







- 单机部署安装
- 服务端下载,安装,启动
- 去官网下载最新的版本:http://redis.io/download ,这里用的是3.0.2
- 解压后,进入解压好的文件夹
- redis的安装非常简单,因为已经有现成的Makefile文件,所以直接先make,然后make install就可以了
- 安装的位置在/usr/local/bin ,有:
- redis-benchmark:性能测试工具,测试Redis在你的系统及配置下的读写性能
- redis-check-aof:用于修复出问题的AOF文件
- redis-check-dump:用于修复出问题的dump.rdb文件
- redis-cli:Redis命令行操作工具
- redis-sentinel:Redis集群的管理工具
- redis-server:Redis服务器启动程序
- 启动Redis的时候,只有一个参数,就是指定配置文件redis.conf的路径。redis.conf在解压的文件夹里面有,复制一个出来,按需修改即可,也可--port来指定端口
- 连接Redis并操作,使用redis-cli,如果有多个实例,可以redis-cli -h 服务器ip -p 端口
- 关闭Redis,redis-cli shutdown,如果有多个实例,可以指定端口来关闭:redis-cli -p 6379 shutdown
- 服务端修改Redis配置
- Redis基本配置
- 服务端修改Redis配置
bind 127.0.0.1 #如果想要被远程访问注释掉bind配置或者bind外网ip即可
protected-mode yes # 是否开启保护模式 默认:yes,受bind和requirepass配置影响
port 6379# redis服务端口 默认:6379
tcp-keepalive 0 #对访问客户端的一种心跳检测默认:0(不检测),建议设置成60,单位秒
maxclients 10000 # 客户端最大连接数
loglevel notice # 日志级别配置 notice,debug,verbose,notice ,warning
logfile "" # 日志文件输出路径配置
databases 16 # 数据库数量配置 默认:16
requirepass 123456 # 连接密码配置 默认无密码
-
-
-
- 持久化配置
- RDB持久化配置
- 持久化配置
-
-
Redis的RDB(Remote Dictionary Base)持久化机制是通过将Redis数据库的某个时间点的状态以二进制格式保存到磁盘上的方式来实现持久化,当Redis服务器需要恢复数据时,可以通过加载RDB文件来恢复数据;相关配置如下:
# 持久化数据存储在本地的文件名称 默认:dump.rdb
dbfilename dump.rdb
# 持久化数据存储在本地的路径,默认:./(当前工作目录)
dir /data
save 300 10 # 表示每300秒内有至少10个写操作就保存一次RDB文件
# 当RDB持久化时出现错误无法继续时,是否阻塞客户端变更操作,错误可能因为磁盘已满/磁盘故障/OS级别异常等 默认:yes
stop-writes-on-bgsave-error yes
# 是否启用RDB文件压缩,默认: yes,压缩往往意味着额外的cpu消耗,同时也意味这较小的文件尺寸以及较短的网络传输时间
rdbcompression yes
