







k 近邻法 (k-NN) 是一种基于实例的学习方法,无法转化为对参数空间的搜索问题(参数最优化 问题)。它的特点是对特征空间进行搜索。除了k近邻法,本章还对以下几个问题进行较深入的讨 论:
- 切比雪夫距离 的计算
- "近似误差" 与“估计误差" 的含义
- k-d树搜索算法图解
一、算法
输入:训练集 为实例特征向 为实例的类别,
输出:实例 所属的类
设在给定距离度量下,涵盖最近k个点的邻域为
其中示性函数 为真为假
寻找使得函数 取得最大值的变量 也就是说, 看看距离 最近的k个点里面哪一类别最多,以此作为输出。
二、模型
根据模型的分类, k-NN模型属于非概率模型。
观察 可发现它与感知机不同的之处, 作为决策函数, 它并不需要任何未知参数(感知机需要确定W和b),直接从训练集的数据得到输出。
1. 距离度量
k-NN的基本思想是,特征空间中的距离反映了两个点的相似程度, 因此 “距离" 是作出分类判断 的基本依据。向量空间 的距离有多种度量方式:
(1) 不同距离度量
一般形式是闵可夫斯基距离( 范数):
当p=1时, 称为曼哈顿距离( 范数):
当p=2时,称为欧几里得距离( 范数),也就是最常用的距离::
import math
from itertools import combinations
def L(x, y, p=2):
# x1 = [1, 1], x2 = [5,1]
if len(x) == len(y) and len(x) > 1:
sum = 0
for i in range(len(x)):
sum += math.pow(abs(x[i] - y[i]), p)
return math.pow(sum, 1 / p)
else:
return 0
下图表示平面上A、B两点之间不同的距离: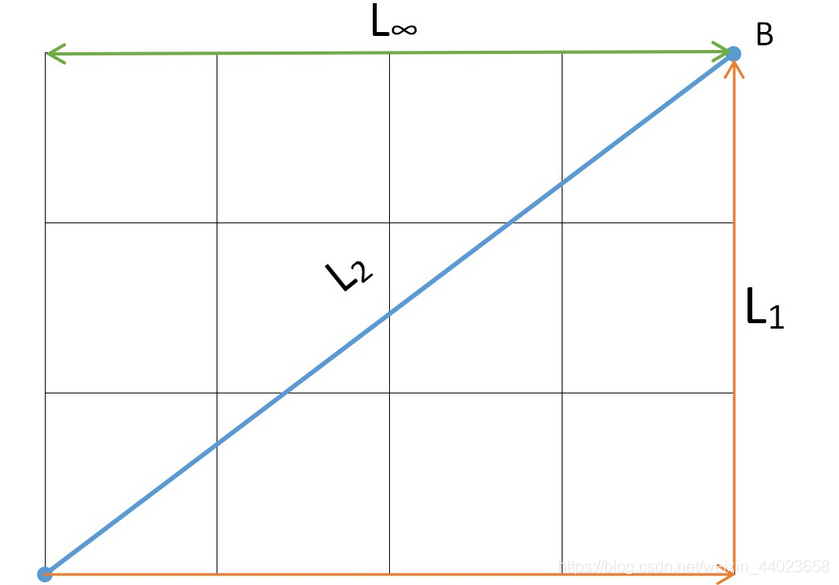
- 只允许沿着坐标轴方向前进, 就像曼哈顿街区的出租车走过的距离
- 两点之间直线最短, 通过勾股定理计算斜边的距离
- 只剩下一个维度, 即最大的分量方向上的距离
可见p取值越大,两点之间的距离越短。
(2) 问题:为什么切比雪夫距离
其实这个问题等价于:为什么 即 空间中的向量 它的切比雪 夫长度等于它的最大分量方向上的长度。
证明: 设
不妨设 即
注意:最大分量的长度唯一, 但最大分量可能并不唯 一,设有x^{(1)}, x^{(2)}, \ldots x^{(k)}等个分量的长度都等于\left|x^{(1)}\right|$
