







关于网页网游大家应该已经有所感受了。现在最火的莫过于kaixin001的种菜养动物了。大家偷菜种菜乐此不疲。不过怎么才能自动的进行偷菜呢?我自己简单的分析了一下,并实现了一个kaixin001菜地杀手。一下简述了从分析到开发的整个过程。虽然没有将所有代码都分享出来,但是下边的分析足够大家写一个类似的程序了。大家可以去http://orion.zhangle.googlepages.com 来下载这个程序。
一.分析
我们知道其实网页网游无非就是通过网页和服务器端得各种规则来实现的一种简单的网络游戏。这种游戏因为SNS的风靡而变得火热。但是虽然它是网游。但是本质上还是一个网页,通过超链接,图片,javascript来实现各种页面的跳转和数据的传输。所以说本质上他跟一个传统的网页没有本质上的区别。只是各家的网游有着不同复杂程度的网页而已。
我们这次首先找到一个简单的网页网游进行分析。例如,kaixin001的种菜游戏。这个种菜游戏大家都知道其表示形式是一个Flash,跟网页有着本质的不同。但是其手机版确实是一个非常普通的wap网站通过WML描述语言实现的。我们就从这里进行的入手。
1.登录
WAP网站不仅可以通过手机登陆,通过电脑的WEB浏览器同样能够登录,因为他仍然通过HTTP协议进行数据的交换。当然IE目前不支持这种行为,不过google 的chrome可以支持WAP网站的浏览。我们通过Chrome登录http://wap.kaixin001.com。我们可以看到其登录换面如下。

