







声明:语音合成(TTS)论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。如有转载,请标注来源。欢迎关注公众号:低调奋进
TTS-BY-TTS: TTS-DRIVEN DATA AUGMENTATION FOR FAST AND HIGH-QUALITY SPEECH SYNTHESIS
本篇文章主要使用TTS合成的音频来优化TTS,我感觉这个思想跟编译器的“自举”行为非常相似。该篇文章2020.10.26出自韩国和日本,具体链接
http://yqli.tech/pdf/tts_paper/TTS-BY-TTS-%20TTS-DRIVEN%20DATA%20AUGMENTATION%20FOR%20FAST%20AND%20HIGH-QUALITY%20SPEECH%20SYNTHESIS.pdf
1 研究背景
现在基于神经网络的端到端(end-to-end)TTS合成的语音已经十分接近人类,其大体的结构包括seq-to-seq的声学模型和基于神经网络的声码器。目前声学模型主要分为两大类,第一类是自回归(autoregressive)的模型,代表系统为tacotron,其生成每一帧声学特征需要前一帧作为输入,该类模型的特点是合成的音质很高,但无法并行,合成实时率较低。第二类模型是非自回归(non-autoregressive)模型,该模型可以并行生成声学特征,实时率较高,代表系统为fastspeech。为了优化non-AR的合成效果,本文提出使用AR的TTS来优化non-AR的合成质量。
2 系统介绍
该系统十分简单,主要的思想如图一所示。先使用较少的高质量数据训练一个AR TTS,然后使用训练好的AR TTS生成音频,最后使用合成的音频对non-AR进行训练。例如本文章使用5个小时的语料来训练AR TTS,然后合成179小时的增量数据,最后使用增量的数据来优化non-AR TTS。该文章的整体思路十分简单。
