






1.名称粉碎机制的由来
在C语言的语法中,函数名称是一个函数的唯一标识,如果一个文件内含有两个名称相同的函数,编译器就会报“函数已有主体”的错误;在多个文件链接时,如果发现有两个名称相同的函数,链接器就会报“符号重定义”的错误。
具有多态特性的C++支持函数的重载,函数不再以函数名称作为唯一标识。只要满足构成重载的条件,两个(或多个)功能不同的函数可以有相同的函数名称。这样一来,函数的调用者会获得多态性带来的极大方便(虽然函数的编写者的工作量没有改变,所有的同名函数仍需要一个一个地去编写)。构成函数重载的条件是:
1.作用域相同
2.函数名称相同
3.参数不同(类型,个数,顺序)
(另外:返回值类型、调用约定类型并不作为参考)
为了支持函数重载这一新特性,编译器的开发者们大多选择使用名称粉碎机制,即把函数的原有名称和参数类型、个数、顺序等信息融合成一个新的函数名称。这个新的名称就是此函数的唯一标识。有了它,之后的工作就可以继续沿用C语言的套路(在编译、连接过程中,若发现新名称存在重复现象,仍会发出“函数已有主体”或“符号重定义”信息)。
值得一提的是,C++标准中只是说明了函数重载的定义,但并没有提出“名称粉碎机制”这种概念。由于名称粉碎机制的直观、高效、易于兼容以前的C版本的特点,所以各编译器作者不约而同地选择用名称粉碎机制来实现函数重载。虽然各编译器的思路是一致的,但是由于没有统一的标准,所以各编译器的名称粉碎结果也自然是五花八门。下面我们来观察微软VC编译器的名称粉碎细节。
2.微软VC编译器的名称粉碎细节
在一般情况下,我们是看不到名称粉碎机制的细节的(因为我们没有必要知道编译器内部的操作)。为了看到这些细节,我们必须进入编译生成的obj文件中探索。例如这次定义两个名为test_add的函数,分别用于计算整形数据相加之和和双精度浮点型数据相加之和:
#include "stdafx.h"
int test_add(int n1, int n2)
{
return n1 + n2;
}
double test_add(double d1, double d2)
{
return d1 + d2;
}//文件test.h
#pragma once
int test_add(int n1, int n2);
double test_add(double d1, double d2);//文件main.cpp
#include "stdafx.h"
#include "test.h"
int _tmain(int argc, _TCHAR* argv[])
{
int nNum = test_add(8, 9);
double dNum = test_add(8.8, 9.9);
return 0;
}
#include "stdafx.h"
/*
int test_add(int n1, int n2)
{
return n1 + n2;
}
double test_add(double d1, double d2)
{
return d1 + d2;
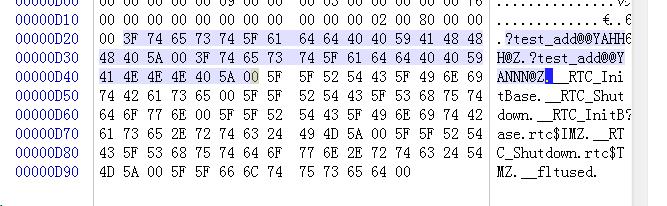
}*/1>main.obj : error LNK2019: 无法解析的外部符号 "int __cdecl test_add(int,int)" (?test_add@@YAHHH@Z),该符号在函数 _wmain 中被引用
1>main.obj : error LNK2019: 无法解析的外部符号 "double __cdecl test_add(double,double)" (?test_add@@YANNN@Z),该符号在函数 _wmain 中被引用错误信息向我们揭示了:两个add_test函数因为参数的不同,被名称粉碎机制赋予了新的函数名称,分别是?test_add@@YAHHH@Z和?test_add@@YANNN@Z。通过这个人为制造错误的方法,我们可以继续测试不同类型的参数会对名称粉碎造成什么样的影响。在微软的名称粉碎机制中,除了函数的参数类型之外,函数的调用约定、返回值类型和作用域都被整合到了粉碎后的新名称之中。
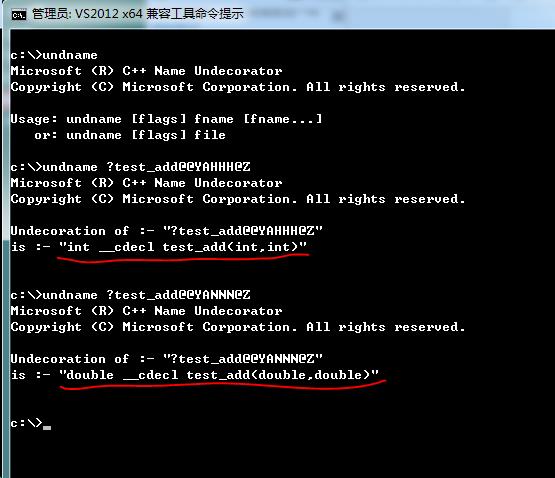
此外,微软还为我们提供了一个“反名称粉碎”工具undname,用于快速地把粉碎后的函数名称还原成本来的样子。打开VS2012工具命令提示(位于 开始菜单->Microsoft Visual Studio 2012->Visual Studio Tools),输入undname即可打开这个工具。我们可以利用它来直接翻译粉碎后的名称,如图所示,函数的返回值类型,调用约定,参数的类型、个数、顺序都被翻译出来了。
3.文件粉碎机制的逆向应用
举个具体例子,一个正在合作同一个项目的程序员,在完成了自己负责的那一部分功能后,因为想保护自己的源码,所以只共享了编译后生成的obj文件和一份配套的文档,文档里说明了怎么去调用此obj里的函数。
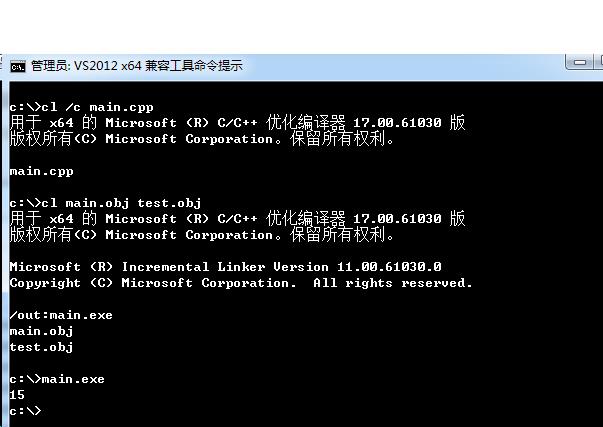
现在有了undname这个工具,配合之前对obj文件的文本搜索经验,我们就可以尝试探索并调用obj文件里的所有可用函数,而不是被局限于文档的说明。
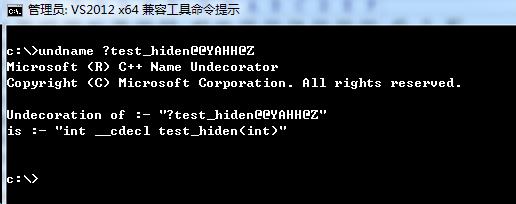
假设一个程序员写了一个cpp文件,并且只在文档里说明了test_open函数,却隐藏了test_hiden函数的说明:
注:代码中英语“隐藏”拼写错误,应该是hidden,而非hiden。
//文件:test.cpp (作者:编程合作者)
//在文档内提供次函数说明
int test_open(int n)
{
return n + 10;
}
//文档里没有提到此函数
int test_hiden(int n)
{
return n * 10;
}//文件:main.cpp (作者:主函数编写者)
#include <stdio.h>
int test_open(int n); //obj文件内的函数的声明;也可以是包含一个头文件的形式。
int main(int argc, char* argv[])
{
int nNum = test_open(5);
printf("%d", nNum);
return 0;
}

