







目的:基于WideResNet网络,通过对人脸和年龄数据集进行训练学习,掌握图像分类的基本实现方法。
一、前期准备
1. 环境要求:
tensorflow-1.14.0,keras,dlib-19.19.0,opencv,matplotlib
2.步骤
(1)准备数据
(2)定义模型结构:超参、网络结构等
(3)模型训练与保存
(4)模型应用
3.原理介绍
-
Dlib是一个C++开源框架,被广泛应用在工业和学术研究领域,包括机器人、嵌入式设备、移动手机以及大规模高性能计算环境中。
主要特点:文档说明全,代码质量高,覆盖机器学习、科学计算、图模型推理、图像处理、多线程、网络编程、图形用户接口、数据压缩与整合等算法
官网:http://dlib.net
-
Wide Residual Networks通过增加网络的通道(channel)数量,实现与增加网络层数相同的模型性能,但是整体参数量更少,训练时间更短。论文介绍参考https://arxiv.org/abs/1605.07146
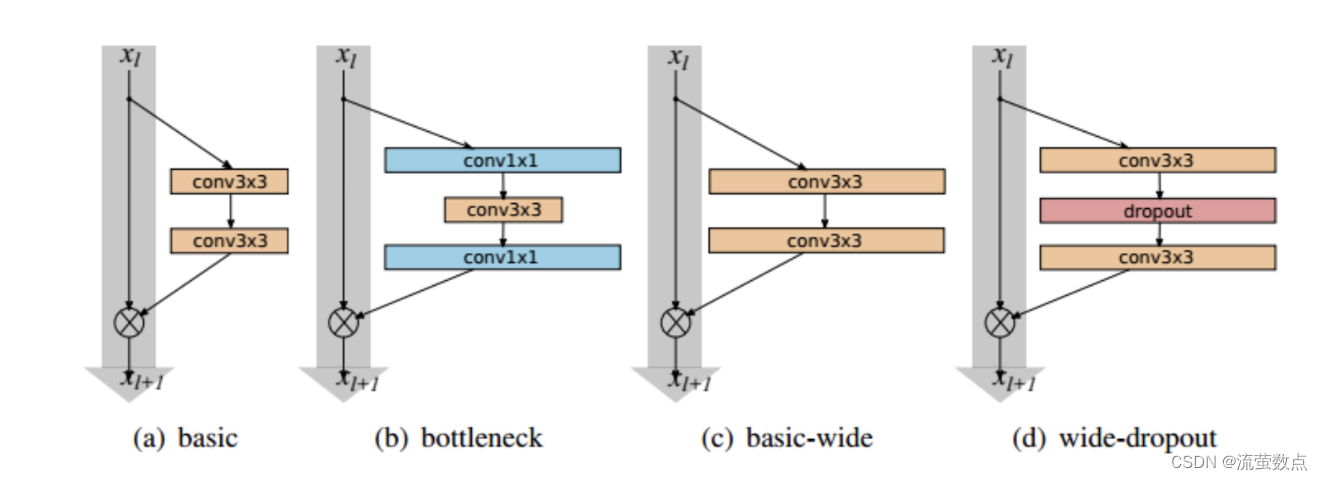
4.数据集
UTKFace数据集是具有较长年龄跨度(范围从0到116岁)的大规模面部数据集。
数据集包含超过20,000张带有年龄,性别和种族标记的面部图像。
图像标记信息包括姿势、面部表情、光线情况、遮挡情况、图像分辨率等信息。
可用于人脸检测、年龄预测和性别预测等。
亮点:
1.由2万张以上的原始人脸图像组成(一张图像中只有一张人脸)
2.提供相应对齐和裁剪的人脸图像
3.提供人脸标记(68点)
下载链接:https://susanqq.github.io/UTKFace/
二、模型训练
1.安装相应的库
- pip默认将Python包安装到系统目录(例如/usr/local/lib/python3.4)。这需要root访问权限。–user 在您的主目录中创建pip安装包,而不需要任何特殊权限。
- Tables是一个简单的命令行工具和强大的库,用于将CSV或JSON文件之类的数据导入关系数据库表中。 目标是使大型数据集的数据导入变得容易,可配置且稳定,以便将其导入关系数据库以进行更好的分析。
# 安装组件完成后,重启kernel
!pip3 install opencv-python
!pip3 install --user tables
# 查看当前kernel下已安装的包 list packages
!pip list --format=columns
tensorflow版本是1.15.0应该降低
pip install tensorflow==1.14.0 
2. 导入库
- argparse 是 Python 内置的一个用于命令项选项与参数解析的模块,通过在程序中定义好我们需要的参数,argparse 将会从 sys.argv 中解析出这些参数,并自动生成帮助和使用信息。具体使用参考Python之 import argparse模块_happy_wealthy的博客-CSDN博客
- sys模块包含了与Python解释器和它的环境有关的函数。
- callback回调函数,回调函数是一组在训练的特定阶段被调用的函数集,你可以使用回调函数来观察训练过程中网络内部的状态和统计信息。具体使用参考Keras中的各种Callback函数示例(含Checkpoint模型的保存、读取示例)-----记录_海淀小天的博客-CSDN博客_keras调用history