当 即 为 时
当 即 为非最大长度分量时
计算 的切比雪夫长度:
由于已知 等于0或1,且有k个分量结果为1, 所以
因此
即 得证。
以上证明参考
(3) 平面上的圆
在平面上的图像: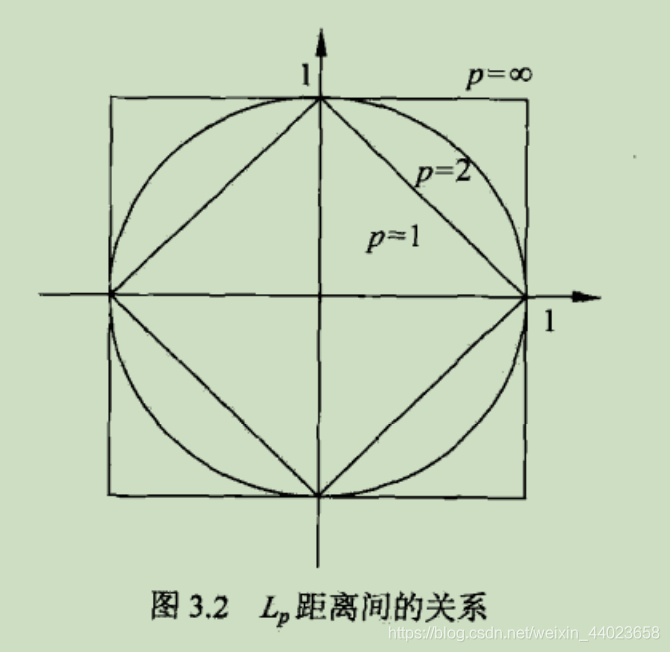 如果圆形的定义是 “到某一点距离相等的曲线围成的图形" ,那么在不同的距离度量下,圆形的形 状可以完全不同。为何 正则化在平面上的等高线为同心正方形, 不就很容易理解吗?
如果圆形的定义是 “到某一点距离相等的曲线围成的图形" ,那么在不同的距离度量下,圆形的形 状可以完全不同。为何 正则化在平面上的等高线为同心正方形, 不就很容易理解吗?
- k值选择
李航老师书中引入了“近似误差”和“估计误差”两个概念,但没有给出具体定义。
这里简单总结一下:
右侧两项分别是 "估计误差" 和 "近似误差"
- 估计误差:训练集与无限数据集得到的模型的差距
- 近似误差:限制假设空间与无限制假设空间得到的模型的差距
- k值越小 单个样本影响越大 模型越复杂 假设空间越大 近似误差越小 (估计误差 越大),容易过拟合;
- k值越大 单个样本影响越小 模型越简单 假设空间越小 近似误差越大(估计误差 越小),容易欠拟合。
一般通过交叉验证来确定最优的 k 值。
- 决策规则
k 近邻的决策规则就是 “多数表决" ,即少数服从多数, 用数学表达式表示为
等号左侧为误分类率,要是误分类率最小,就要使得 最大, 即选择集合 中最多的一类。
三、kd树
kd 树的结构
kd树是一个二叉树结构,它的每一个节点记载了 [特征坐标, 切分轴, 指向左枝的指针, 指向右枝的指针] 。其中, 特征坐标是线性空间 中的一个点
切分轴由一个整数 表示, 这里 是我们在 维空间中沿第 维进行一次分割。节点的左枝和右枝分别都是 kd 树, 并且满足:如果 是左枝的一个特征坐标, 那么 并且如果 是右 枝的一个特征坐标,那么
给定一个数据样本集 和切分轴 以下递归算法将构建一个基于该数据集的 kd 树, 每一次循环制作一 个节点:
如果 记录 中唯一的一个点为当前节点的特征数据, 并且不设左枝和右枝。 指集合 中元素 . 的数量) 如果
如果
- 将 S 内所有点按照第 个坐标的大小进行排序;
