









文章目录
参考链接:python3:csv的读写
参考的博客写的还是蛮详细的,笔者就稍微粗糙总结一下。
读取csv文件
test.csv文件中的数据形式如下:
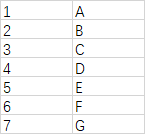
有三种方式读取,分别是file.readlines(),csv.reader(),pandas.read_csv()
file.readlines()
代码示例:
file = 'E:/test.csv'
with open(file) as f:
for re in f.readlines():
print(re, end='')
这种方法首先将所有数据按照行的顺序一次性读取到一个字符串列表中,然后通过迭代的方式逐行读取。
打印结果:
1,A
2,B
3,C
4,D
5,E
6,F
7,G
结果中每一行都是一个字符串,print()方法加上end=’'是为了去掉空行。如果想要分别获取第一列和第二列的元素,可采用split分割:
file = 'E:/test.csv'
with open(file) as f:
for re in f.readlines():
re1,re2 = re.split(',')
print(re1, end='')
print(' ', end='')
print(re2, end='')
这样打印的结果就是每一行两个字符串了。
1 A
2 B
3 C
4 D
5 E
6 F
7 G
插入一个python文件对象读取文件方法:使用文件对象读取Python文件内容
csv.reader()
代码示例:
import csv
file = 'E:/test.csv'
with open(file)as f:
f_csv = csv.reader(f)
for row in f_csv:
print(row)
该方法将文件对象传给csv.reader(),返回一个可迭代对象,然后通过循环读取每一行的数据,读取的结果每一行都是一个两元素的列表。打印结果:
['1', 'A']
['2', 'B']
['3', 'C']
['4', 'D']
['5', 'E']
['6', 'F']
['7', 'G']
pandas.read_csv()
代码示例:
import pandas as pd
file = 'E:/test.csv'
f_csv = pd.read_csv(file, header=None)
print(type(f_csv))
print(f_csv)
该方法直接读取所有数据到一个dataframe中,header=None表示表格没有表头(列名),pandas会自动为每一行每一列匹配一个索引值,打印结果如下:
<class 'pandas.core.frame.DataFrame'>
0 1
0 1 A
1 2 B
2 3 C
3 4 D
4 5 E
5 6 F
6 7 G
此处pandas介绍的比较简单,其他功能参考 pandas读取csv文件
pandas中DataFrame()索引数据中的列或行。
参考:
pandas dataframe属性
pandas dataframe的iloc和loc
总结下来主要有两种方式:
1. loc
使用column名和index名进行定位,通过查看dataframe属性可知column表示列索引,index表示行索引
本文所给例子中自动添加的索引值是0-6和0-1,因此索引值是数值形式,如下:
import pandas as pd
file = 'E:/test.csv'
f_csv = pd.read_csv(file, header=None)
print(type(f_csv))
print(f_csv.index)
print(f_csv.columns)
print(f_csv.loc[0:1,0:1])
结果为:
<class 'pandas.core.frame.DataFrame'>
RangeIndex(start=0, stop=7, step=1)
Int64Index([0, 1], dtype='int64')
0 1
0 1 A
1 2 B
2. iloc
索引方式类似python,采用数值索引,如下:
print(f_csv.iloc[0:1,0:1])
结果如下,需要注意的是索引范围不包括右端值。
0
0 1
写入csv文件
file.write()
file.write()只能用于写入字符串内容,如果需要换行,需要自行添加换行符。文件读写模式“w+”表示可读可写,文件不存在时创建,参考:文件读写模式
str1 = "this is a test file\n"
str2 = "this\n is\n a\n test\n file\n"
file = 'E:/test1.csv'
with open(file,'w+') as f:
f.write(str1)
f.write(str2)
结果如下:
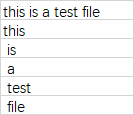
file.writelines()
file.writelines()可一次性写入多个字符串,字符串可用列表的形式,换行仍需添加换行符:
str2 = ["this\n", "is\n", "a\n", "test\n", "file\n"]
file = 'E:/test1.csv'
with open(file,'w+') as f:
f.writelines(str2)
结果如下:

csv.writer()
列表数据
首先将文件对象传递给csv.writer(),创建一个writer对象,然后可以通过f_csv.writerow()写入一行,或者f_csv.writerows()写入多行。
import csv
head = ['id','name','score']
rows = [
[1,'zhangsan',90],
[2,'lisi',60],
]
file = 'E:/test1.csv'
with open(file,'w+') as f:
f_csv = csv.writer(f)
f_csv.writerow(head)
f_csv.writerows(rows)
结果如下:

字典数据
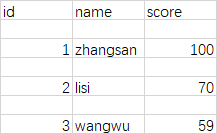
用法和列表数据很类似,先将文件对象传递给csv.DictWriter()创建一个writer对象,只不过需要同时将字典数据的关键字key传入。之后调用writeheader()方法写入表头,writerows()写入多行内容,writerow写入一行内容。
import csv
head = ['id','name','score']
row = {'id':3, 'name':'wangwu', 'score':59}
rows = [
{'id':1, 'name':'zhangsan', 'score':100},
{'id':2, 'name':'lisi', 'score':70},
]
file = 'E:/test1.csv'
with open(file,'w+') as f:
f_csv = csv.DictWriter(f, head)
f_csv.writeheader()
f_csv.writerows(rows)
f_csv.writerow(row)
结果如下:















 1055
1055











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









