







功能:
1、爬取百度贴吧内容:
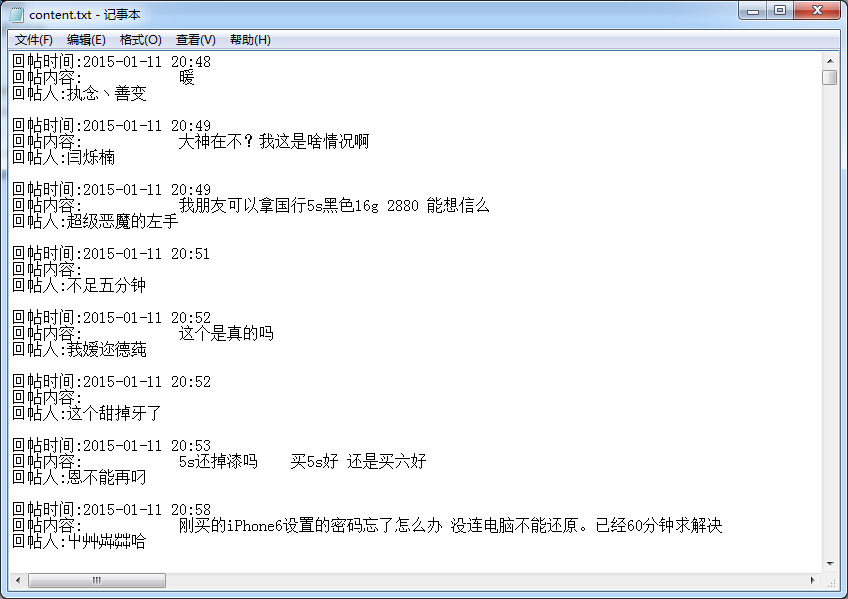
回帖时间
回帖内容
回帖人
2、通过xpath来提取属性,并将提取的属性写入到txt文件中
3、多线程实现
下面是代码:
# -*- coding: utf-8 -*-
"""
Created on Fri Sep 11 22:03:40 2015
@author: wt
"""
from lxml import etree
from multiprocessing.dummy import Pool as ThreadPool
import requests
import json
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
def towrite(contentdict):
f.writelines(u'回帖时间:' + str(contentdict['topic_reply_time']) + '\n')
f.writelines(u'回帖内容:' + unicode(contentdict['topic_reply_content']) + '\n')
f.writelines(u'回帖人:' + contentdict['user_name'] + '\n\n')
def spider(url):
html = requests.get(url)
selector = etree.HTML(html.text)
content_field = selector.xpath('//div[@class="l_post j_l_post l_post_bright "]')
#print content_field
item = {}
for each in content_field:
reply_info = json.loads(each.xpath('@data-field')[0].replace('"', ''))
print reply_info
author = reply_info['author']['user_name']
content = each.xpath('div[@class="d_post_content_main"]/div/cc/div[@class="d_post_content j_d_post_content clearfix"]/text()')[0]
reply_time = reply_info['content']['date']
print content
print reply_time
print author
item['user_name'] = author
item['topic_reply_content'] = content
item['topic_reply_time'] = reply_time
towrite(item)
if __name__ == '__main__':
pool = ThreadPool(4)
f = open('content.txt', 'a+')
page = []
for i in range(1, 21):
newpage = 'http://tieba.baidu.com/p/3522395718?pn=' + str(i)
page.append(newpage)
# print page
results = pool.map(spider, page)
pool.close()
pool.join()
f.close()执行的结果















 128
128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









