







 Disruptor作为性能优化工具,以其独特的RingBuffer和无锁设计著称。本文详细解读了Disruptor的基本概念,包括RingBuffer、EventProcessor、EventHandler、EventTranslator和SequenceBarrier,以及不同类型的WaitStrategy。生产者通过publish方法发布消息,消费者通过EventProcessor框架处理事件。文章还探讨了如何正确使用Disruptor以发挥其最大效能,并分析了Disruptor的高性能原因和多生产者写入策略。
Disruptor作为性能优化工具,以其独特的RingBuffer和无锁设计著称。本文详细解读了Disruptor的基本概念,包括RingBuffer、EventProcessor、EventHandler、EventTranslator和SequenceBarrier,以及不同类型的WaitStrategy。生产者通过publish方法发布消息,消费者通过EventProcessor框架处理事件。文章还探讨了如何正确使用Disruptor以发挥其最大效能,并分析了Disruptor的高性能原因和多生产者写入策略。
disruptor经过几年的发展,似乎已经成为性能优化的大杀器,几乎每个想优化性能的项目宣称自己用上了disruptor,性能都会呈现质的跃进。毕竟,最好的例子就是LMAX自己的架构设计,支撑了600w/s的吞吐。
本文试图从代码层面将关键问题做些解答。
基本概念
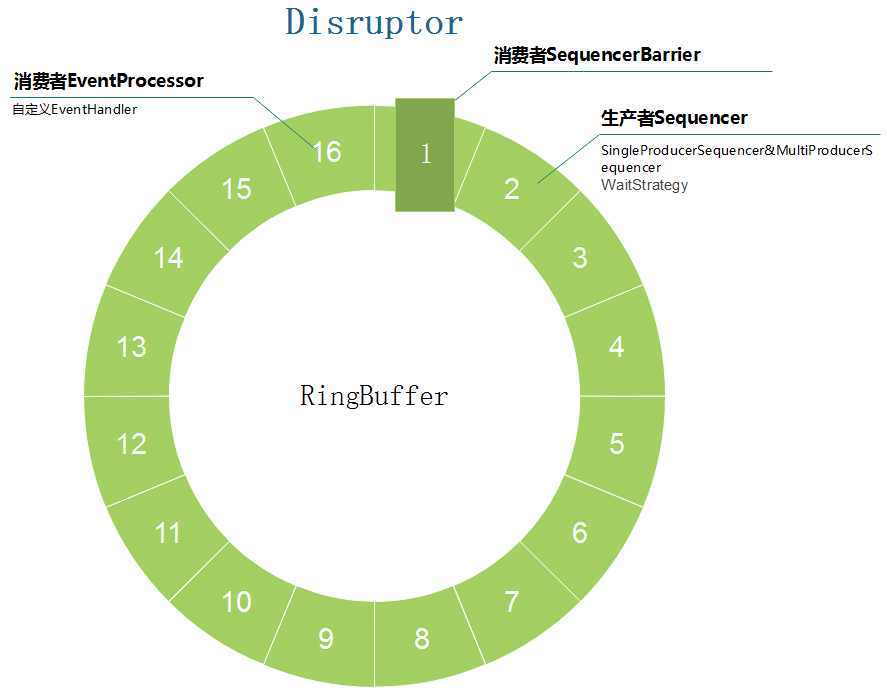
Disruptor: 实际上就是整个基于ringBuffer实现的生产者消费者模式的容器。
RingBuffer: 著名的环形队列,可以类比为BlockingQueue之类的队列,ringBuffer的使用,使得内存被循环使用,减少了某些场景的内存分配回收扩容等耗时操作。
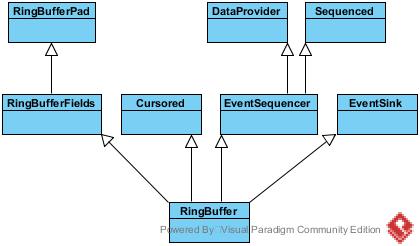
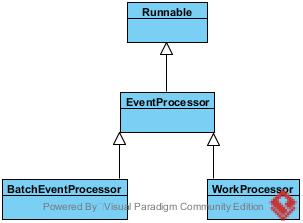
EventProcessor: 事件处理器,实际上可以理解为消费者模型的框架,实现了线程Runnable的run方法,将循环判断等操作封在了里面。
EventHandler: 事件处置器,与前面处理器的不同是,事件处置器不负责框架内的行为,仅仅是EventProcessor作为消费者框架对外预留的扩展点罢了。
Sequencer: 作为RingBuffer生产者的父接口,其直接实现有SingleProducerSequencer和MultiProducerSequencer。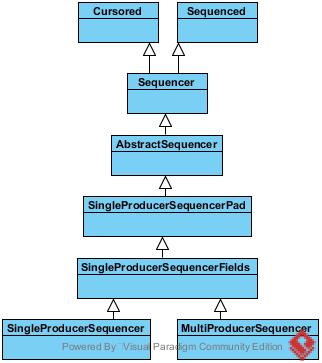
EventTranslator: 事件转换器。实际上就是新事件向旧事件覆盖的接口定义。
SequenceBarrier: 消费者路障。规定了消费者如何向下走。都说disruptor无锁,事实上,该路障算是变向的锁。
WaitStrategy: 当生产者生产得太快而消费者消费得太慢时的等待策略。
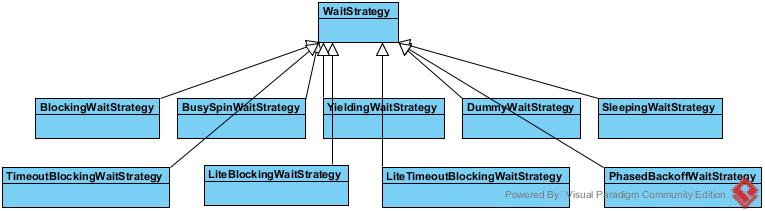
把上面几个关键概念画个图,大概长这样:
所以接下来主要也就从生产者,消费者以及ringBuffer3个维度去看disruptor是如何玩的。
生产者
生产者发布消息的过程从disruptor的publish方法为入口,实际调用了ringBuffer的publish方法。publish方法主要做了几件事,一是先确保能拿到后面的n个sequence;二是使用translator来填充新数据到相应的位置;三是真正的声明这些位置已经发布完成。
public void publishEvent(EventTranslator<E> translator)
{
final long sequence = sequencer.next();
translateAndPublish(translator, sequence);
}
public void publishEvents(EventTranslator<E>[] translators, int batchStartsAt, int batchSize)
{
checkBounds(translators, batchStartsAt, batchSize);
final long finalSequence = sequencer.next(batchSize);
translateAndPublishBatch(translators, batchStartsAt, batchSize, finalSequence);
} 获取生产者下一个sequence的方法,细节已经注释,实际上最终目的就是确保生产者和消费者互相不越界。
public long next(int n)
{
if (n < 1)
{
throw new IllegalArgumentException("n must be > 0");
}
//该 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3009
3009

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