-
-
-
-
- AOF持久化配置
-
-
-
可以简单的认为 AOF 就是日志文件,优点可以保持更高的数据完整性,缺点AOF文件比RDB文件大,且恢复速度慢。
# 是否开启AOP 默认:no
appendonly yes
# 指定AOF文件名称
appendfilename appendonly.aof
# 用于设置AOF文件的同步策略 默认:everysec
## 可以选择"always"、"everysec"或"no"。always表示每次写入都同步,everysec表示每秒同步一次,no表示由操作系统决定何时同步
appendfsync everysec
# 用于设置自动AOF重写的阈值。当AOF文件的扩展比例超过该值时,Redis会自动执行重写操作。默认值为100,表示当AOF文件的大小是上一次重写后大小的一倍时触发重写。
auto-aof-rewrite-percentage 100
# 用于设置自动AOF重写的最小大小。只有在AOF文件的大小大于该值时,才会执行重写操作。默认值为64MB,建议512mb
auto-aof-rewrite-min-size 64mb
# 用于设置在执行AOF文件重写时是否禁用同步。如果设置为yes,则在进行重写时不会进行同步操作,默认:no
no-appendfsync-on-rewrite no
# 用于设置在加载AOF文件时是否允许Redis忽略出现错误的命令。如果设置为"yes",则忽略错误;如果设置为"no",则不允许加载出现错误的AOF文件。默认:yes
aof-load-truncated yes
# 用于设置AOF文件的开头是否包含RDB格式的部分。如果设置为"yes",则在AOF文件的开头会先保存一份RDB格式的数据,这有助于加速数据加载。默认:no
aof-use-rdb-preamble no
-
-
-
- Redis key过期监听配置
-
-
# key过期监听 默认:""(关闭),将notify-keyspace-events设置为Ex代表开启
notify-keyspace-events Ex
-
-
-
- Redis内存淘汰策略
-
-
# 将redis存储内存设置100mb的界限,当超过这个数值开始走淘汰策略
maxmemory 100mb
# 配置策略 默认:noeviction
maxmemory-policy allkeys-lru
内存淘汰算法
noeviction:当内存使用超过配置的时候会返回错误,不会驱逐任何键
allkeys-lru:加入键的时候,如果过限,首先通过LRU算法驱逐最久没有使用的键
volatile-lru:加入键的时候如果过限,先从设置过期时间的键集合中驱逐最久没有使用的键
allkeys-random:加入键的时候如果过限,从所有key随机删除
volatile-random:加入键的时候如果过限,从过期键的集合中随机驱逐
volatile-ttl:从配置了过期时间的键中驱逐马上就要过期的键
volatile-lfu:从所有配置了过期时间的键中驱逐使用频率最少的键
allkeys-lfu:从所有键中驱逐使用频率最少的键
-
-
- 客户端查看工具安装
-
直接百度搜索“RedisDesktopManager”进行下载安装即可,该工具是Windows的客户端查看工具,具体效果如下:

