







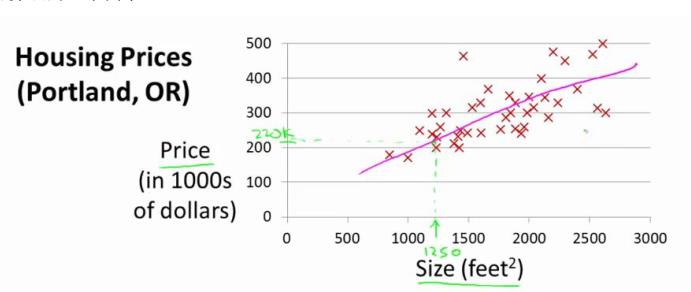
例1:
房屋价格预测,y轴为房屋价格,x轴为房屋大小
给出训练数据,然后用一条直线(或者二次曲线)拟合数据,当有新数据时就可以给出预测结果。
Model
m表示样本数量,x表示输入特征(此例中对应的是房子面积),y表示输出值(此例中对应房子价格),用(x, y)表示训练样本,(xi, yi)表示第i个训练样本,令h为预测函数(hypothesis),去拟合这个样本。
用线性函数拟合,h=a0+a1*x
如果有两个变量,x1表示房屋大小,x2表示房间数量,有h= a0+a1*x1+a2*x2
如果令x0=1,则上式可表示为: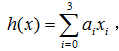
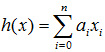
再进一步如果将a和x均表示为列向量,则有更compact的形式: 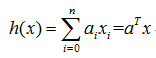
Cost function
模型为
,如何确定参数a?
对于训练数据,选择参数a,使得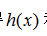
代价函数: 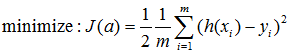
Gradient descent
给定代价函数 ,目标是找到一组θ值,使得代价函数最小。
算法:随机选择一个参数的组合( θ0,θ1,…,θn),计算代价函数,不断改变θ以减小 ,直到减小到一个最小值。
梯度下降具体要做的是,不断迭代更新参数θ,代价函数会不断变小,差不多到代价函数减小到不变时,完成迭代,但这里的迭代次数是要自己确定的。
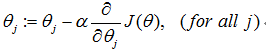
其中,α为learning rate学习率
如果α很小,梯度会下降得很慢
如果α很大,可能越过极小值,使得代价函数会越来越大
注意:当越接近局部极小值时,梯度本来就会变小,就算α不变,参数整体的减小值,也就是步伐也会自动变小,因此,我们不需要改变α来保证梯度下降的收敛。
选择α:可以画出对不同的α,代价的变化曲线,目标是代价J在每次迭代时均有所下降,不能出现波动情况。首先尝试0.001,0.01,0. 1,1,选择使得代价能够最快稳定下降的α,然后在该参数周围进行细化尝试(0.001,0.003,0.01,0.03),也就是*3
线性回归中梯度下降的具体求解过程:
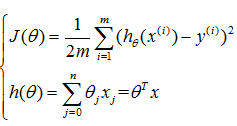
要用梯度下降最小化,关键是获得代价对各个参数的偏导: :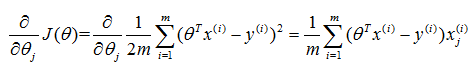
,即也等价于每个样本的偏导分别计算(连加号内部为样本i对第j个参数的偏导),然后再对所有样本相同参数的偏导求均值
最后Repeat: 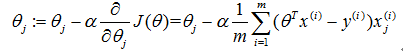
具体实现:
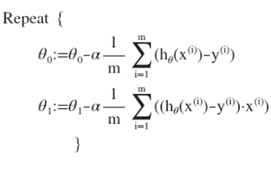
上述算法也称为”Batch” gradient descent,batch是将所有训练样本看成一个group同时处理
Feature Scaling
梯度下降需要保证不同特征在相同尺度,若尺度不一样,会导致代价等高图非常扁,而梯度下降曲线将是锯齿形的,最终会导致收敛非常缓慢。
要保证不同的特征在相同的尺度,一般的数据归一化做法是:求出平均值和标准差,每个特征都先减去均值再除以标准差,这样就能得到均值为0,标准差为1。
Normal Equation
上述的线性回归求解问题,我们可以用另外一种形式理解,并得到闭合解。可以看成是最小二乘问题。
假设有m个样本,每个样本有n个特征,参数求解问题可以用如下方程描述:
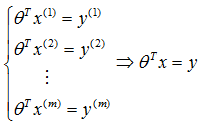
如果样本数m = 特征数n,且上述各方程线性无关,则有唯一解;
如果样本数m > 特征数n,上述方程为超定问题,我们可以找到一组能够尽可能满足所有样本的参数,使得整体误差最小:
整体误差可用代价函数描述,而此时的问题可描述为最小二乘问题,即: 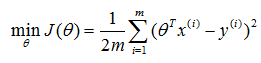
该最小二乘问题有闭合解: 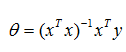
如果样本数m < 特征数n,上述方程为欠定问题,有无数个解,此时可以:
考虑是否有冗余特征(线性相关),如果有的话删除冗余特征
考虑是否真的需要所有这么多特征,可以的话尽量减少
使用正则化(下节)















 6198
6198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









