









 本文详细探讨了使用砝码分盐问题的解决方案,从数学角度和编程实现两个方面进行分析。作者介绍了如何通过改进的搜索方法减少无效节点的创建,实现了在三次称量中找到正确解的算法,并提供了相关代码实现。文章还讨论了方法的效率和空间优化,以及后续可能的改进方向。
本文详细探讨了使用砝码分盐问题的解决方案,从数学角度和编程实现两个方面进行分析。作者介绍了如何通过改进的搜索方法减少无效节点的创建,实现了在三次称量中找到正确解的算法,并提供了相关代码实现。文章还讨论了方法的效率和空间优化,以及后续可能的改进方向。
本博客(http://blog.csdn.net/livelylittlefish )贴出作者(阿波)相关研究、学习内容所做的笔记,欢迎广大朋友指正!
Content
5.1基本思想
5.2 第2次称量过程
5.3 第3次称量过程
5.4如何创建节点?
5.5输出结果
5.6讨论
附录 4 :再改进的方法的代码weight3.1.c/3.2.c/3.3.c
附录 5 :再改进的方法的代码weight3.1.c/3.2.c/3.3.c 的输出结果
附录 7 :一个更简单的方法的代码weight5.1.c/5.2.c/5.3.c
5. 再改进的方法
从上图中,删除那些有分解结果但结果并非所求的节点,包括中间节点和叶子节点,如下图所示。
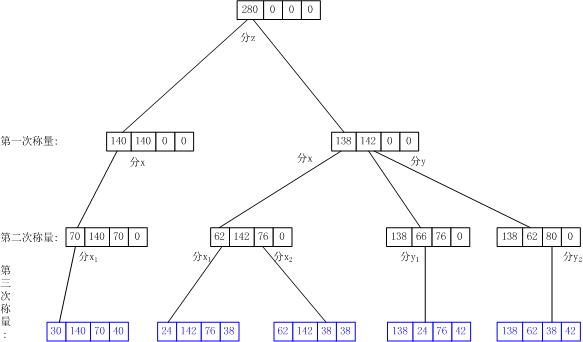
那么,能否通过编程直接计算求得上图所有正确的解呢?
——一定可以。关键就看怎么编程实现目标了。
5.1 基本思想
在第4节程序的基础上,继续修改代码,删除weight3()函数,直接在weight2()中对第2次称量并对第2次称量的结果进行再分解(即第3次称量),并对第3次分解结果进行判断,只有当该称量过程满足目标时,才建立节点,包括第2层和第3层的节点。这样,没有分解结果的节点(包括第2层和第3层的节点)就不会被建立,如上图,叶子节点全部是正确的分解结果。不仅让问题更直观,且节省了空间,虽然空间并不那么重要。
5.2 第2次称量过程
如上所述,第2次称量过程中要对第2次称量分解的结果进行再分解(第3次称量),并对第3次分解结果进行判断,这就是该方法的重点实现过程,如下。第1次称量过程的代码及具体的代码请参考附录4。
00095: / ** the second division, according to x=x1+x2, y=y1+y2, x1<=x2, y1<=y2
00096: but, x and y are saved in node1- >to_be_divided_[0] and node1- >to_be_divided_[1].
00097: so, unify them to be as x.
00098: */
00099: void weight2()
00100: {
00101: int div = 0, i = 0, k1 = 0, w = 0;
00102: struct Division_Node *cur = &root;
00103:
00104: int step = 2;
00105: for (i = 0; i < cur->child_; i++) //for each node1 in step1
00106: {
00107: struct Division_Node *node1 = cur->next_[i]; //step 2 will use all nodes created in step 1
00108:
00109: //to avoid repeatance
00110: int to_be_divided = To_Be_Devided;
00111: if (node1->heap_[node1->to_be_divided_[0]] == node1- >heap_[node1->to_be_divided_[1]])
00112: to_be_divided-- ;
00113:
00114: int child1 = 0;
00115: for (div = 0; div < to_be_divided; div++)//step2, will divide x=heap_[0],y=heap_[1] of node1
00116: {
00117: int curpos1 = node1->to_be_divided_[div];
00118: int x = node1->heap_[curpos1]; //the current heap to be divided
00119:
00120: for (k1 = 0; k1 < Max_Num; k1++) //divide x=x1+x2, use x in order to be in a uniform
00121: {
00122: w = ws[k1];
00123: int x1 = (x - w)/ 2;
00124: int x2 = (x + w)/ 2;
00125: if (x1 % 2 != 0) //no need to judge x2
00126: continue;
00127:
00128: struct Division_Node *node2 = NULL;
00129: int child2 = 0;
00130:
00131: /** a correct solution, and only in this case, create node2 and node3 */
00132: child2 = weightx1(curpos1, step, x1, x2, child1, child2, node1, &node2);//divide x1
00133: if (x2 != x1) //to avoid repeatance
00134: child2 = weightx2(curpos1, step, x1, x2, child1, child2, node1, &node2);//divide x2
00135:
00136: if (node2)
00137: {
00138: node2->child_ = child2;
00139: child1++;
00140: }
00141: }
00142: }
00143: node1->child_ = child1;
00144: }
00145: }5.3 第3次称量过程
该方法中,第3次称量过程在weightx1()和weightx2()中完成,且是第2次过程中嵌套进行,即通过weight2()调用完成。由于weightx1()和weightx2()思想相同,此处以weightx2()为例叙述,其他的代码可参考附录4。
00173: int weightx2(int curpos1, int step, int x1, int x2, int child1, int child2,
00174: struct Division_Node* node1, struct Division_Node **node2)
00175: {
00176: int k2 = 0, w = 0;
00177: int curpos2 = step;
00178:
00179: for (k2 = 0; k2 < Max_Num; k2++)
00180: {
00181: w = ws[k2];
