







分析器是lucene中非常重要的一个组件,许多包都是分析器的子包,这是因为分析器需要支持很多不同的语言。
lucene中的分析器
分析器可能会做的事情有:将文本拆分为单词,去除标点,将字母变为小写,去除停用词,词干还原,词形归并,敏感词过滤等等。lucene中默认自带的分析器有4个:WhitespaceAnalyzer,SimpleAnalyzer,StopAnalyzer, StandardAnalyzer,分别用来过滤空白字符,过滤空白符并自动变小写,去掉停用词,标准化分词。其中,最常用的是StandardAnalyzer。分析器之所以能做这么多事,与之简洁而强大的类设计是分不开的。
事实上,这部分就使用了一个装饰器模式,但是由此可以做许多事情,因为filter可以不停的添加新功能。下面是类结构图。
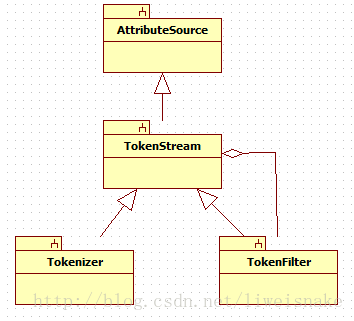
Analyzer中最重要的就是tokenStream方法,它得到一个TokenStream对象。这个方法最开始从reuseStrategy中取得一个TokenStreamComponent,reuseStrategy是重用的策略,默认有两个实现GLOBAL_REUSE_STRATEGY和PER_FIELD_REUSE_STRATEGY,前者让所有field共用一个TokenStreamComponent,后者每个field一个TokenStreamComponent,而实际存储这些Component的地方是Analyzer中的storedValue。接下来初始化reader并设置到component。最后从component得到TokenStream
public final TokenStream tokenStream(final String fieldName,
final Reader reader) throws IOException {
TokenStreamComponents components = reuseStrategy.getReusableComponents(this, fieldName);
final Reader r = initReader(fieldName, reader);
if (components == null) {
components = createComponents(fieldName, r);
reuseStrategy.setReusableComponents(this, fieldName, components);
} else {
components.setReader(r);
}
return components.getTokenStream();
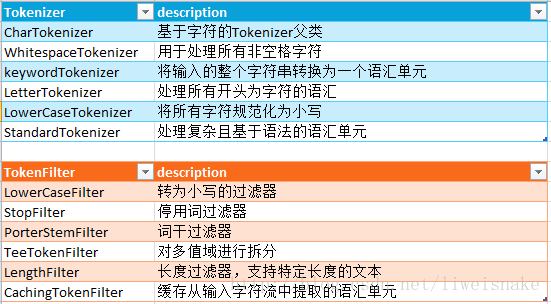
}下面是lucene中一些Tokenizer和TokenFilter的列表。无论从名字还是实现都相对简单,这里就不过多分析了。
分词
接下来来看看分析器的一个比较重要的功能,分词。所谓分词,就是为了便于倒排索引的查询而将一个句子切分为一个一个的term,切分的最好标准就是每个词尽量符合它在句子中语义,但实际上往往是很难达到的。大家可以试想一下,如果是一句英文的句子,那么一种简单的分词方式可以用split(" "),这样英文中的每个单词就是一个term。但是如果是一句中文,我们能够每个字一个term吗?如果这样,那搜素出来的肯定牛头不对马嘴。因为汉语中的单词通常是词组,词组才是组成确定语义的单位。因而如何分词就是需要注意的问题了。
关于中文分词,目前大概有这样几种方法:
1. 基于字符串匹配的分词方法。比较著名的几个开源项目有IkAnalyzer和paoding。
这种分词方法简单来讲就是用待分词的句子与词典中的词进行匹配,找出最合适的匹配。这种方式实现的分词,优点是快速;但制约因素是词典本身要好,而且不在词典中的词就无法匹配,因为是纯粹匹配,碰上歧义时分词器本身也不认识到底应该识别哪一个,因而消除歧义的能力较差。比如知乎上的这样一段测试文本,中间有很多歧义的部分:“工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作”。这样的识别对这类分词器而言是比较大的挑战。
分词按照方向可以分为正向或者逆向,按照匹配的贪婪程度,可以分为最大匹配,最少次数划分(有分词理论),最细粒度匹配。之所以会有这些划分,是因为基于字符串匹配的算法通常能够解决一类问题,但是另一类会差一些。而按照这样的划分,能够给予分词一定的启发式规则。
以上面的句子为例,如果随意划分,那么开头就会是"工信/处女/干事...",显然是有问题的。
