







##K-近邻算法的基本思路
- 已知 N 个 已 知 类 别 的 样 本 X N个已知类别的样本X N个已知类别的样本X;
- 输入未知类别的样本 x x x;
- 计算 x 到 x i ∈ X , ( i = 1 , 2 , ⋅ ⋅ ⋅ , N ) 的 距 离 d i ( x ) x到x_i\in{X},(i = 1,2,···,N)的距离d_i(x) x到xi∈X,(i=1,2,⋅⋅⋅,N)的距离di(x);
- 找到 x 的 k 个 最 近 邻 元 x k = x i , i = 1 , 2 , ⋅ ⋅ ⋅ , k x的k个最近邻元x_k = {x_i,i = 1,2,···,k} x的k个最近邻元xk=xi,i=1,2,⋅⋅⋅,k;
- 看 x k 中 属 于 哪 一 类 的 样 本 最 多 x_k中属于哪一类的样本最多 xk中属于哪一类的样本最多;
- 最终判断未知样本属于那一类 x x x。
##Matlab代码实现
clear all;
close all;
clc;
%X为标记好的样本集,样本为将1至40的数分为2类
%1-20里的10个随机数为一类,21-40里的10个随机数为一类
X = [8,9,17,14,18,12,2,10,16,20,24,34,25,40,31,38,22,21,27,26];
[r,c] = size(X);
%标记好的两类
w1 = [8,9,17,14,18,12,2,10,16,20];
w2 = [24,34,25,40,31,38,22,21,27,26];
%x为要被分类的样本
T = 1:40;%选取类的范围里的随机序列,共40个数
R = randperm(40);%将1至40随机数打乱
x = T(R(1));
disp('随机数x为:');
disp(num2str(x));
%k为邻居数目(k-个近邻)
k = 7;
%计算距离
d = zeros(r,c);
for i = 1:c
d(i) = abs(X(i)-x);
end
%找出k个最小距离
xk = zeros(1,k);%存储最近邻元
for i = 1:k
[di ,n] = min(d);%找到最短距离di,以及算在的位置
xk(i) = X(n);
d(n) = 40;%为了获得其他的最小值将查询到的最小值赋值为最大值
end
%判断属于的类别
k1 = 0;%属于w1的样本个数
for i = 1:k
for j = 1:10
if xk(i) == w1(j)
k1 = k1+1;
end
end
end
k2 = k - k1;%%属于w2的样本个数
if k2<k1
disp( '随机数x属于w1类:');
disp( num2str(w1));
break;
else
disp( '随机数x属于w2类:');
disp( num2str(w2));
break;
end
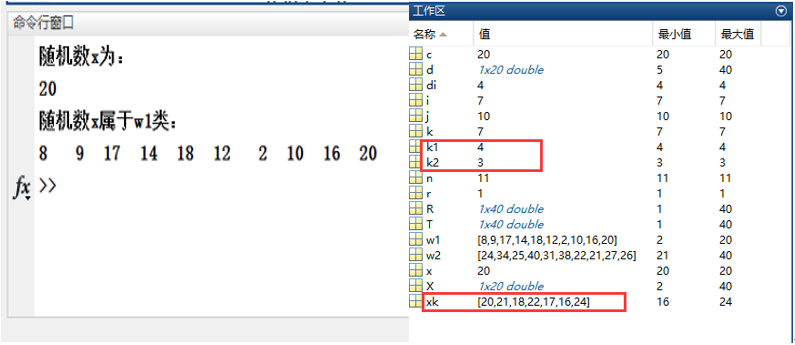
##结果图















 1716
1716

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