00182: int x21 = (x2 - w)/ 2; //divide x or y, use x in order to be in a uniform
00183: int x22 = (x2 + w)/ 2;
00184: if (x21 % 2 != 0) //no need to judge x12
00185: continue;
00186:
00187: if (x21 + x1 == heap1 || x22 + x1 == heap1)
00188: {
00189: *node2 = create_node(node1, *node2, curpos1, curpos2, step, x1, x2, x21, x22,
00190: child1, child2);
00191: child2++;
00192: break;
00193: }
00194: }
00195:
00196: return child2;
00197: }该分解过程如下。
(1) 第1次称量:z=x+y, x<=y
(2) 第2次称量:x=x1+x2, x1<=x2
(3) 第3次称量:x2=x21+x22, x21<=x22
最后的分解结果为(x1, x21, x22, y),故需要判断x1+x21或x1+x22是否为heap1=100,如代码所示。实际上,对第1次称量出的y的分解在weight2()第115行的for循环中完成,即统一为以上过程。
5.4 如何创建节点?
如上所述,只有在满足目标时,才建立节点,包括第2层和第3层的节点,即代码中的node2和node3。如下。
00199: struct Division_Node *create_node(struct Division_Node *node1, struct Division_Node *node2,
00200: int curpos1, int curpos2, int step, int x1, int x2, int x11, int x12, int child1, int child2)
00201: {
00202: if (node2 == NULL) //此处放置重复创建node2(当node2有多个儿子节点时)
00203: {
00204: //new a node in step 2
00205: node2 = (struct Division_Node*)malloc(sizeof(struct Division_Node));
00206: memset(node2, 0, sizeof(struct Division_Node));
00207: memcpy(node2->heap_, node1->heap_, (Max_Num - 1) * sizeof(int)); //copy from its parent
00208: node2->parent_be_divided_ = curpos1;
00209: node2->step_ = step;
00210: node2->heap_[curpos1] = x1;
00211: node2->heap_[step] = x2;
00212: node2->to_be_divided_[0] = curpos1;
00213: node2->to_be_divided_[1] = step;
00214: node1->next_[child1] = node2; //link current node1 and node2
00215: }
00216:
00217: //new a node in step 3
00218: struct Division_Node *node3 = (struct Division_Node*)malloc(sizeof(struct Division_Node));
00219: memset(node3, 0, sizeof(struct Division_Node));
00220: memcpy(node3->heap_, node2- >heap_, (Max_Num - 1) * sizeof(int)); //copy from its parent
00221: node3->parent_be_divided_ = curpos2;
00222: node3->step_ = step + 1;
00223: node3->heap_[curpos2] = x11;
00224: node3->heap_[step + 1] = x12;
00225: node3->to_be_divided_[0] = curpos2; //in fact, this array in step3 needed for dump
00226: node3->to_be_divided_[1] = step + 1;
00227: node2->next_[child2] = node3; //link current node2 and node3
00228:
00229: return node2;
00230: } ? end create_node 5.5 输出结果
-------------------------------------
the results of all correct divisions:
-------------------------------------
280 = 140 + 140
140 = 70 + 70
70 = 30 + 40
280 = 138 + 142
138 = 62 + 76
62 = 24 + 38
280 = 138 + 142
138 = 62 + 76
76 = 38 + 38
280 = 138 + 142
142 = 66 + 76
66 = 24 + 42
280 = 138 + 142
142 = 62 + 80
80 = 38 + 42这就是所有满足目标的正确称量过程,即上图中的所有叶子节点的值。该方法的3中写法可参考附录4,其输出结果可参考附录5。
5.6 讨论
该方法如其基本思想,对第3次分解结果进行判断,只有当该称量过程满足目标时,才建立节点,包括第2层和第3层的节点,从而叶子节点全部是正确的分解结果,让问题更直观,且节省了大量空间,虽然空间并不那么重要。
附录4:再改进的方法的代码weight3.1.c/3.2.c/3.3.c
附录5:再改进的方法的代码weight3.1.c/3.2.c/3.3.c的输出结果
-------------------------------------
the results of all correct divisions:
-------------------------------------
280 = 140 + 140
140 = 70 + 70
70 = 30 + 40
280 = 138 + 142
138 = 62 + 76
62 = 24 + 38
280 = 138 + 142
138 = 62 + 76
76 = 38 + 38
280 = 138 + 142
142 = 66 + 76
66 = 24 + 42
280 = 138 + 142
142 = 62 + 80
80 = 38 + 42
















 4415
4415

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