-
- Redis主从复制
- 整体架构
- Redis主从复制
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点
(master/leader),后者称为从节点(slave/follower);数据的复制是单向的,只能由主节点到从节点。Master以写为主,Slave 以读为主。默认情况下,每台Redis服务器都是主节点;且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。
主从复制的作用主要包括:
1、数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
2、故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
3、负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
4、高可用基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
一般来说,要将Redis运用于工程项目中,只使用一台Redis是万万不能的,原因如下:
1、从结构上,单个Redis服务器会发生单点故障,并且一台服务器需要处理所有的请求负载,压力较大;
2、从容量上,单个Redis服务器内存容量有限,就算一台Redis服务器内存容量为256G,也不能将所有内存用作Redis存储内存,一般来说,单台Redis最大使用内存不应该超过20G。电商网站上的商品,一般都是一次上传,无数次浏览的,说专业点也就是"多读少写"。
对于这种场景,我们可以使如下这种架构

-
-
- 主从部署安装配置
-
-
- Java实操Reids中间件
- SpringBoot整合
- 第一步:导入依赖
- SpringBoot整合
- Java实操Reids中间件
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
-
-
-
- 第二步:Yaml配置Redis连接
-
-

-
-
-
- 第三步:配置Redis序列化方式
-
-
为什么要序列化呢?
举个例子,比如说我们经常会将POJO 对象存储到 Redis 中,一般情况下会使用 JSON 方式序列化成字符串,存储到 Redis 中
具体配置方法如下:
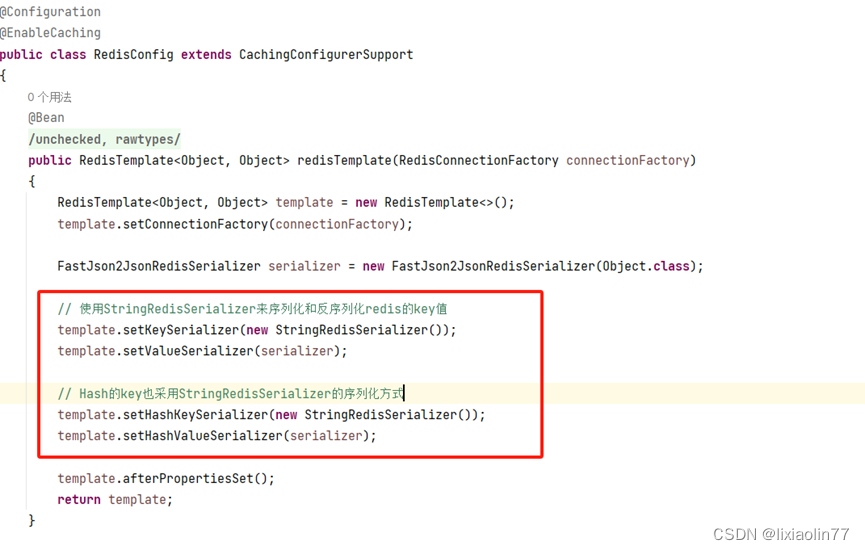
序列化方式常用的有如下几种:
JDK 序列化方式 (默认)
String 序列化方式J
SON 序列化方式
XML 序列化方式

绝大多数情况下,不推荐使用 JdkSerializationRedisSerializer 进行序列化。主要是不方便人工排查数据;其中StringRedisSerializer和FastJson2JsonRedisSerializer用的最多。
-
-
-
- 第四步:封装Redis工具类
-
-
在SpringBoot中一般使用RedisTemplate提供的方法来操作Redis。不过我们还需要进一步封装。
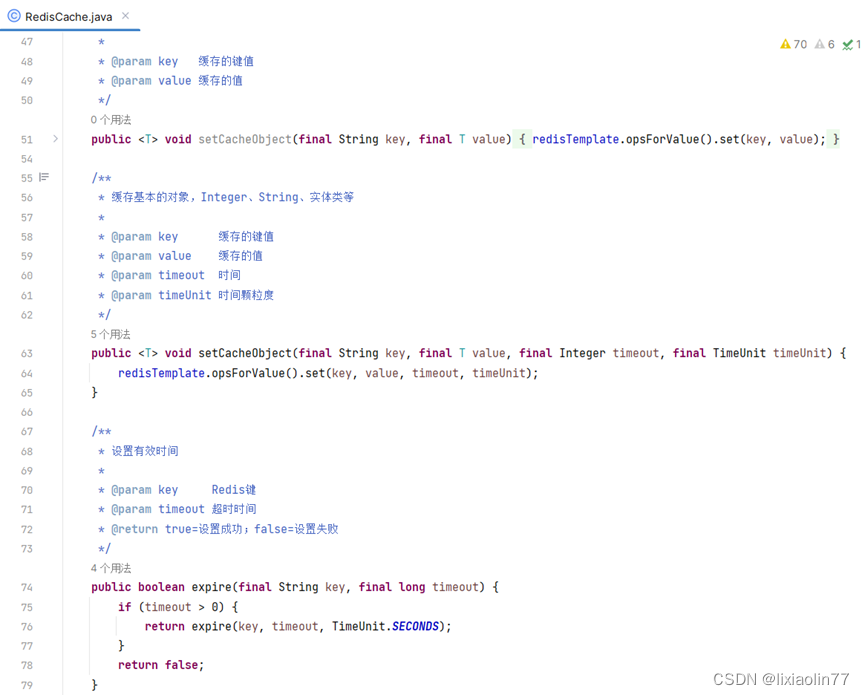
-
-
-
- 第五步:使用缓存
-
-