- Python使用Scipy库中的io.loadmat读取.mat文件,并获取数据部分
- ImageDataGenerator参数文档图像预处理 - Keras 中文文档
import logging
#设置日志输出级别
logging.basicConfig(level=logging.INFO)
#引入第三方组件包
import pandas as pd
import sys
import argparse
from pathlib import Path
import os
import numpy as np
from keras.callbacks import LearningRateScheduler, ModelCheckpoint
from keras.optimizers import SGD, Adam
from keras.utils import np_utils
from keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
import numpy as np
import cv2
from scipy.io import loadmattensorflow=1.15.0时是这个结果

tensorflow=1.14.0时是这个结果

3.数据集下载
#原始数据下载链接:https://susanqq.github.io/UTKFace/
#准备数据,从OSS中获取数据并解压到当前目录:
import oss2
access_key_id = os.getenv('OSS_TEST_ACCESS_KEY_ID', 'LTAI4G1MuHTUeNrKdQEPnbph')
access_key_secret = os.getenv('OSS_TEST_ACCESS_KEY_SECRET', 'm1ILSoVqcPUxFFDqer4tKDxDkoP1ji')
bucket_name = os.getenv('OSS_TEST_BUCKET', 'mldemo')
endpoint = os.getenv('OSS_TEST_ENDPOINT', 'https://oss-cn-shanghai.aliyuncs.com')
# 创建Bucket对象,所有Object相关的接口都可以通过Bucket对象来进行
bucket = oss2.Bucket(oss2.Auth(access_key_id, access_key_secret), endpoint, bucket_name)
# 下载到本地文件
bucket.get_object_to_file('data/c12/face_age_data.zip', 'person_face_data.zip')
bucket.get_object_to_file('data/c12/unnamed.jpg', 'unnamed.jpg')
![]()
#解压数据
!unzip -q -o person_face_data.zip
!rm -rf __MACOSX
!rm person_face_data.zip4.数据探索
from wide_resnet import WideResNet
from utils import load_data
from mixup_generator import MixupGenerator
from random_eraser import get_random_eraser#本地数据集文件
