







1. 整数的变长编码
utf8编码
utf8是一种变长编码方式,使用1~4个字节表示一个符号,参考 字符编码问题。
utf8的编码规则如下表,字母x表示可用比特:
| 字节数 | 二进制表示 | 有效比特数目 | 可表示的最大编码 | 编码范围(16进制) |
|---|---|---|---|---|
| 1 | 0xxxxxxx | 7 | 0x7F | 0000 0000-0000 007F |
| 2 | 110xxxxx 10xxxxxx | 11 | 0x7FF | 0000 0080-0000 07FF |
| 3 | 1110xxxx 10xxxxxx 10xxxxxx | 16 | 0xFFFF | 0000 0800-0000 FFFF |
| 4 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | 21 | 0x1FFFFF | 0001 0000-0010 FFFF |
这种编码方式冗余度较高,每个字节都可以根据它的高位的若干比特确定它在整个二进制表示中的位置(比如是首个字节还是非首个字节),即使字节流中丢一些字节,也能定位出下个字符的起始字节。
有时候这种冗余是不必要的。
protocolbuf中的整数编码
base-128变长编码:
- 每个字节使用低7位表示数字,除了最后一个字节,其他字节的最高位都设置为1
- 采用Little-Endian字节序
例如1的编码是00000001,200(0xC8,110010002)的编码是11001000 00000001(7位一组分为12和10010002,最低有效组在前面)。
其实就是,“0”标识0到0x7F的数字,“10”标识0x80到0x3FFF的数字,“110”标识0x40000到0x1FFFFF的数字……
这些数字是不是很熟,不就是霍夫曼编码么。
这种编码有效的前提是一个数字有比较大的可能性是小数字,也就是高位有比较多的0,也就只适用于0和正整数。
ZigZag编码:
考虑以上编码方法中是对什么进行编码呢?是整数的内存表示,也就是补码,正数的补码就是它本身,负数的补码中会有很多前导1,用上面的方法会占用多个字节,所以只适用于无符号数。对于有符号数,考虑先转换成无符号数。
最简单的想法,把符号位从最高位移到最低位不就行了吗,除了符号位的其他位,用来表示数字的绝对值,以8位整数为例展示这种想法:
| 原数字 | 补码 | 编码方式 | 对应无符号数字 | 负数的编码-2 |
|---|---|---|---|---|
| 0 | 0000 0000 | 0000 0000 | 0 | |
| 1 | 0000 0001 | 0000 0010 | 2 | |
| -1 | 1111 1111 | 0000 0011 | 3 | 0000 0001 |
| 2 | 0000 0010 | 0000 0100 | 4 | |
| -2 | 1111 1110 | 0000 0101 | 5 | 0000 0011 |
转换的数字缺了个1,强迫症受不了,于是把所有负数的编码减去个2就可以了,然后发现负数的新编码的高7位和补码的低7位正好相反。所以,可以这样描述这种新编码方式:非负数是左移1位,负数是最高位移到最低位,其他位取反,可以统一用一个式子来计算(假定的32位整数):(n << 1) ^ (n >> 31),这就是ZigZag编码了。
2. delta-encoding
比如现在有整数列表[250,265,273,345,423],转化成每个整数相对于前一个整数的增量值,增量列表就是[250,15,8,72,73]。数字变小了更容易压缩,比如使用上节中的编码方法。
前缀压缩
让我联想起在leveldb的data block中用到的前缀压缩。
data block中存储的一系列的entry,一个entry是一个key-value对,key和value都是字符串。
各个entry是以key排序的,所以相邻的两个key很可能有一个公共的前缀,为了节省空间,可以采用前缀压缩。
每个entry由以下字段构成:shared_bytes,unshared_bypes,value_bytes,unshared_key_data,value_data。
举个例子,有以下的key:fantastic,fantasyboy,fantasygirl,压缩方式如下:
| shared_bytes | unshared_bypes | unshared_key_data |
|---|---|---|
| 0 | 9 | fantastic |
| 6 | 4 | yboy |
| 7 | 4 | girl |
frame of reference
ElasticSearch使用名为frame of reference的更精细的压缩方式。
具体方法是:
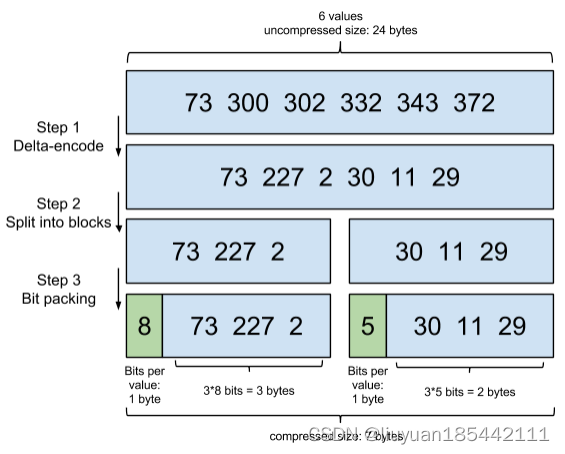
将所有整数进行增量编码,将增量编码分成很多个block,每个block包含256个整数
计算出存储每个block里面所有整数最多需要多少位,把位数作为头信息放在每个block的前面
下图是来自 Frame of Reference and Roaring Bitmaps 中的一个示例(假设每个block只有3个文件而不是256)。
3. bitmap
不是过分稀疏的整数序列用bitmap来存储是比较合适的。
对于特别稀疏的序列,其实也可以用bitmap,不过要配套使用一些压缩方案,比如基于Run-Length Encoding的WAH (Word Aligned Hybrid Compression Scheme),Concise(Compressed ‘n’ Composable Integer Set)等。
Better bitmap performance with Roaring bitmaps 提出了Roaring Bitmap,表现比WAH,Concise更优秀,github 上有多种实现。
下面根据 高效压缩位图RoaringBitmap的原理与应用 简单描述下RoaringBitmap。
将32位无符号整数按照高16位分桶,即最多可能有2^16=65536个桶,论文内称为container。存储数据时,按照数据的高16位找到container(找不到就会新建一个),再将低16位放入container中。也就是说,一个RoaringBitmap就是很多container的集合。
当桶内数据的数量不大于4096时,采用ArrayContainer来存储,其本质上是一个unsigned short类型的有序数组。当桶内数据的数量大于4096时,会采用BitmapContainer来存储,其本质就是普通位图,用长度固定为1024的unsigned long型数组表示,共有2^16个位,可存储65536个数据。















 4361
4361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