-
-
- RedisTemplate的API详解
- 获取操作Redis的对象
- RedisTemplate的API详解
-
通过分析RedisTemplate源码发现,已经封装了所有Redis数据类型的操作。
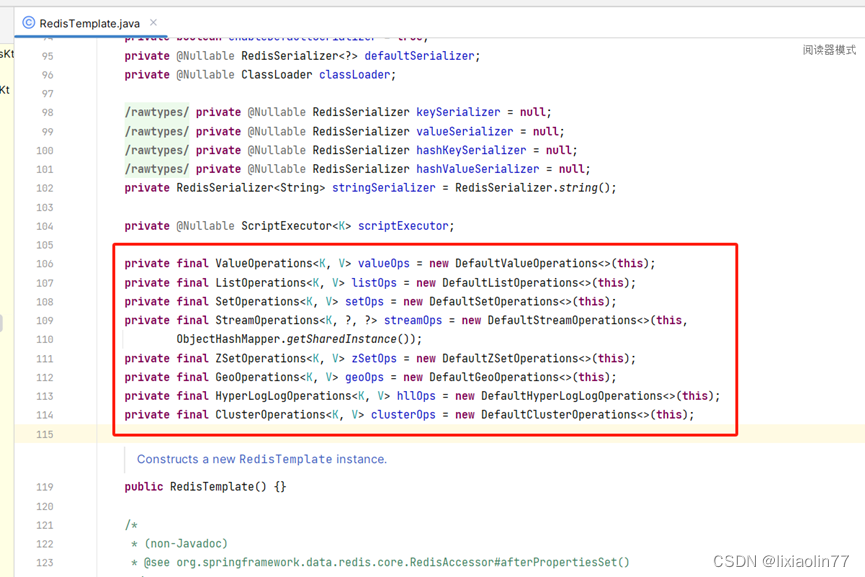
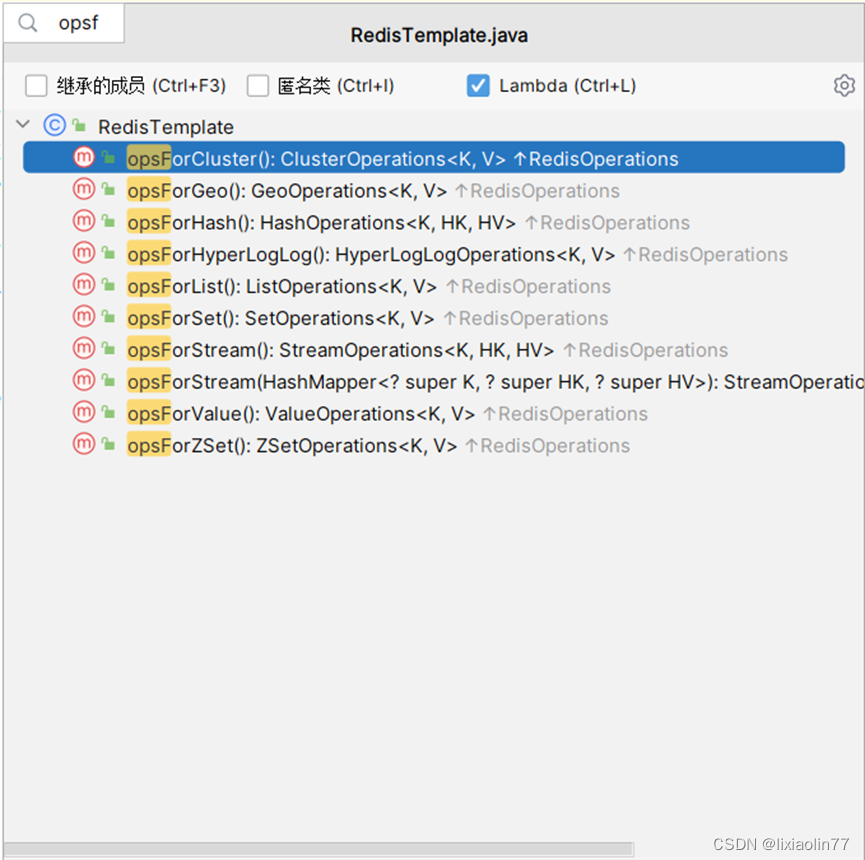
我们只需要调用opsFor***()方法就可以获得相应的实例对象。
-
-
-
- 删除Key
-
-