- 选出该排列后的中位元素 (如果一共有偶数个元素, 则选择中位左边或右边的元素, 左或右并无影响),作为当前节点的特征坐标, 并且记录切分轴 将 设为在 中所有排列在中位元素之前的元素; 设为在 中所有排列在中位元素后的元素;
- 当前节点的左枝设为以 为数据集并且 为切分轴制作出的 树; 当前节点的右枝设为以 为数据集并且 为切分轴制作出 的 kd 树。再设 这里, 我们想轮流沿着每一个维度进 行分割; 是因为一共有 个维度, 在 沿着最后一个维度进行分割之后再重新回到第一个维度。)
构造 kd 树的例子
上面抽象的定义和算法确实是很不好理解,举一个例子会清楚很多。首先随机在 中随机生成 13 个点作为我们的数据集。起始的切分轴 这里 对应 轴, 而 对应 轴。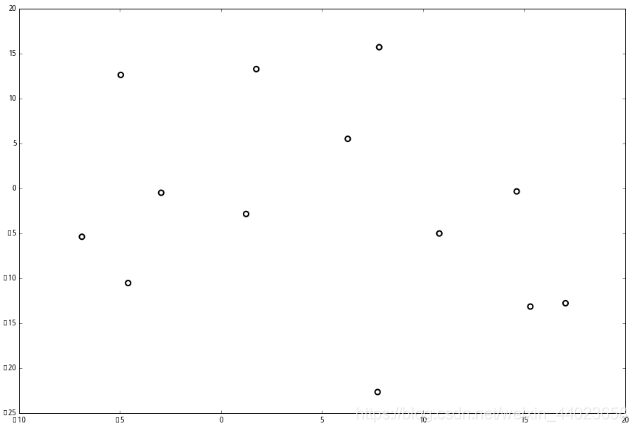 首先先沿 x 坐标进行切分,我们选出 x 坐标的中位点,获取最根部节点的坐标
首先先沿 x 坐标进行切分,我们选出 x 坐标的中位点,获取最根部节点的坐标
并且按照该点的x坐标将空间进行切分,所有 x 坐标小于 6.27 的数据用于构建左枝,x坐标大于 6.27 的点用于构建右枝。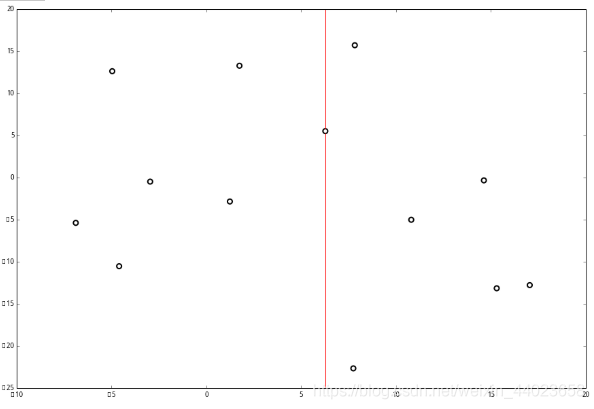 节点。得到下面的树,左边的x 是指这该层的节点都是沿 x 轴进行分割的。
节点。得到下面的树,左边的x 是指这该层的节点都是沿 x 轴进行分割的。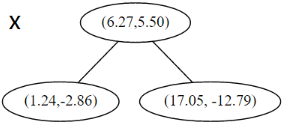 空间的切分如下
空间的切分如下 下一步中 对应 轴, 所以下面再按照 除标进行排序和切分,有
下一步中 对应 轴, 所以下面再按照 除标进行排序和切分,有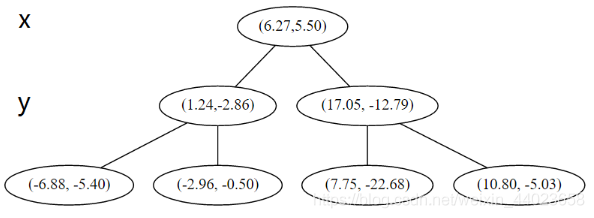
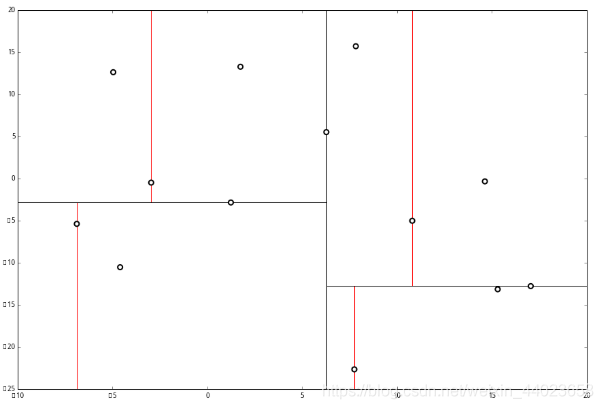 最后每一部分都只剩一个点,将他们记在最底部的节点中。因为不再有未被记录的点,所以不再进行切分。
最后每一部分都只剩一个点,将他们记在最底部的节点中。因为不再有未被记录的点,所以不再进行切分。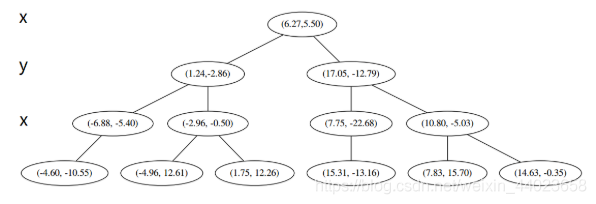
 就此完成了 kd 树的构造。
就此完成了 kd 树的构造。
kd 树上的 kNN 算法
给定一个构建于一个样本生的 kd 树, 下面的算法可以寻找距离某个点 最近的 个样本。
设 为一个有 个空位的列表, 用于保存已搜寻到的最近点.