input_mat_path = "dataset/utkface_small_0.1.mat"
#加载数据集
meta = loadmat(input_mat_path)
#性别数据
gender_list = meta["gender"][0]
#年龄数据
age_list = meta["age"][0]
#人脸数据
image_list = meta["image"]
print("data length:",len(image_list))![]()
5.年龄性别分布情况
#年龄分布情况
hist = plt.hist(age_list, bins=20,color='b')
plt.xlabel("age distribute")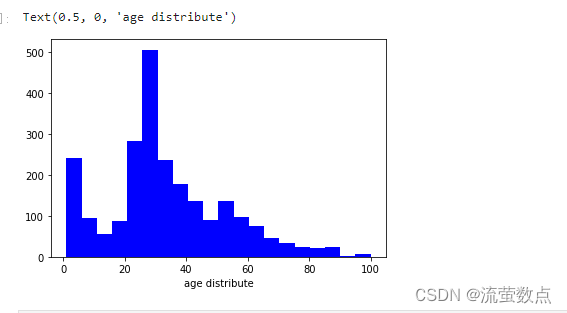
#性别分布情况
hist = plt.hist(gender_list,color='b')
plt.xlabel("gender distribute")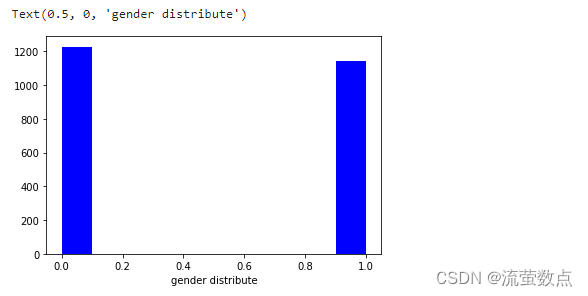
6.图像示例
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
#图像示例
fig_size = plt.rcParams["figure.figsize"]
fig_size[0] = 16
fig_size[1] = 8
plt.rcParams["figure.figsize"] = fig_size
cols, rows = 8, 3
img_num = cols * rows
#随机显示其中24张图像
img_ids = np.random.choice(len(image_list), img_num, replace=False)
for i, img_id in enumerate(img_ids):
plt.subplot(rows, cols, i + 1)
plt.imshow(cv2.cvtColor(image_list[img_id], cv2.COLOR_BGR2RGB))
plt.axis('off')
plt.show()
7.定义模型超参
#批大小
batch_size=1
#训练次数
nb_epochs=1
#学习率
lr=0.01
#学习率优化方法
opt_name='sgd' #or adam
#宽残差网络深度
depth=16 #10, 16, 22, 28
#宽残差网络宽度
k=1
#验证集比例
validation_split=0.1
#是否进行数据增强
use_augmentation=False
#模型输出路径
output_folder="models"
if not os.path.exists(output_folder):
os.makedirs(output_folder)训练次数先为1,不然可能跑不动
8.加载数据
logging.info("Loading data...")
X_data, gender, age, _, image_size, _ = load_data(input_mat_path)
y_data_g = np_utils.to_categorical(gender, 2)
y_data_a = np_utils.to_categorical(age, 101)tensorflow=1.15.0时是这样
![]()
