







一、k-means算法解决的问题
将一个数据集分为k类的问题(将这些数据点集聚类到K类中去)。
二、k-means算法描述
1、
随机选取k个点分别作为 类1,类2……类K 的中心点
2、
遍历所有的数据点,对于每一个点 计算它到 中心点1,中心点2…… 中心点k 的欧氏距离,并把这个点归入到与之距离最小的中心点所在的类
3、
更新每一类的中心点,新的中心点为该类所有点的平均值。
然后跳到步骤2继续执行,直到满足你的跳出条件。
一般跳出条件可以如下:
比较一个类 目前的中心点与之前的中心点的偏移程度,当偏移程度较小或为零时跳出。
三、演示图
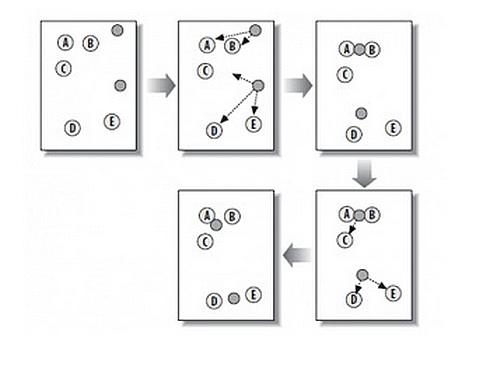
演示图按照次序依次进行的是
1、随机选取两个中心点
2、将所有点划分到距离较近的中心点
3、重新计算中心点
4、重新划分类
5、重新计算中心点
四、简单的实践
我们给出一组二维的数据把它划分为5类
K = 5;
dataSet = load('2d-data.mat');%载入数据
[row,col] = size(dataSet.r);
% 存储质心矩阵
centSet = zeros(K,col);%censet作为储存中心点的矩阵
% 随机初始化质心
for i= 1:col
minV = min(dataSet.r(:,i));
rangV = max(dataSet.r(:,i)) - minV;
centSet(:,i) = repmat(minV,[K,1]) + rangV*rand(K,1);
end
% 用于存储每个点被分配的cluster以及到质心的距离
clusterAssment = zeros(row,2);%用来储存每个点到中心点的距离
clusterChange = true;%用来储存中心点是否改变
while clusterChange
clusterChange = false;
% 计算每个点应该被分配的cluster
for i = 1:row
minDist = 10000;
minIndex = 0;
for j = 1:K
distCal = distEclud(dataSet.r(i,:) , centSet(j,:));
if (distCal < minDist)
minDist = distCal;
minIndex = j;
end
end
if minIndex ~= clusterAssment(i,1)
clusterChange = true;
end
clusterAssment(i,1) = minIndex;
clusterAssment(i,2) = minDist;
end
% 更新每个cluster 的质心
for j = 1:K
simpleCluster = find(clusterAssment(:,1) == j);% simpleCluster是一个列向量,储存的是符合条件的位置
centSet(j,:) = mean1(dataSet.r(simpleCluster',:));
end
end
%画图
figure
for i = 1:K
pointCluster = find(clusterAssment(:,1) == i);
scatter(dataSet.r(pointCluster,1),dataSet.r(pointCluster,2),5)
hold on
end
%hold on
scatter(centSet(:,1),centSet(:,2),300,'+')
hold off
end
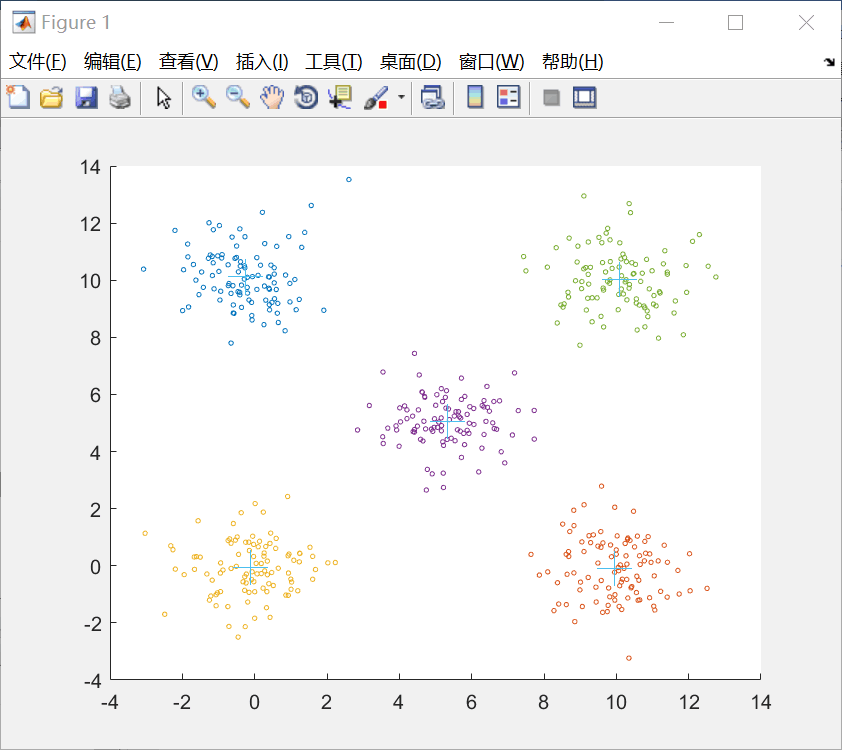
下面是程序的结果:















 290
290











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









