







pip
如果你是 Python3.+ 的版本,用下面这种方式:
pip3 install numpy
Numpy和List区别
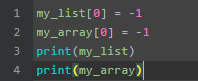
numpy储存数据的格式:np.array([1,2,3])
list的格式:[1,2,3]
甚至对内部的一个值进行修改也是同样的逻辑.
numpy的优势
Numpy的核心优势:运算快。用专业的语言描述的话,Numpy 喜欢用电脑内存中连续的一块物理地址存储数据,因为都是连号的嘛,找到前后的号,不用跑很远, 非常迅速。而 Python 的 List 并不是连续存储的,它的数据是分散在不同的物理空间,在批量计算的时候,连号的肯定比不连号的算起来更快。因为找他们的时间更少了。
而且 Numpy Array 存储的数据格式也有限制,尽量都是同一种数据格式,这样也有利于批量的数据计算。 所以只要是处理大规模数据的批量计算,Numpy 肯定会比 Python 的原生 List 要快。
维度很重要
创建数据
一维数据:可以代表一个车辆百公里加速的列表

二维数据:可以代表多个车辆百公里加速的列表

既然能创建二维数据,当然更高维度也不在话下啦,比如三维,可以表示,我在不同场地,多次测试不同测量,比二维数据多出来的一个维度就是不同场地这个维度了。


np.array():创建数据
array.ndim:现实数据的维度
添加数据

原本的维数不会发生改变。

原本的一维变成2维。
加维度的方法
np.expand_dims(test1,0)
test2[np.newaxis,:]
合并数据
np.concatenate[kɑnˈkæt(ə)ˌneɪt]([])将两个数据合并
有同学肯定会问了,你既然能在第一个维度上叠加,那你能不能在第二个维度上叠加呢?当然可以,只需要巧妙给 np.concatenate 一个参数就好。

只要维度能够对齐,你可以在任意维度上进行合并操作。注意,有些数据维度是对不齐的,这样没办法合并。比如:

还有两个比较好用的在二维数据上可以方便调用的功能,分别是 np.vstack(), np.hstack().

观察形态

array.size:总的数据个数

更进一步,我不光想知道总数据,我还想知道当前有多少次测试(第一个维度,行),和在多少辆车上测试了(第二个维度,列)。怎么办?
array.shape:看每个维度下的数据数量

数据选择不迷茫
单个选取

当然还有种方法,可以一次性选择多个,但实际上选择的逻辑还是一个个拎出来的逻辑。就像一个个从抽屉里拿出来的意思。

二维或者多维数据也可以用上面的方法来选择数据,一个个拎出来。

切片划分
上面太累了太难记了
单维数据

多维数据

条件筛选(np.where())
就是按照一定的筛选逻辑进行过滤,留下那些在数值上符合条件的数据。

底层的筛选逻辑是:既然 condition 是一种 True/False, 那么只要我们得到一个 True/False 数据,我都能做筛选。

除了这种直接用[]的形式,在 Numpy 中,还有一个专用的函数来做数据赛选。这种筛选更强大,它还能做筛选结果的替换工作。 它可已将满足条件的位置变成你设定的数字。下面满足条件的,都改成 -1,不满足的,都还是 a 里面的数字。

或者,不仅是满足条件的 condition,不满足条件的,也能变成你期望的数字。

还能让它和另外一个数据做条件上的整合

基础运算
加减乘除
列表需要循环
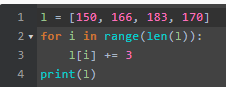
或者需要一个函数即可

但是numpy

Numpy 是可以批量进行计算的,只需要简单的 +-*/,就能进行全元素的运算,也就是向量化运算。

np.dot()
在科学运算,机器学习中。矩阵运算毋庸置疑十分重要, 我们在之后的小练习中也会着重体验到重要性。 下面我来介绍在机器学习中最常用的矩阵点积运算。

有两种写法。1)直接用一个矩阵 dot 另一个;2)用 np.dot(a, b) 把两个矩阵包起来。
当然,矩阵还有很多其他的计算,比如 np.outer() 矩阵外积,np.inner() 矩阵内积 (和 np.dot() 的用法稍稍有些不同,你可以理解成 np.dot(a, b)= np.inner(a, b.T), 把 b 做一次转置)(?)存在疑问,这个outer

内积和外积,从某种意义上来说对我它两没啥区别,在计算矩阵相乘的时候,都可以按照内积计算得到新的矩阵。但是上面的outer不知为啥和dot计算出来的不一样。
数据统计分析
什么是数据分析呢?其实也就是在数据中找到你想要的一些变量,总结数据的规律。最简单的当属找到最大值最小值了。 比如上面的身高数据,你想找全班最高和最矮的。

这里也有两种方法可以获取到最大最小,只是不同的写法罢了,你习惯用哪个就用哪个好了。
np.max(a), np.min(a)a.max(), a.min()
累加:print(a.sum())
累乘:a.prod()
计数(总数): a.size

np.count_nonzero():计算非零总数,没有计算零的总数,我试了np.count_zero()报错
在统计学中,我们常会有两个概念,均值,中位数。算算你公司的平均工资是多少?不算不知道,一算吓一跳, 我们公司,因为有一个工资很高的人,平均工资是 4.82w,哈哈哈,我也被平均了。 但是这时候,为了更准确看到普通民众的薪资水平,最好还是用中位数(1.2w)更可靠。

在统计数据分布的时候,还有一个值也比较重要,standard deviation 标准差,用来描述正态分布。 这个在机器学习中,特别是深度神经网络中也非常重要,特别用于权重的生成原则。

特殊运算符号
有的时候,其实你不关心 np.max() 或者 np.min() 的数值是多少,而是关心这个数值的序号, 比如还是那个身高的例子,我找到了最高身高,其实我是想对应上人的。用 np.argmax() 和 np.argmin() 就能搞定。有的时候,其实你不关心 np.max() 或者 np.min() 的数值是多少,而是关心这个数值的序号, 比如还是那个身高的例子,我找到了最高身高,其实我是想对应上人的。用 np.argmax() 和 np.argmin() 就能搞定。

另外一个时不时会用到的功能是,取天花板的值还是地板的值,这个在 AI 算法中也比较常见, 比如我要对其做整数话处理,抹除小数部分。

那我如果还有更自由的取值截取空间时咋办?我可以用 np.clip() 来做上下界限的值截取。
















 283
283











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