根据 的坐标值和每个节点的切分向下搜素(也就是选,如果树的节点是按照 进行切分,并且 的 坐标小于 则向左枝进行搜索: 反之则走右枝)。
当达到一个底部节点时,将其标记为访问过. 如果 里不足 个点. 则将当前节点的特征坐标加人 如 果 L不为空并且当前节点 的特征与 的距离小于 里最长的距离,则用当前特征音换掉 中离 最远的点
如果当前节点不是整棵树最顶而节点, 执行 下(1):反之. 输出 算法完成. (1) . 向上爬一个节点。如果当前 (向上爬之后的) 节点未管被访问过, 将其标记为被访问过, 然后执行 1和2:如果当前节点被访 问过, 再次执行 (1)。
- 如果此时 里不足 个点, 则将节点特征加入 如果 中已满 个点, 且当前节点与 的距离小于 里最长的距离。则用节点特征豐换掉 中帝最远的点。
- 计算 和当前节点切分綫的距离。如果该距离大于等于 中距离 最远的距离井且 中已有 个点。则在切分线另一边不会有更近的点, 执行3: 如果该距离小于 中最远的距离或者 中不足 个点, 则切分綫另一边可能有更近的点, 因此在当前节点的另一个枝从 开始执行.
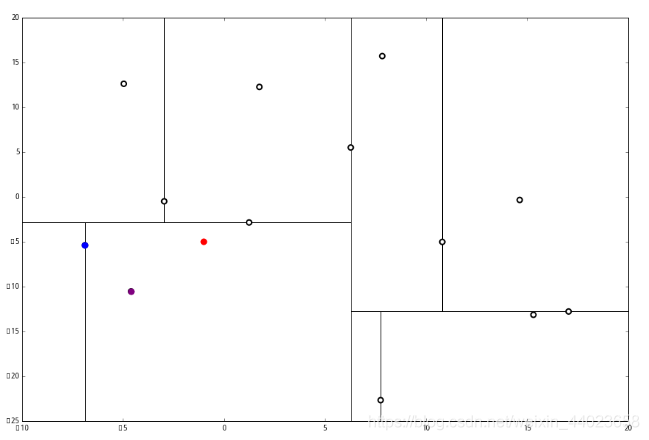
来看下面的例子: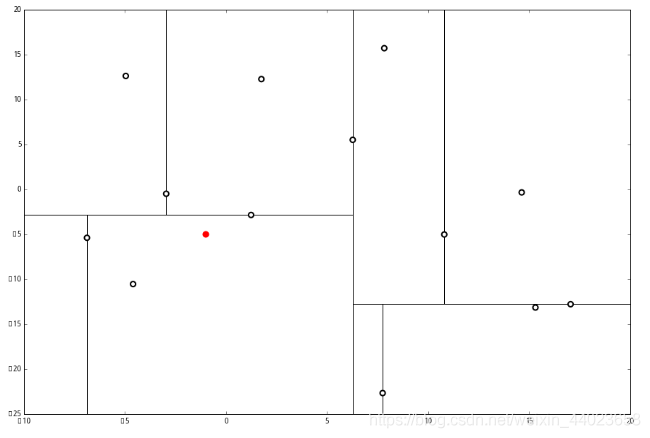 首先执行1,我们按照切分找到最底部节点。首先,我们在顶部开始
首先执行1,我们按照切分找到最底部节点。首先,我们在顶部开始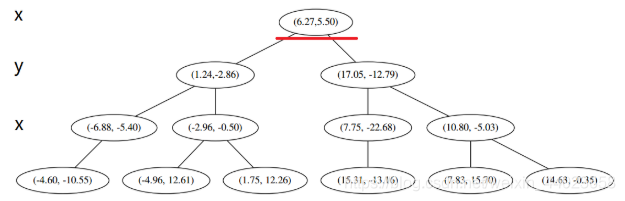 和这个节点的 x轴比较一下,