tensorflow=1.14.0时是这样,
![]()
#生成训练集、测试集数据
data_num = len(X_data)
indexes = np.arange(data_num)
#随机混淆数据
np.random.shuffle(indexes)
# 由于模型复杂,这里只使用20张图片进行训练,供演示用
X_data = X_data[indexes][:20]
y_data_g = y_data_g[indexes][:20]
y_data_a = y_data_a[indexes][:20]
#构建输入
train_num = int(len(X_data) * (1 - validation_split))
X_train = X_data[:train_num]
X_test = X_data[train_num:]
#构建输出
y_train_g = y_data_g[:train_num]
y_test_g = y_data_g[train_num:]
y_train_a = y_data_a[:train_num]
y_test_a = y_data_a[train_num:]
print("train_num:",train_num,"eval_num:",len(X_test))![]()
9.定义模型
#定义学习率优化逻辑
class Schedule:
def __init__(self, nb_epochs, initial_lr):
self.epochs = nb_epochs
self.initial_lr = initial_lr
def __call__(self, epoch_idx):
if epoch_idx < self.epochs * 0.25:
return self.initial_lr
elif epoch_idx < self.epochs * 0.50:
return self.initial_lr * 0.2
elif epoch_idx < self.epochs * 0.75:
return self.initial_lr * 0.04
return self.initial_lr * 0.008#定义优化器
def get_optimizer(opt_name, lr):
if opt_name == "sgd":
return SGD(lr=lr, momentum=0.9, nesterov=True)
elif opt_name == "adam":
return Adam(lr=lr)
else:
raise ValueError("optimizer name should be 'sgd' or 'adam'")#定义WideResNet网络结构
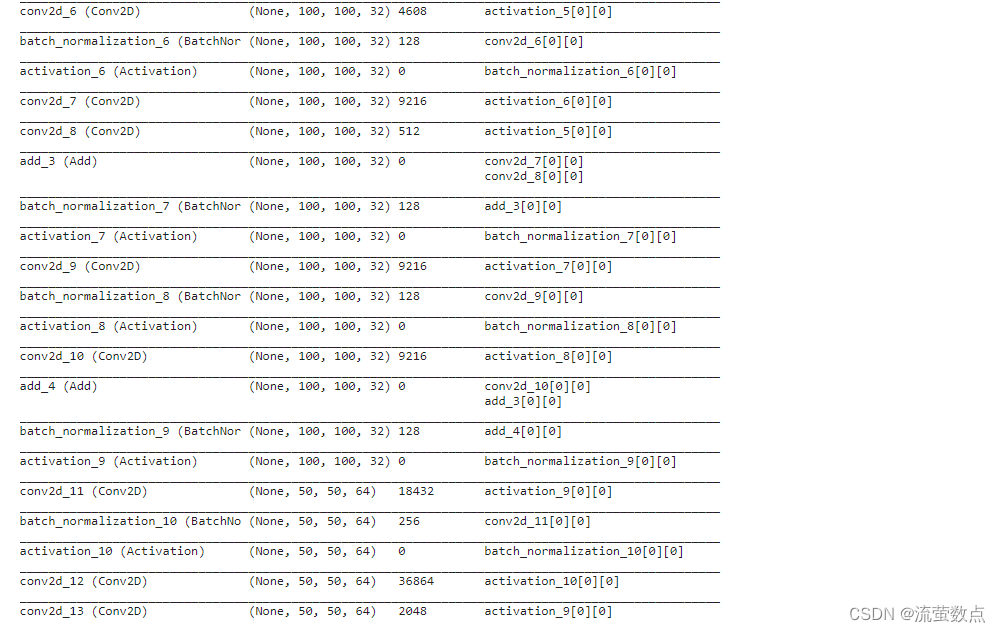
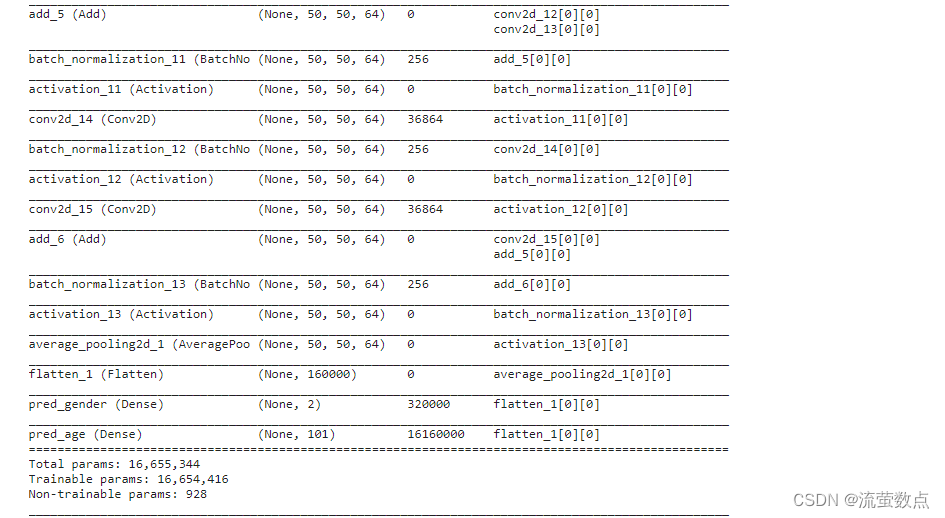
model = WideResNet(image_size, depth=depth, k=k)()
opt = get_optimizer(opt_name, lr)
model.compile(optimizer=opt, loss=["categorical_crossentropy", "categorical_crossentropy"],
metrics=['accuracy'])
logging.info("Model summary...")