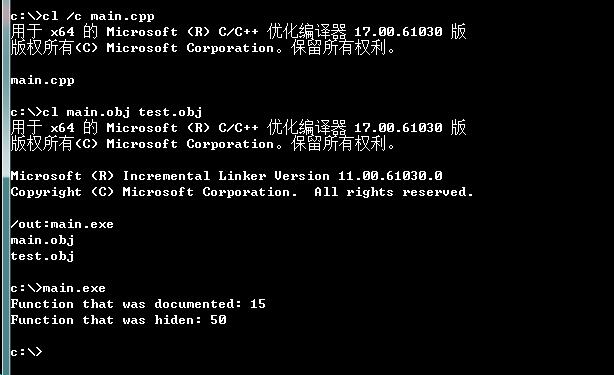
#include <stdio.h>
int test_open(int n);
int test_hiden(int nSecret);
int main(int argc, char* argv[])
{
int nNum = test_open(5);
printf("Function that was documented: %d\r\n", nNum);
nNum = test_hiden(5);
printf("Function that was hiden: %d\r\n", nNum);
return 0;
}
对于C语法下的带有static修饰符的静态函数,这种方法还是无能为力的,因为static函数的信息不会出现在obj文件中。
对于c++语法下类(Class)里面的private/protected函数(包括带有static修饰符的静态函数),虽然我们能通过obj文件和undname工具还原它们的函数信息,但由于它们的private/protected属性,还是无法从外部对它们进行调用。如果函数是public属性,那么无论他是普通函数,还是static修饰的静态函数,都可以用本文的方法还原函数信息然后调用。















 3119
3119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