-
-
-
- 指定缓存失效时间
-
-

-
-
-
- 根据key 获取过期时间
-
-

-
-
-
- 判断key是否存在
-
-

-
-
-
- String类型相关操作
-
-
- 获取缓存

- 添加缓存

- 添加缓存并设置过期时间

- 递增操作

- 递减操作

-
-
-
- Hash类型相关操作
-
-
- 设置一组Map的键值对
/**
* HashGet
* @param key 键 不能为null
* @param item 项 不能为null
* @return 值
*/
public Object hget(String key,String item){
return redisTemplate.opsForHash().get(key, item);
}
- 获取指定Map的所有键值
/**
* 获取hashKey对应的所有键值
* @param key 键
* @return 对应的多个键值
*/
public Map<Object,Object> hmget(String key){
return redisTemplate.opsForHash().entries(key);
}
- 添加一个Map类型值
/**
* HashSet
* @param key 键
* @param map 对应多个键值
* @return true 成功 false 失败
*/
public boolean hmset(String key, Map<String,Object> map){
try {
redisTemplate.opsForHash().putAll(key, map);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
- 添加一个Map类型值并设置过期时间
/**
* HashSet 并设置时间
* @param key 键
* @param map 对应多个键值
* @param time 时间(秒)
* @return true成功 false失败
*/
public boolean hmset(String key, Map<String,Object> map, long time){
try {
redisTemplate.opsForHash().putAll(key, map);
if(time>0){
expire(key, time);
}
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
- 向一张hash表中放入数据,如果不存在将创建
/**
* 向一张hash表中放入数据,如果不存在将创建
* @param key 键
* @param item 项
* @param value 值
* @return true 成功 false失败
*/
public boolean hset(String key,String item,Object value) {
try {
redisTemplate.opsForHash().put(key, item, value);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
- 向一张hash表中放入数据,如果不存在将创建并设置过期时间
/**
* 向一张hash表中放入数据,如果不存在将创建
* @param key 键
* @param item 项
* @param value 值
* @param time 时间(秒) 注意:如果已存在的hash表有时间,这里将会替换原有的时间
* @return true 成功 false失败
*/
public boolean hset(String key,String item,Object value,long time) {
try {
redisTemplate.opsForHash().put(key, item, value);
if(time>0){
expire(key, time);
}
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
- 删除hash表中的值
/**
* 删除hash表中的值
* @param key 键 不能为null
* @param item 项 可以使多个 不能为null
*/
public void hdel(String key, Object... item){
redisTemplate.opsForHash().delete(key,item);
}
- 判断hash表中是否有该项的值
/**
* 判断hash表中是否有该项的值
* @param key 键 不能为null
* @param item 项 不能为null
* @return true 存在 false不存在
*/
public boolean hHasKey(String key, String item){
return redisTemplate.opsForHash().hasKey(key, item);
}
- 递增,如果不存在,就会创建一个 并把新增后的值返回
/**
* hash递增 如果不存在,就会创建一个 并把新增后的值返回
* @param key 键
* @param item 项
* @param by 要增加几(大于0)
* @return
*/
public double hincr(String key, String item,double by){
return redisTemplate.opsForHash().increment(key, item, by);
}
- 递减
/**
* hash递减
* @param key 键
* @param item 项
* @param by 要减少记(小于0)
* @return
*/
public double hdecr(String key, String item,double by){
return redisTemplate.opsForHash().increment(key, item,-by);
}
-
-
- Redis 实现文章的点赞、点赞排行榜
-
实现方案:采用Redis ZSet集合实现Redis点赞排行榜功能,因为ZSet集合是 有序且不重复的,元素具有唯一性,且有序,所以非常适合做点赞排行榜功能。
具体代码实现如下:
下面代码是点赞功能的实现:

查询点赞排行Top5的用户

如果您觉得这篇文章对你有帮助,请关注点赞,作者会更有动力!
持续更新中.........















 1255
1255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