按照最大匹配划分,就是"工信处/女/干事",但是最大匹配划分也有问题,matrix67的文中有个例子"北京大学生前来应聘"会被划分为"北京大学/生前/来/应聘",这也是有问题的。
所以有逆向的匹配,比如上面这句,就可以匹配成"北京/大学生/前来/应聘"。
另一种划分方式,就是最细粒度划分,还是以最初的歧义句子为例,它可以被最细粒度划分为"工信/处女/干事/每月/月经/经过...",可以看到它并没有消除歧义,只是增加了搜索到这个句子的词。
以上这些方式实际上都是可以举出反例的,其实就是让中国人来听,汉语也只有76%的准确度。
讲讲几个开源项目IkAnalyzer, paoding和mmseg。
IkAnalyzer是用的正向迭代最细粒度切分算法以及一个智能分词法,目前IkAnalyzer实际上是比较活跃的,作者也经常更新。
paoding实际上在2010年更新了一版支持lucene3.0之后就销声匿迹了。
mmseg的算法也挺有意思,它有下面4条启发式的消除歧义规则:
1)备选词组合的长度之和最大。
2)备选词组合的平均词长最大;
3)备选词组合的词长变化最小;
4)备选词组合中,单字词的出现频率统计值最高。
最开始它从左到右扫描一遍,识别出3个词的不同组合,然后用上面4条规则匹配出最好的一个词组,然后再次用这4条规则匹配剩下的词,这样消歧能力有明显的提高。参考中有篇文章介绍mmseg,不过居然是96年发表的
2. 基于统计和机器学习的分词。比如CRF,HMM(隐式马尔科夫模型),MEMM(最大熵隐马模型)。
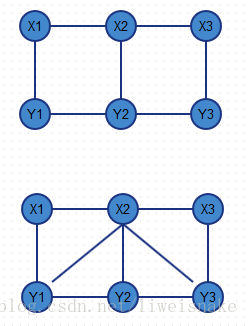
这种分词方式在最初需要提供一个训练集去喂,这个训练集就是已经标注好的分词词组,然后在分词阶段通过构建模型来计算各种可能分法的概率,通过概率来最终判断。实际上,这是目前公认的比较准确的方式。CRF即条件随机场(Conditional Random Field),在《数学之美》中已经对其描述过。可以想象,这个训练集对于分词的准确性也是非常重要的。CRF比隐马模型好在,隐马模型由于简化,每个观察值只考虑到了当前状态,而条件随机场则是考虑到了前后的状态。通俗的讲,隐马模型对于现在的输出也只考虑现在的条件;而CRF对于现在的输出需要考虑过去,现在和未来的条件。如图,上面是隐马模型,对于观测值x2,只取决于产生的状态y2;下图则是条件随机场,x2不仅取决于y2,还取决于y1以及y3.
CRF最初是被用来对一个句子做句法成分分析的,比如:我爱地球,通过条件随机场能判断出句子成分是:主语/谓语/宾语。而这个判断的过程是一个分类的过程。如果我们将这个分类换成一个4标记B, S, M, E的方式
- 词首,常用B表示
- 词中,常用M表示
- 词尾,常用E表示
- 单子词,常用S表示
参考:matrix67写的关于CRF的博文 http://www.matrix67.com/blog/archives/4212
另一个中文分词项目Ansj http://blog.csdn.net/blogdevteam/article/details/8148451
IkAnalyzer作者博客及项目地址 http://linliangyi2007.iteye.com/ https://code.google.com/p/ik-analyzer/
CRF的更多介绍 http://blog.csdn.net/ifengle/article/details/3849852
standford的CRF实现 http://nlp.stanford.edu/software/segmenter.shtml
CRF++实现 http://www.coreseek.cn/opensource/
mmseg http://technology.chtsai.org/mmseg/
中文分词方案(知乎) http://www.zhihu.com/question/19578687
CRF详细介绍 http://wenku.baidu.com/view/f32a35d2240c844769eaee55.html
中文分词之trie树 http://blog.csdn.net/wzb56_earl/article/details/7902669
数学之美--谈谈中文分词
中文分词与马尔科夫模型之二(隐马尔科夫模型与维特比) http://blog.sina.com.cn/s/blog_68ffc7a40100uebv.html
维特比算法 http://zh.wikipedia.org/wiki/%E7%BB%B4%E7%89%B9%E6%AF%94%E7%AE%97%E6%B3%95















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









