







经典的卷积神经网络:Lenet-5、Alexnet、VGGnet等
Lenet-5:Lenet-5进行卷积运算后,宽度和高度都在下降,通道数量在增加,
另一个神经网络至今依然使用的模式是,你会用一层或多层卷积层 随后是池化层 ,然后再是一层或多层卷积层 随后池化层,然后是几层全连接层 然后输出 ,这种层次排列很常见 。过程中使用的激活函数是sigmoid/tanh

Alexnet:Alexnet与Lenet-5非常相似,但是网络更大。采用Alexnet会产生更多的神经元和隐藏节点,有更多的参数。Alexnet使用的是Relu激活函数,Lenet-5使用的sigmoid/tanh函数

VGGnet/VGG-16:
按作者所说关于VGG-16非常值得注意的一点是 ,与大量的超参数不同 ,VGG-16结构更简单 更能关注卷积层,即3乘3 步长为1 用相同填充的卷积滤波器 ,所有最大池化层滤波器都是2乘2 步长为2 .VGG有个优点 ,VGG有个优点是真正简化了神经网络结构

残差网络(ResNet):Resnet使用了跳跃链接(skip connect)方式,跳跃传递到下一层,这个方法能够训练更大的神经网络,避免神经网络层数过多误差反而上升的情况

Resnet表现好的原因:
假如参数w(l+2)=0,b(l+2)=0,使用Relu激活,a(l)为正值,则a(l+2)=a(l)。Resent在网络中就能够传递的更更深。

1✖1过滤器的应用:在单个通道中使用作用1*1卷积,只是单纯的数字相乘。在多个通道中1*1卷积的效果可以增加非线性 ,使得你的网络可以学习到更复杂函数形式,允许你缩小或不改变输入体积的通道数 。

Inception Network
inception Network首先对输入层使用1*1过滤器做卷积运算,降低通道的维度,这个过程就像是瓶颈层一样;然后再进行新的卷积运算,最后在把所有的卷积结果串联起来。
如此剧烈地缩小特征表示的大小 会不会影响神经网路的性能 ?
答案就是:如果你只要合理地去实现这个瓶颈层 ,你既可以缩小输入张量的维度 ,又不会影响到整体的性能 ,还能给你节省计算成本
在一层一个过滤器中的运算结果如下:


完整的一层Inception Network结果如下:

整个Inception Network示意图如下:

迁移学习:
如果你的数据集数量非常少,下载类似的数据库训练的结果,冻结前面所有的权重系数,只训练最后分类的激活层;
如果你的数据集数量非常少,下载类似的数据库训练的结果,冻结前面的部分权重系数,训练最后分类的激活层/后面几层结果;
如果你的数据非常大,下载类似数据库的训练的结果作为初始权重来替代随机初始化权重,你可以更快的训练适合你的结果

数据增强技术:数据增强是其中一种常用技术用于来改善计算机视觉系统的性能。
第一种常用的数据增强技术有:镜像技术和随机剪切(随机剪切占据原图很大一部分),旋转、剪切图片、局部弯曲等方式并不常用
如:

第二种数据增强技术:色彩变化
计算机识别的发展状况:
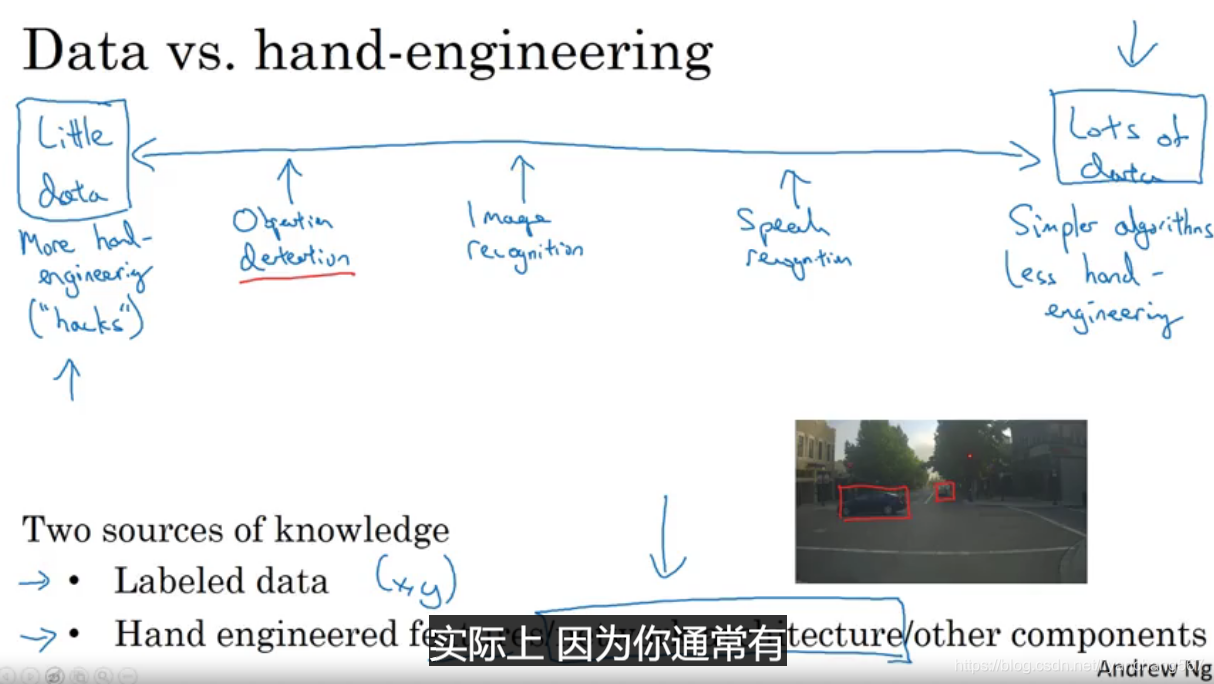
数据量由小到大的不同阶段,使用的方法不完全一样。
数据量小的时候,可以实现目标检测;数据量相对大些可以实现图片识别,数据量足够大,可以构建端到端的算法系统
在只有少量数据的情况下,也可以使用迁移学习来尝试解决问题
两种重要的学习内容的来源:
1、有标记的数据;
2、手工设计的特征。
人工设计是一项非常难的 且非常需要技巧的工作 它需要很深入的洞察力 。那些有对人工设计有深刻见解的人会获得更好的效果 ,并且 在没有足够数据的情况下 ,对项目而言这也是一个巨大的贡献 。
竞赛提高效果的小建议,这些方法不会用在实际工程操作中应用:
1、集成:独立训练多个独立的神经网络,对结果求平均值。这需要保留多个神经网络训练的结果,会占用很多内存,而且训练多个神经网络对计算资源的消耗也会非常大,不适合工程中应用。
2、多次随机剪切的方式

使用开源代码:
1、因为很多计算机视觉问题是在拥有少量数据的范畴 ,前人已经对网络结构做了大量的人工处理。一个神经网络在某个视觉问题上效果很好的网络 通常惊人的是 它们大多在另外的视觉问题上也能用 。一般搭建一个计算机视觉系统,可一从别人的神经网络架构开始。
2、你可以用开源实现 ,因为那个开源实现或许已经搞清楚了 ,所有繁复细致的细节 比如学习率 ,调度 以及其它超参数 ,
3、 其他人或许花了好几个星期训练一个模型 ,用了半打GPU以及上百万的图像。所以 使用别人预先训练的模型 然后在你的数据集上进行微调 你通常也可以应用














 447
447











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









