







http://www.cnblogs.com/hd-zg/p/6904727.html
1. Presto 是什么
Facebook presto是什么,继Facebook创建了HIVE神器后的又一以SQL语言作为接口的分布式实时查询引擎,可以对PB级的数据进行快速的交互式查询。它支持标准的ANSI SQL.包含查询,聚合,JOIN以及窗口函数等。除了Facebook这个创造都在使用外,国内像京东,美团等也都有广泛的使用。对于英文不好的同学可以访问由京东创建的这个中文翻译站点:http://prestodb-china.com/,只是这个版本才0.100,现在最新版已到0.156.
Presto是一个开源的分布式SQL查询引擎,适用于交互式分析查询,数据量支持GB到PB字节。
Presto的设计和编写完全是为了解决像Facebook这样规模的商业数据仓库的交互式分析和处理速度的问题。
它可以做什么?
Presto支持在线数据查询,包括Hive, Cassandra, 关系数据库以及专有数据存储。 一条Presto查询可以将多个数据源的数据进行合并,可以跨越整个组织进行分析。
Presto以分析师的需求作为目标,他们期望响应时间小于1秒到几分钟。 Presto终结了数据分析的两难选择,要么使用速度快的昂贵的商业方案,要么使用消耗大量硬件的慢速的“免费”方案。
谁在使用它?
Facebook使用Presto进行交互式查询,用于多个内部数据存储,包括300PB的数据仓库。 每天有1000多名Facebook员工使用Presto,执行查询次数超过30000次,扫描数据总量超过1PB。
领先的互联网公司包括Airbnb和Dropbox都在使用Presto。
2. Presto 结构
Presto同样是需要部署到每一个DataNode上的分布式系统,它包括一个coordinator和多个worker:
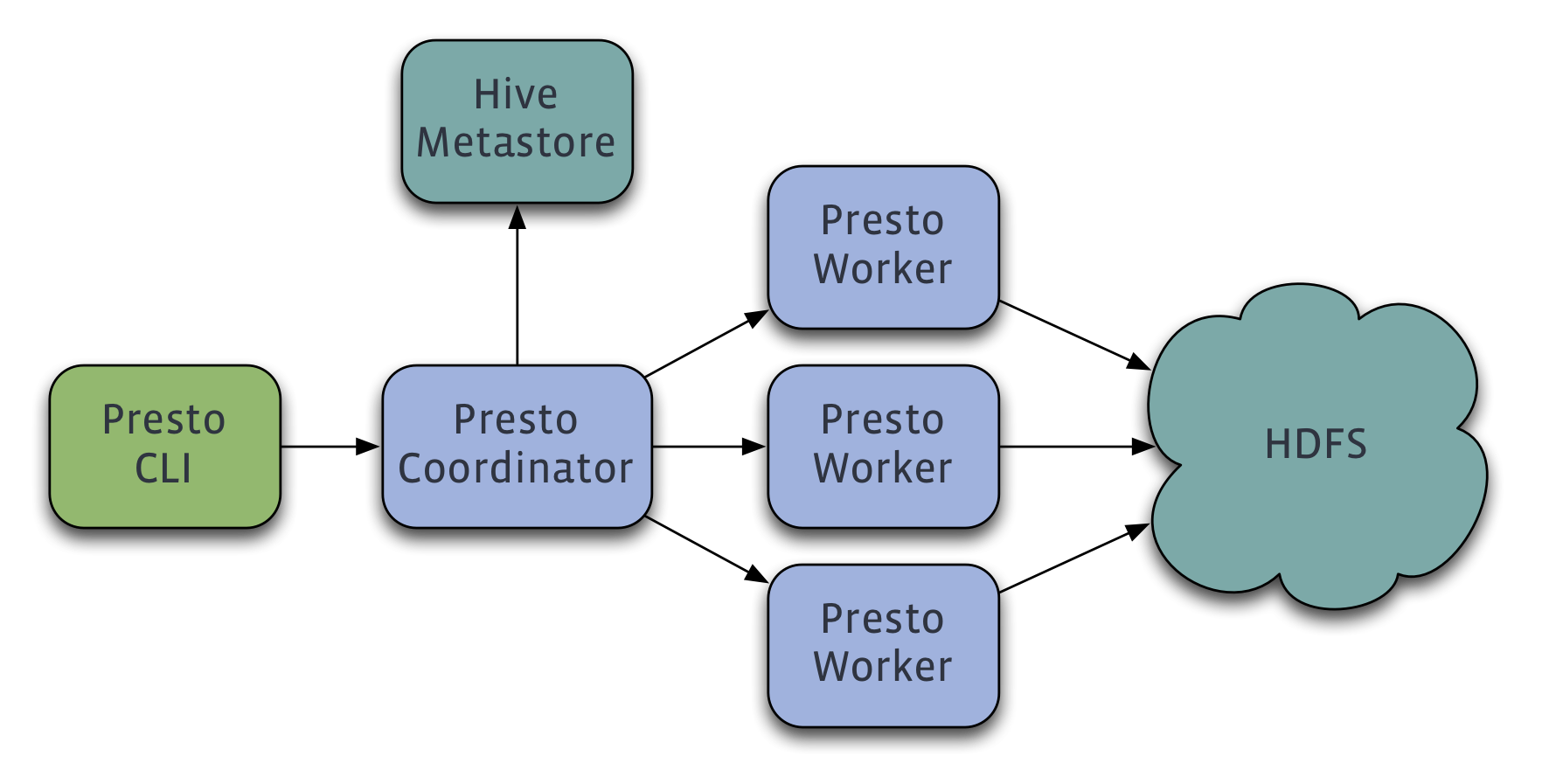
- Coordinator: 接入接口,解析SQL语句,生成查询计划,任务分发等。
- Worker:负责与数据的读写交互以及执行查询计划
值得一提的是Presto以插件形式对数据存储层进行了抽象,它叫做连接器,如:Cassandra Connector,Hive Connector,MySQL Connector等,可以看出它不仅默认提供了Hadoop相关组件的连接器,还提供了Mysql, Postgresql等RDBMS的连接器,同时也可以方便的通过自定义连接器开发,达到适用于不同数据存储层的扩展目的。
Presto提供以下几种类型的使用接口:
- Presto命令行
- JDBC驱动
3. Presto安装
Presto只支持Linux系统的部署。它的Worker节点同时也可以作为Coordinator节点,但是Presto建议独立部署Coordinator节点,并采用独立服务器进行部署,避免性能影响。
本文的测试环境为基于CDH 5.5的Hadoop集群环境的安装和测试。Presto 版本:0.152.3. Presto 的安装JDK版本必须要求:1.8. 安全方式为独立Coordinator节点+Worker节点的方式
1. 解压Presto到每一台Worker节点和Coordinator节点
tar -xzvf presto-server-0.152.3.tar.gz- 1
2. 配置node.properties
node.properties包含了Presto的节点配置信息,在解压后目录的 etc/node.properties位置。,如:
node.environment=myprestoproduction #全部相同的集群名字,经测试不能大小写混合
node.id=ffffffff-ffff-ffff-ffff-fffffffffff1 #这个每个presto节点ID都需要不一样,可在后面数字递增
node.data-dir=/usr/local/presto-server-0.152.3/data #presto数据存储目录,放在了解压软件目录下- 1
- 2
- 3
3. 配置jvm.config
jvm.config这个配置文件通过名字,大家应该知道是配置什么了吧。内容如下:
-server
-Xmx8G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:OnOutOfMemoryError=kill -9 %p- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
4. Presto配置:config.properties
config.properties配置文件用于配置Presto的运行参数,这里Coordinator与Workder节点需要分开配置不同的内容。
Coordinator节点配置:
coordinator=true #这里指定作为coordinator节点运行
node-scheduler.include-coordinator=false
http-server.http.port=8089
query.max-memory=50GB #单个查询可用的总内存
query.max-memory-per-node=1GB #单个查询单个节点的可用最大内存
discovery-server.enabled=true #Discovery服务用于Presto集群的节点状态服务
discovery.uri=http://master:8089- 1
- 2
- 3
- 4
- 5
- 6
- 7
Worker节点配置:
coordinator=false
http-server.http.port=8089
query.max-memory=50GB
query.max-memory-per-node=1GB
discovery.uri=http://master:8089- 1
- 2
- 3
- 4
- 5
- 至此就可以正常启动Presto了。但是没有配置任何Connector的Presto也只能拿来看一看了,所以下面还是先把Hive Connector配置好。
5. 预先配置好Hive Connector
新建好文件: etc/catalog/hive.properties,内容为:
connector.name=hive-cdh5 # 根据Hadoop版本情况,值可以是: hive-hadoop1, hive-hadoop2,hive-cdh4,hive-cdh5
hive.metastore.uri=thrift://master:9083 # hive的MetaStore服务URL
hive.config.resources=/etc/hadoop/conf/core-site.xml,/etc/hadoop/conf/hdfs-site.xml- 1
- 2
- 3
6. 启动Presto
经过这么多的配置,终于可以到了启动Presto这一步,这一步就简单了,直接在每一个节点上执行启动命令即可:
bin/launcher start- 1
- 值得注意的是, CDH安装的JDK版本为1.7,而Presto要求的版本是1.8.因此需要更改launcher文件,在前面增加JAVA环境变量设置,覆盖默认的1.7设置。
7. 连接到Presto
使用命令行连接到Presto:
可是怎会如此轻松就能让你连上去,你得下载一个文件:presto-cli-0.156-executable.jar,然后重命名为presto,并增加可执行权限(chmod +x),后可以执行连接命令:
./presto --server master:8089
presto:default> SELECT * FROM system.runtime.nodes;
node_id | http_uri | node_version | coordinator | state
--------------------------------------+---------------------------+--------------+-------------+--------
ffffffff-ffff-ffff-ffff-fffffffffff2 | http://192.168.5.202:8089 | 0.152.3 | false | active
ffffffff-ffff-ffff-ffff-fffffffffff1 | http://192.168.5.200:8089 | 0.152.3 | true | active
ffffffff-ffff-ffff-ffff-fffffffffff3 | http://192.168.5.203:8089 | 0.152.3 | false | active
ffffffff-ffff-ffff-ffff-fffffffffff4 | http://192.168.5.204:8089 | 0.152.3 | false | active
(4 rows)
Query 20161108_101627_00016_3i6da, FINISHED, 2 nodes
Splits: 2 total, 2 done (100.00%)
0:00 [4 rows, 300B] [9 rows/s, 727B/s]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
system连接器是Presto自带的连接器,不需要配置。包含Presto的节点信息,配置信息以及metrics信息等。
5. 使用Presto查询HIVE表数据
1. 使用命令行连接到Presto,并指定使用HIVE连接器:
./presto-cli-0.107-jd-executable.jar --server master:8089 --catalog hive --schema default
#指定默认连接到HIVE的default数据库- 1
- 2
2. 查询HIVE表数据,接下来就可以使用标准SQL查询HIVE数据,如:
presto:default> desc sample_08;
Column | Type | Comment
-------------+---------+---------
code | varchar |
description | varchar |
total_emp | integer |
salary | integer |
(4 rows)
Query 20161108_145619_00028_3i6da, FINISHED, 2 nodes
Splits: 2 total, 2 done (100.00%)
0:00 [4 rows, 258B] [11 rows/s, 726B/s]
presto:default> select * from sample_08 limit 3;
code | description | total_emp | salary
---------+------------------------+-----------+--------
00-0000 | All Occupations | 135185230 | 42270
11-0000 | Management occupations | 6152650 | 100310
11-1011 | Chief executives | 301930 | 160440
(3 rows)
Query 20161108_145632_00029_3i6da, FINISHED, 2 nodes
Splits: 2 total, 2 done (100.00%)
0:02 [823 rows, 45KB] [439 rows/s, 24KB/s]
- 12
- 13
- 14
6. 问题
1. 在使用Presto查询Parquet格式中的Decimal数据类型时会出现异常,需要手动转换:
presto:default> desc test_decimal;
Column | Type | Comment
----------+---------------+---------
dec_col | decimal(2,0) |
(1 rows)
Query 20161108_151431_00066_3i6da, FINISHED, 2 nodes
Splits: 2 total, 2 done (100.00%)
0:00 [5 rows, 358B] [14 rows/s, 1.02KB/s]
presto:default> select dec_col from test_decimal limit 1;
Query is gone (server restarted?) #这儿产生异常了
presto:default> select cast(dec_col as integer) from test_decimal limit 1;
_col0
-------
1
(1 row)
Query 20161108_151456_00068_3i6da, FINISHED, 1 node
Splits: 2 total, 2 done (100.00%)
0:00 [7.28K rows, 118KB] [19.5K rows/s, 314KB/s]2. 另外一个就是Presto的异常信息太简结了,很多都是Query is gone,很不好排查,如:
presto:default> explain select * from sample_08;
Query is gone (server restarted?)3. 兼容性问题,比如:
presto:default> select * from sample_tabpart limit 10;
Query 20161109_031436_00013_3i6da failed: Unsupported Hive type char(4) found in partition keys of table default.sample_tabpart
# 不支持以CHAR为类型的分区KEY7. 最后
Facebook presto虽然发展时间不长,版本也还不高,但当前版本在功能上已比较丰富,而且在查询效率上已达到了近乎实时的要求,且非常灵活。Presto将会成为实时查询工具上的一个重要选择。
转:http://blog.csdn.net/hezh914/article/details/53097853















 2348
2348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