model.summary()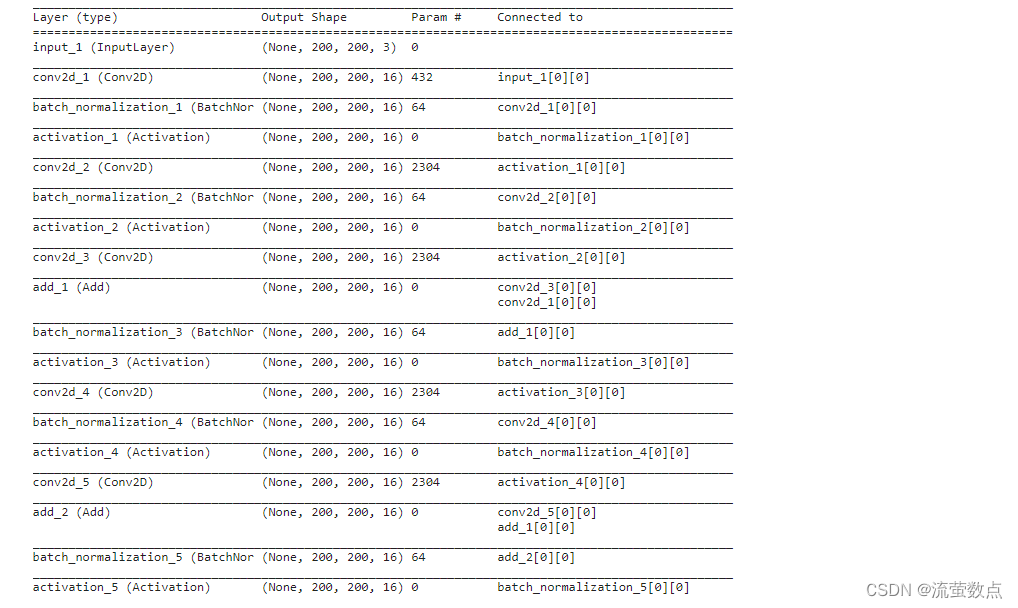
10.模型训练
#训练过程回调
callbacks = [LearningRateScheduler(schedule=Schedule(nb_epochs, lr)),
ModelCheckpoint(str(output_folder) + "/weights.hdf5",
monitor="val_loss",
verbose=1,
save_best_only=True,
mode="auto")
]
logging.info("Running training...")tensorflo=1.15.0时是这样
![]()
tensorflow=1.14.0时是这样
![]()
if use_augmentation:
#图像增强
datagen = ImageDataGenerator(
width_shift_range=0.1,#宽偏移
height_shift_range=0.1,#高偏移
horizontal_flip=True,#水平翻转
preprocessing_function=get_random_eraser(v_l=0, v_h=255))#随机移除
#混合输入和输出
training_generator = MixupGenerator(X_train, [y_train_g, y_train_a], batch_size=batch_size, alpha=0.2,
datagen=datagen)()
hist = model.fit_generator(generator=training_generator,
steps_per_epoch=train_num // batch_size,
validation_data=(X_test, [y_test_g, y_test_a]),
epochs=nb_epochs, verbose=1,
callbacks=callbacks)
else:
hist = model.fit(X_train, [y_train_g, y_train_a], batch_size=batch_size, epochs=nb_epochs, callbacks=callbacks,
validation_data=(X_test, [y_test_g, y_test_a]))tensorflow=1.15.0时,

tensorflow=1.14.0时,

#保存训练历史记录
train_hist_file = output_folder+"/train_history.h5"
pd.DataFrame(hist.history).to_hdf(train_hist_file, "history")tensorflow=1.15.0时,

tensorflow=1.14.0时,

#训练过程可视化
train_hist_file = output_folder+"/train_history.h5"
df = pd.read_hdf(train_hist_file, "history")
input_dir = os.path.dirname(train_hist_file)
# df = hist.history
plt.plot(df["pred_gender_loss"], label="loss (gender)")
plt.plot(df["pred_age_loss"], label="loss (age)")
plt.plot(df["val_pred_gender_loss"], label="val_loss (gender)")
plt.plot(df["val_pred_age_loss"], label="val_loss (age)")
plt.xlabel("number of epochs")
plt.ylabel("loss")
plt.legend()
plt.show()就一代时就是空白
plt.plot(df["pred_gender_acc"], label="accuracy (gender)")
plt.plot(df["pred_age_acc"], label="accuracy (age)")
plt.plot(df["val_pred_gender_acc"], label="val_accuracy (gender)")
plt.plot(df["val_pred_age_acc"], label="val_accuracy (age)")
plt.xlabel("number of epochs")
plt.ylabel("accuracy")
plt.legend()
plt.show()
CPU只能跑一代,穷人不适合搞深度学习,没有GPU,好惨,凑合着学下去吧。
三、模型使用
1.导入库
import dlib#如果环境中不存在dlib,可通过如下命令安装:
!pip install dlib2.模型使用
output_folder = "models"
#网络深度
depth = 16
#网络宽度
k = 8
#头像大小
