph-based fact encode
基于图的事实编码
为了解决这个问题,Zhu等人;Huang等人【2020;2020】提出用知识图对源文档中的事实进行建模。FASum(事实感知摘要)[Zhu等人,2020],一种基于变压器的摘要模型,使用图神经网络(GNN)学习每个节点(即实体和关系)的表示,并将它们融合到摘要模型中。与FASum相比,ASGARD(带有图形增强和语义驱动的抽象摘要)Huang等人[2020]进一步使用选择完形奖励来驱动模型获得对输入的语义理解。
除了增强源文档中事实的表示,结合常识知识也有助于总结系统理解事实。因此,Gunel等人[2019]从Wikidata中提取了三个样本关系来构建常识知识图。在这个知识图中,TransE[Bordes等人,2013]是一种流行的多关系数据建模方法,用于学习实体嵌入。摘要系统在对源文档进行编码时关注相关实体的嵌入。通过这种方式,常识知识被纳入摘要系统。
4.2Textual-Entailment-based
基于文本蕴涵
遵循事实一致性摘要在语义上由源文档隐含的想法,[Li等人,2018]提出了一种隐含感知摘要模型,旨在将隐含知识纳入摘要模型。具体来说,他们提出了一对隐含感知编码器和解码器。隐含感知编码器用于同时学习摘要生成和文本隐含预测。隐含感知解码器通过隐含奖励增强最大似然(RAML)训练来实现。RAML[Norouzi等人,2016]提供了一种计算有效的方法来直接优化特定任务的奖励(损失)。在这个模型中,奖励是生成的摘要的隐含分数。
4.3Post-Editing-based
上述两种方法通过修改模型结构,使摘要系统朝着事实一致性的方向优化。与这些方法不同,基于事后编辑的方法通过事后编辑模型生成的摘要来增强最终摘要的事实一致性,这些摘要被视为使用事实更正的摘要草稿。事实更正者将源文档和草稿摘要作为输入,并生成更正后的摘要作为最终摘要。
受QA跨度选择任务的启发,Dong等人[2020]提出了SpanFact,这是一套两个基于跨度选择的事实校正器,分别以迭代或自回归的方式校正摘要草案中的实体。在执行事实校正之前,将屏蔽一个或所有实体(一个以迭代方式,所有以自回归方式)。然后,SpanFact根据对源文档的理解,选择源文档中的跨度来替换相应的掩码标记。
为了训练SpanFact,[Dong等人,2020]自动构建数据集。
人类评估结果显示,SpanFact成功纠正了约26%的事实不一致的摘要,错误地破坏了不到1%的事实一致的摘要。然而,SpanFact仅限于纠正实体错误。比SpanFact更简单,Cao等人[2020]提出了一种端到端事实校正器,可以纠正更多类型的错误。
这种端到端事实校正器通过使用人工数据微调预训练语言模型BART[Lewis等人,2020]来实现。它将损坏的摘要作为输入。输出是更正后的摘要。尽管该方法在概念上可以纠正比SpanFact更多的事实上不一致的错误,但它在人类评估结果上并没有优于SpanFac。
Dong等人[2020]和Cao等人[220]都选择自动构建人工训练数据,而不是使用昂贵的人类注释。
然而,训练阶段(学习纠正损坏的参考摘要)和测试阶段(旨在纠正模型生成的摘要)之间的差距限制了基于后编辑的方法的性能,因为损坏的参考总结与模型生成的总结具有不同的数据分布,这与弱监督的事实一致性度量(§3.2)相同。
4.4其他方法
除上述方法外,还有几种简单但有用的方法和特定领域的方法。
Matsumaru等人[2020]推测,模型有时生成事实上不一致的摘要的原因之一在于用于训练模型的不可靠的文档摘要对。为了缓解这个问题,他们进一步建议使用文本蕴涵分类器来过滤不一致的训练示例。
Mao等人[2020]提出通过在推理阶段(即波束搜索阶段)应用约束来提高事实一致性。具体而言,只有当满足所有约束时,摘要模型才能结束解码。约束是重要的实体和关键短语。由于该方法仅在推理阶段作为即插即用模块工作,因此可以在不修改其内部结构的情况下集成到任何抽象摘要模型中。然而,这种方法可以在多大程度上提高事实的一致性,以及如何设计更有用的约束,仍然是有待探索的问题。
与相对开放的领域摘要(如新闻领域)相比,针对特定领域中事实一致性的优化方法因其领域特征而更为不同。在医疗领域,Zhang等人[2020b]建议优化放射报告摘要的事实一致性。Shah等人[2021]提出优化健康和营养总结的事实一致性。
在电子商务领域,袁等人[2020]建议优化电子商务产品摘要的事实一致性。
5.结论和未来方向
本文首先介绍了抽象摘要中的事实不一致问题。然后,我们概述了评估和改进摘要系统事实一致性的方法。考虑到我们在本文中绘制的景观,我们预测了以下方向:
- 外部误差的优化。现有的事实一致性优化方法主要关注内在错误,而忽略外在错误。我们认为,外部事实不一致错误的主要原因是,当前的最大似然估计训练策略无法明确建模文档和摘要之间的硬约束(例如,实体和引用必须出现在文档中)。如何将这些约束建模到摘要生成过程中是一个值得探索的问题。强化学习可能是实现这一目标的可行方法。
- 段落级指标。大多数评估工作侧重于计算句子级的事实一致性,而不考虑句子之间的关系。段落级评估更具挑战性和价值。
- 其他条件文本生成中的事实一致性。除了标准文本摘要任务外,其他条件文本生成任务(如图像字幕和视觉故事)也存在事实不一致性错误,跨模态事实一致性比单个文本更具挑战性。
上述研究方向绝非详尽无遗,可作为希望解决抽象摘要中事实不一致问题的研究人员的指南。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