和这个节点的 x轴比较一下,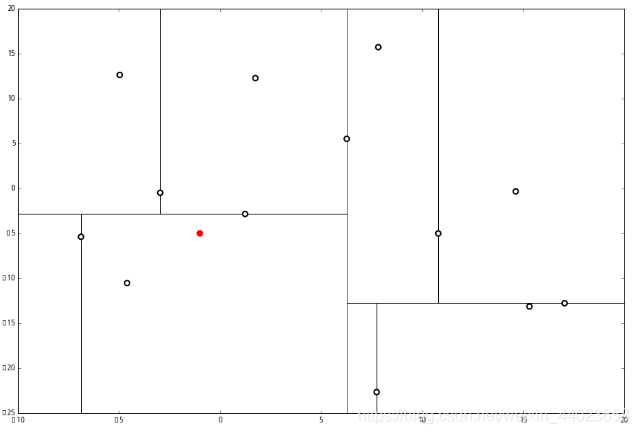 ppp 的 x 轴更小。因此我们向左枝进行搜索:
ppp 的 x 轴更小。因此我们向左枝进行搜索: 这次对比 y 轴,
这次对比 y 轴,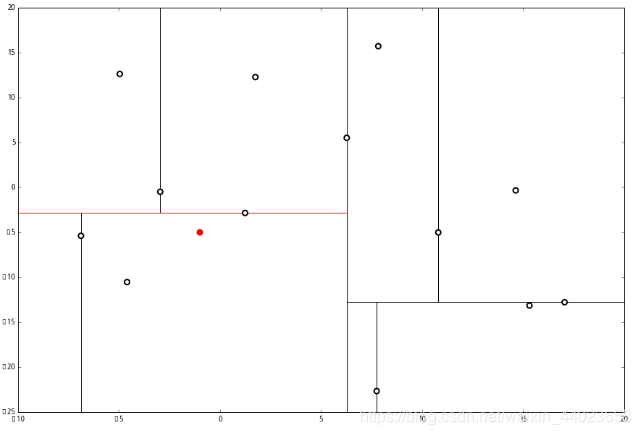 p 的 y 值更小,因此向左枝进行搜索:
p 的 y 值更小,因此向左枝进行搜索: 这个节点只有一个子枝,就不需要对比了。由此找到了最底部的节点 (−4.6,−10.55)。
这个节点只有一个子枝,就不需要对比了。由此找到了最底部的节点 (−4.6,−10.55)。 在二维图上是
在二维图上是 此时我们执行2。将当前结点标记为访问过, 并记录下 访问过的节点就在二叉树 上显示为被划掉的好了。
此时我们执行2。将当前结点标记为访问过, 并记录下 访问过的节点就在二叉树 上显示为被划掉的好了。
然后执行 3,不是最顶端节点。执行 (1),我爬。上面的是 (−6.88,−5.4)。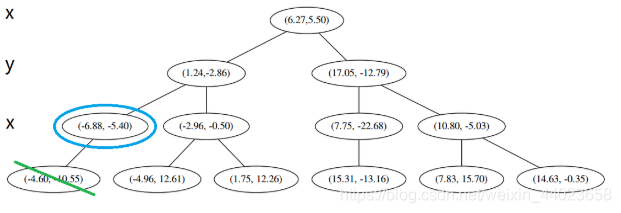
执行 1,因为我们记录下的点只有一个,小于k=3,所以也将当前节点记录下,有 L=[(−4.6,−10.55),
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 294
294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