img_size = 200
#头像边距(用于头像裁剪)
margin = 0
#绘制标签
def draw_label(image, point, label, font=cv2.FONT_HERSHEY_SIMPLEX,
font_scale=0.8, thickness=1):
size = cv2.getTextSize(label, font, font_scale, thickness)[0]
x, y = point
cv2.rectangle(image, (x, y - size[1]), (x + size[0], y), (255, 0, 0), cv2.FILLED)
cv2.putText(image, label, point, font, font_scale, (255, 255, 255), thickness, lineType=cv2.LINE_AA)
#加载模型
def load_model():
detector = dlib.get_frontal_face_detector()
# load model and weights
model = WideResNet(img_size, depth=depth, k=k)()
model.load_weights(output_folder+"/weights_best.hdf5")
return model, detector#模型调用
def do_predict(model, detector, image_path):
img = cv2.imread(str(image_path), 1)
if img is None:
print('image not exist')
return
h, w, _ = img.shape
r = 640 / max(w, h)
img = cv2.resize(img, (int(w * r), int(h * r)))
input_img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_h, img_w, _ = np.shape(input_img)
#使用dlib检测人脸
detected = detector(input_img, 1)
faces = np.empty((len(detected), img_size, img_size, 3))
if len(detected) > 0:
for i, d in enumerate(detected):
x1, y1, x2, y2, w, h = d.left(), d.top(), d.right() + 1, d.bottom() + 1, d.width(), d.height()
xw1 = max(int(x1 - margin * w), 0)
yw1 = max(int(y1 - margin * h), 0)
xw2 = min(int(x2 + margin * w), img_w - 1)
yw2 = min(int(y2 + margin * h), img_h - 1)
cv2.rectangle(img, (x1, y1), (x2, y2), (255, 0, 0), 2)
faces[i, :, :, :] = cv2.resize(img[yw1:yw2 + 1, xw1:xw2 + 1, :], (img_size, img_size))
# 预测年龄和性别
results = model.predict(faces)
# 性别结果
predicted_genders = results[0]
# 年龄结果
ages = np.arange(0, 101).reshape(101, 1)
predicted_ages = results[1].dot(ages).flatten()
# 结果可视化
for i, d in enumerate(detected):
label = "{}, {}".format(int(predicted_ages[i]),
"M" if predicted_genders[i][0] < 0.5 else "F")
draw_label(img, (d.left(), d.top()), label)
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
#设置可视化参数
fig_size = plt.rcParams["figure.figsize"]
fig_size[0] = 16
fig_size[1] = 8
plt.rcParams["figure.figsize"] = fig_size
#调用模型
model, detector = load_model()
do_predict(model,detector,"unnamed.jpg")没运行出来,我真的会谢啊。垃圾CPU,垃圾如我,好难哦。


















 4458
4458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