可是我们如何通过程序登录呢?这里我们需要查看一下这个wap页面的源代码。
通过代码我们发现我们只需要填写相应的表单即可登录网站。这里需要填写的是在<div id="login_area">这个标签中的表单。 表单项有
email(用于确定用户名)
password(密码)
remember(是否自动登录)
from(暂且不知,而且还是个隐藏项,但是没有赋值,我们暂且不理睬)
login(登录按钮值为“ 登 录 ”,注意里边的空格)
表单的action为/home/
这个表单的具体表项我们先记录下来,已备后用。
这里我们还发现了一个网页的特征就是网页使用UTF-8进行字符的编码,这个也是之后我们要注意的事情。
2.登陆后的页面分析
其实登陆后的目的很简单,我们就是为了找到农场的的链接在哪然后开始偷菜。我们知道通过wap去农场的步骤就是一路点击[组件]->[买房子]->[花园菜地]->[可偷的菜地]。也许大家发现直接找到可以偷的菜地这个链接就可以了。其实不然。各种网站都有了防机器人放外挂的方式。一般都是引入了一些系统生成的验证数据。别看wap版本的开心001,它仍然引入了这些机制。我们通过登录后的代码片段可以进行查看。可以看到每个超链接基本上都要发送一个verify变量。你每次刷新一次页面verify变量都会改变。经过试验如果你发送的veryify变量不是它系统生成的导致的结果就是被系统强制注销登录。所以我们需要老老实实的逐一链接的进入需要的网址。
当我们一步步通过连接进入到了[可以偷的菜地]后我们需要看看这个页面都有什么特征了。在这个页面我们发现里边都是好友的名字的链接。只有进入了好友的名字的链接才能够【偷菜】。我们先不进去,我们先来看看我们怎么知道都有哪些好友。好友页面被系统分页了,所以我们需要知道当前是不是好友页面的最后一页。这个特征比较好找到。当只有【下一页】这个链接的时候说明好友页面还没有到最后一页。当【下一页】和【上一页】这两个链接都出现也说明没有到头。只有出现了只有【上一页】这个链接的时候才算是好友页面到头了。还有一个特殊情况,就是你的好友实在是太少,根本没有【上一页】和【下一页】这两个链接,这个也可以算是好友页面到头了。
3.偷菜的链接
下边我们进入好友的名字的那个连接。进入后我们发现我们已经进入了好友的菜地中。里边的网页大致上是这个样子的。
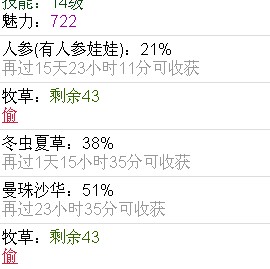
分析下边的代码我们发现,所有可以偷的菜的信息都包含在了一个有【偷】这个链接的<div>标签中。标签中还包括了可偷的物品的名字,还剩多少可以偷。以及【偷】这个链接。在这里我们再次见识到了Veryfiy这个变量,看来验证信息无处不在,大意不得。
二.实现
上边我们已经分析出这个网页网游就是一个WML的页面,使用HTTP协议就可以进行访问。通过对WML页面的解析我们就可以达到我们的目的。HTTP协议的数据交换我们可以使用.NET FRAMEWORK2.0开始提供的System.Net.WebClient这个类。该类已经提供了我们使用HTTP协议访问数据的大部分功能。
首先我们来看看登录是如何使用WebClient登录。下边的代码显示了我们如何通过WebClient发送表单进行网站登录的。一定要记得表单中所有的项目都要填写全(参考登录的表单分析)。还有就是数据应该是用UTF-8进行编码,如果不是的话数据一定会出错的。
登陆后的页面以字符串的形式储存在了responseHtml这个变量中了。我们需要对这个页面进行分析,还记得我们说要找到我们需要的链接么?这里我们通过正则表达式来获所有的超链接,然后过滤出我们需要的链接。获取超链接标签我们不仅需要获取其href属性,我们还要获取他的标签的值。我们通过标签的值来过滤我们需要的内容。获取的超链接我们还需要进一步的处理。网页中的超链接有些是绝对地址有些是相对地址,这里我们需要进行转换。还有就是我写的正则表达式可能提取后的地址信息中带有双引号,我们需要将双引号剔除。在这就是网页中定义了很多类似;  ;&这样的转义字符串,所以我们需要将相应的转义字符串进行替换。这里是个血的教训,我就是没有进行转义字符的替换导致直接被服务器强制注销。
我们通过下边的方法找到并按照如下顺序访问以下超链接[组件]->[买房子]->[花园菜地]->[可偷的菜地]。就可以到达好友的列表了。通过下边的函数我们来过滤出我们的好友的链接。还记得上边的好友列表的特征,因为好友列表中的链接不只一页所以还需要按照上边分析出的特征找出所有的好友。但是为了效率和快速偷取的原则我们应该找到一页的好友就偷一页,然后再找再偷。
通过找到了好友的链接我们就访问进去就可以开始偷菜了。同样的我们需要找到偷菜的链接。回想我们分析的偷菜页面的链接。为了获取更多的信息我们应该不只分析链接而是应该分析包含【偷】链接的整个<div>标签,这样我们才能知道在偷什么。我们同样使用正则表达式来获取我们所需的信息,不过这次我们用两个这则表达式来获取数据。这里我们能够获取到偷的是什么,偷的链接,以及标签的既超链接所显示的字。获取连接时HtmlGetAppleUrl方法中的keyword起找到偷这个关键字的作用。例如 URLHelper.HtmlGetAppleUrl(responseHtml, "偷");
找到【偷】的链接我们就可以大偷特偷了。下边的代码展示了如何进行执行偷这个动作。DoFilter()这个方法是我自己为了过滤掉不想偷的菜写的过滤函数。比如像牧草,白菜这样的不值钱的东西就不应该去偷,浪费有限的偷东西次数。HumanSim()方法用于模拟人的反映时间,因为人看网页时有速度的,有时候反应快有时候反映慢我们应该模拟出这个过程进行随机的延时。不然有可能被服务器封号。虽然随机延时很简单,但是应该是个有效的方法。我们可以根据每次访偷取链接后得到的结果页面来分析是否偷取成功。这里我直接查找字符串中是否包含成功这两个子,如果包含的画就算是偷取成功了。
三.写在最后
通过上边的分析大家应该对这种网页网游的辅助工具编写找到了一定的方法了。也许现在SNS网站上大部分游戏都是FLASH界面的,但是没有关系。虽然他的数据时FLASH界面但是我通过WinDump查看其数据包的发送发现其大部分仍然使用了HTTP方式进行数据交换,只不过链接被FLASH界面所掩盖了,但原理仍然不变。所以仍然可以采取HTTP方式进行辅助程序的开发。















 1575
1575

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