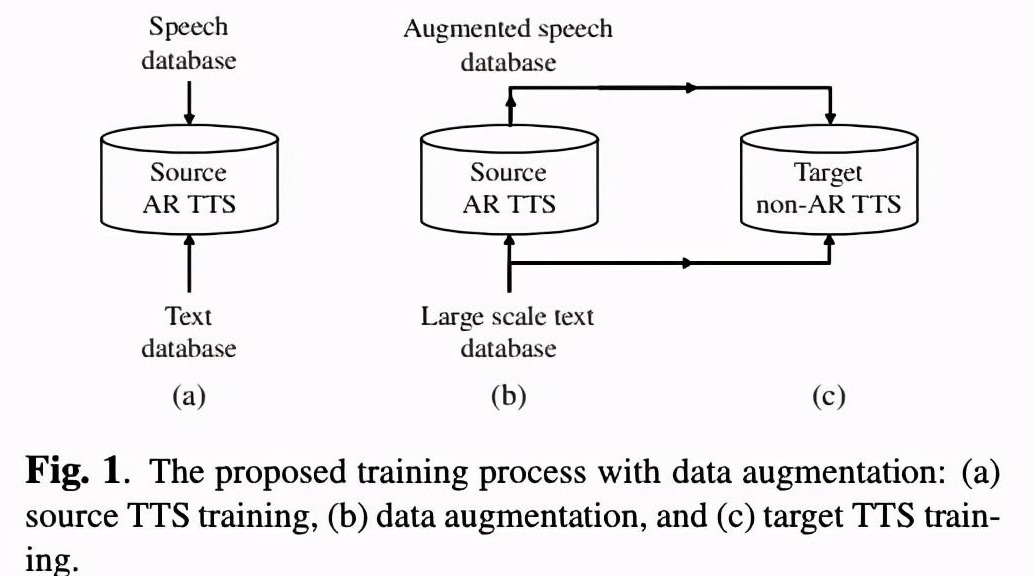
以下是本篇文章选择使用的AR和non-AR TTS的组合,都是非常具有代表性的系统。

3 实验结果
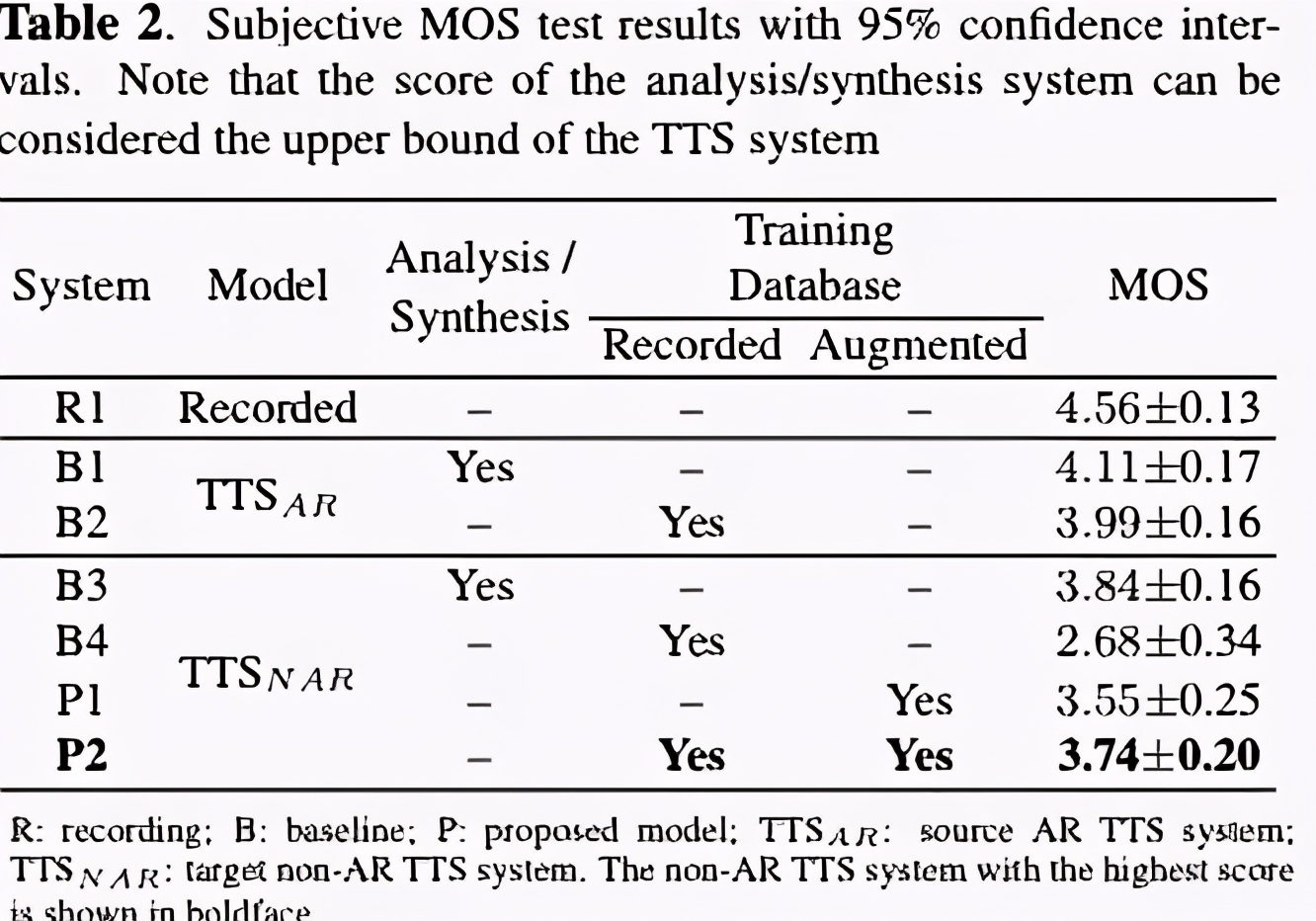
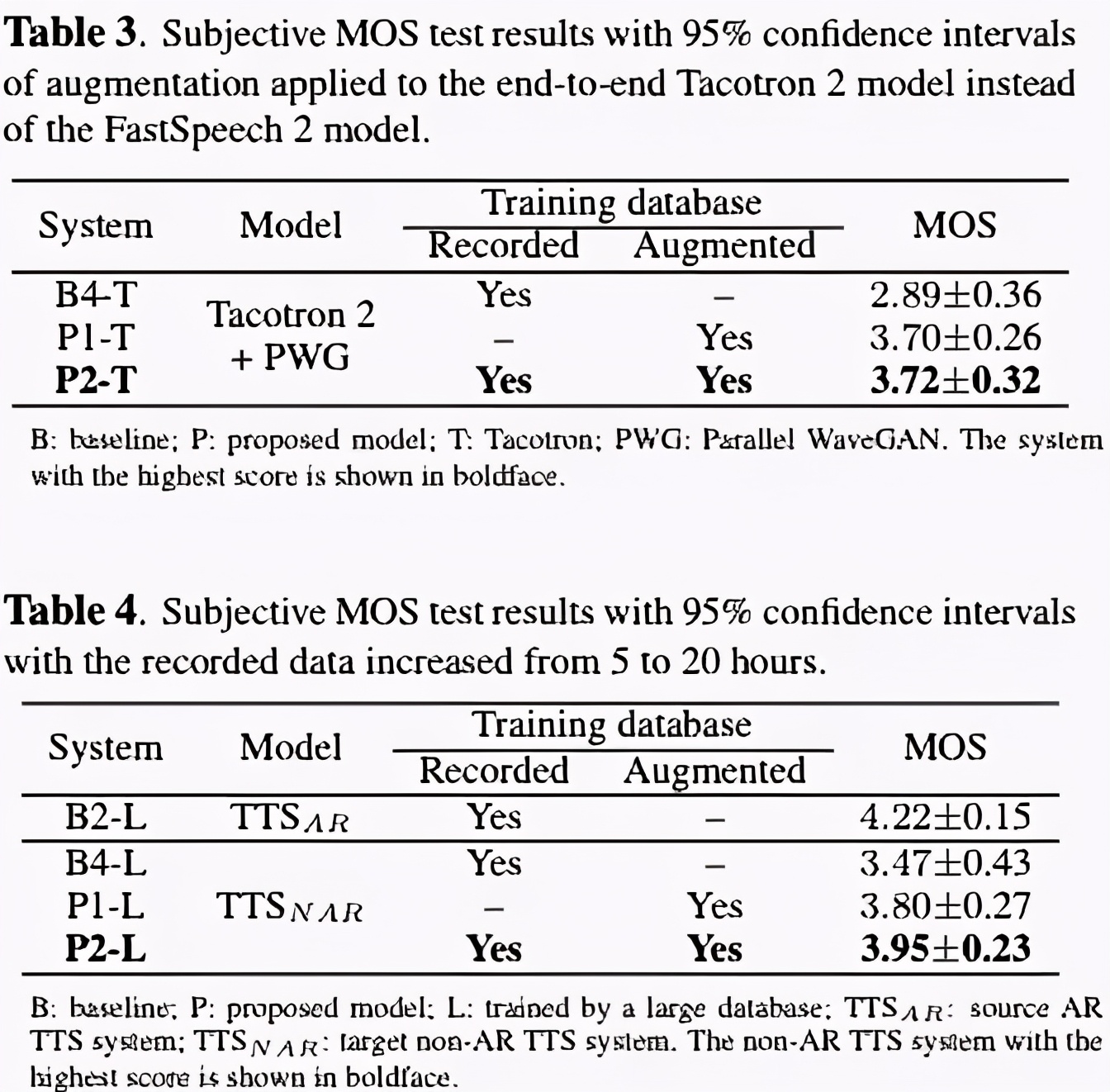
这篇文章主要是思想和调参。其结果如下可知。使用data augument的TTS 的MOS值是逐渐增加。另外从结果也印证了AR的效果往往比Non-AR较好。
4 总结
这篇文章整体没有特别的难度,主要提出了tts-by-tts这种思想。当然,我个人认为,如果AR TTS效果很差,non-AR的效果也不会很好。
欢迎关注微信公众号:低调奋进

















 754
754











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











