







 本文介绍如何使用Spark进行大数据分析,包括统计店铺商品数量、销售额及热门商品等,并展示了如何利用HBase、Hive进行数据存储与处理。
本文介绍如何使用Spark进行大数据分析,包括统计店铺商品数量、销售额及热门商品等,并展示了如何利用HBase、Hive进行数据存储与处理。
[root@gree139 ~]# start-all.sh
[root@gree139 ~]# zkServer.sh start
[root@gree139 ~]# zkServer.sh status
[root@gree139 ~]# hive
[root@gree139 ~]# hbase shell
[root@gree139 ~]# spark-shell
[root@gree139 ~]# cd /opt/exam/
[root@gree139 exam]# ls
meituan_waimai_meishi.csv
[root@gree139 exam]# hdfs dfs -ls /
1.请在 HDFS 中创建目录/app/data/exam,并将 meituan_waimai_meishi.csv 文件传到该
目录。并通过 HDFS 命令查询出文档有多少行数据。
[root@gree139 exam]# hdfs dfs -mkdir -p /app/data/exam
[root@gree139 exam]# hdfs dfs -put ./meituan_waimai_meishi.csv /app/data/exam
[root@gree139 exam]# hdfs dfs -cat /app/data/exam/meituan_waimai_meishi.csv | wc -l
2.使用 Spark,加载 HDFS 文件系统 meituan_waimai_meishi.csv 文件,并分别使用 RDD
和 Spark SQL 完成以下分析(不用考虑数据去重)
// 默认路径是HDFS上的路径
scala> val fileRdd = sc.textFile("/app/data/exam/meituan_waimai_meishi.csv")
scala> fileRdd.collect.foreach(println)
①统计每个店铺分别有多少商品(SPU)。
scala> fileRdd.filter(x=>x.startsWith("spu_id")==false).map(x=>x.split(",",-1)).filter(x=>x.size==12).count
res1: Long = 982
scala> val spuRDD = fileRdd.filter(x=>x.startsWith("spu_id")==false).map(x=>x.split(",",-1)).filter(x=>x.size==12)
scala> spuRDD.collect.foreach(x=>println(x.toList))
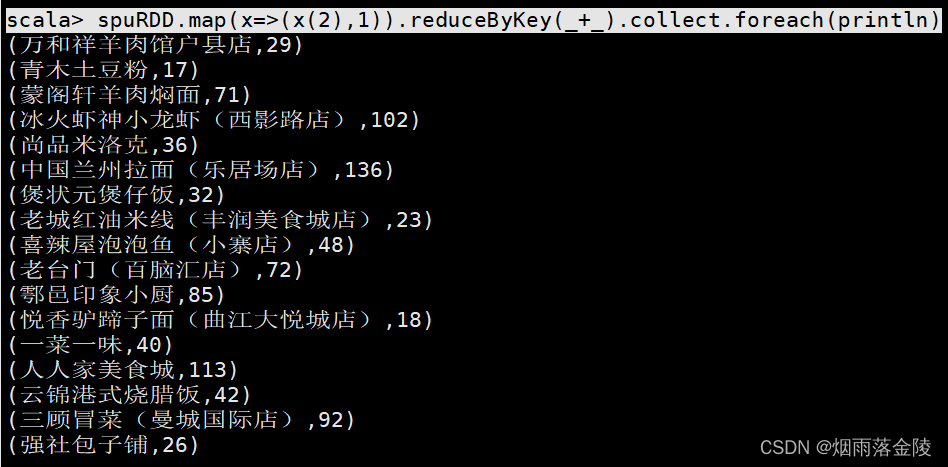
scala> spuRDD.map(x=>(x(2),1)).reduceByKey(_+_).collect.foreach(println)
| x.split(",") 与 x.split(",",-1)区别 scala> sc.parallelize(List("a,b","a,b,c,","a,b,,,")) res6: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[11] at parallelize at <console>:25 scala> res6.map(x=>x.split(",")).foreach(x=>println(x.toList)) List(a, b) List(a, b, c) List(a, b) scala> res6.map(x=>x.split(",",-1)).foreach(x=>println(x.toList)) List(a, b, , , ) List(a, b, c, ) List(a, b) |
②统计每个店铺的总销售额。
scala> spuRDD.map(x=>(x(2),(x(5).toDouble*x(7).toInt))).reduceByKey(_+_).foreach(println)
scala> import scala.util._
import scala.util._
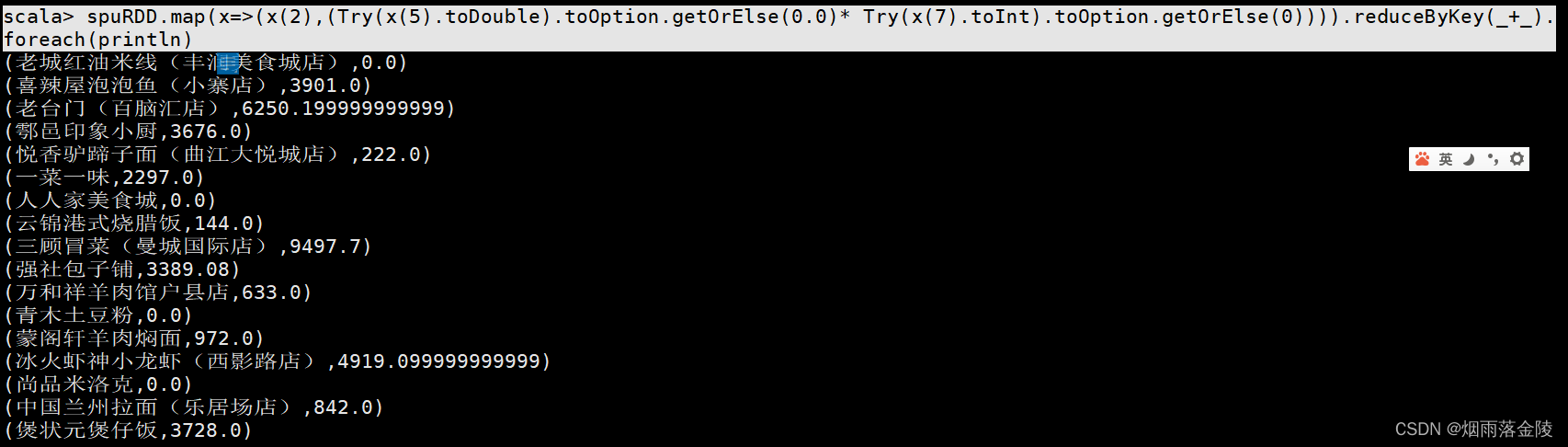
scala>spuRDD.map(x=>(x(2),(Try(x(5).toDouble).toOption.getOrElse(0.0)* Try(x(7).toInt).toOption.getOrElse(0)))).reduceByKey(_+_).foreach(println)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5923
5923

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









