






目录
2.1 VOC形式及其数据结构XML特点(好像可以使用py库中工具直接进行清洗)
1.先验知识
数据集的概念:要进行机器学习,首先要有数据,数据集是机器学习的基础。数据集(Dataset)是一组样本(Example)的集合,样本这是数据集中的一行或者一列,包含一个或多个特征,机器学习就是对该集合中的特征进行处理分析。
这是一份人们发现对计算机视觉研究和算法评估有用的图像和视频数据库的整理列表CV常用数据集,包含了动作、自动驾驶、手势、指纹,城市等等数据集。 数据集格式:在目标检测、识别和分割任务中,通常需对数据集进行标注,然后送入网格进行学习。标注时尝尝采用一些标注软件辅助研究人员进行标签工作,而不同的标签软件在标注后产生的标签信息数据结构是不同的,如labelimg、labelme会产生xml格式的文件、lablebbox则会产生json形式的文件,而常见的机器学习模型在训练时对输入的样本的标签有不同的要求,例如yolo5就要求送入学习的对象其标签信息是txt文本、分割FCN则要求采用数据集资源标签的格式是xml形式的。这就对于在复现工作或者在基于别人学习模型的基础上想要训练自己的数据的研究人员来说,对自己的数据集进行标注后,生成的标签资料要按照模型能够接受的标准来进行整理。
数据集格式:在目标检测、识别和分割任务中,通常需对数据集进行标注,然后送入网格进行学习。标注时尝尝采用一些标注软件辅助研究人员进行标签工作,而不同的标签软件在标注后产生的标签信息数据结构是不同的,如labelimg、labelme会产生xml格式的文件、lablebbox则会产生json形式的文件,而常见的机器学习模型在训练时对输入的样本的标签有不同的要求,例如yolo5就要求送入学习的对象其标签信息是txt文本、分割FCN则要求采用数据集资源标签的格式是xml形式的。这就对于在复现工作或者在基于别人学习模型的基础上想要训练自己的数据的研究人员来说,对自己的数据集进行标注后,生成的标签资料要按照模型能够接受的标准来进行整理。
2. VOC和COCO数据集:
2.1 VOC形式及其数据结构XML特点(好像可以使用py库中工具直接进行清洗)
VOC数据集是目标检测经常用的一个数据集,从05年到12年都会举办比赛(比赛有task: Classification 、Detection(将图片中所有的目标用bounding box框出来) 、 Segmentation(将图片中所有的目标分割出来)、Person Layout)

2.1.1 VOC数据集的组织结构如下所示
(下载上述数据集后,打开文件):
.
└── VOCdevkit #根目录
└── VOC2012 #不同年份的数据集,这里只下载了2012的,还有2007等其它年份的
├── Annotations #存放xml文件,与JPEGImages中的图片一一对应,解释图片的内容等等
├── ImageSets #该目录下存放的都是txt文件,txt文件中每一行包含一个图片的名称,末尾会加上±1表示正负样本
│ ├── Action
│ ├── Layout
│ ├── Main #存放的是分类和检测的数据集分割文件
│ └── Segmentation
├── JPEGImages #存放源图片
├── SegmentationClass #存放的是图片,语义(class)分割相关
└── SegmentationObject #存放的是图片,实例(object)分割相关
├── Main
│ ├── train.txt 写着用于训练的图片名称, 共 2501 个
│ ├── val.txt 写着用于验证的图片名称,共 2510 个
│ ├── trainval.txt train与val的合集。共 5011 个
│ ├── test.txt 写着用于测试的图片名称,共 4952 个ImageSets中存放了用到的图片,annotations中则存放了对应图片的基本信息
采用了xml格式的,其中依次为folder、filename、source、size、object:

<annotation>
<folder>VOC2007</folder>
<filename>000005.jpg</filename>#文件名
<source>#文件来源
<database>The VOC2007 Database</database>
<annotation>PASCAL VOC2007</annotation>
<image>flickr</image>
<flickrid>325991873</flickrid>
</source>
<owner>
<flickrid>archintent louisville</flickrid>
<name>?</name>
</owner>
<size>#文件尺寸,包括长、宽、通道数
<width>500</width>
<height>375</height>
<depth>3</depth>
</size>
<segmented>0</segmented>#是否用于分割
<object>#检测目标
<name>chair</name>#目标类别
<pose>Rear</pose>#摄像头角度
<truncated>0</truncated>#是否被截断,0表示完整
<difficult>0</difficult>#目标是否难以识别,0表示容易识别
<bndbox>#bounding-box
<xmin>263</xmin>
<ymin>211</ymin>
<xmax>324</xmax>
<ymax>339</ymax>
</bndbox>
</object>
<object>#检测到的多个物体, 可以看到上图中,图片000005中有多个椅子
<name>chair</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>165</xmin>
<ymin>264</ymin>
<xmax>253</xmax>
<ymax>372</ymax>
</bndbox>
</object>
<object>#检测到的多个物体
<name>chair</name>
<pose>Unspecified</pose>
<truncated>1</truncated>
<difficult>1</difficult>
<bndbox>
<xmin>5</xmin>
<ymin>244</ymin>
<xmax>67</xmax>
<ymax>374</ymax>
</bndbox>
</object>
<object>
<name>chair</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>241</xmin>
<ymin>194</ymin>
<xmax>295</xmax>
<ymax>299</ymax>
</bndbox>
</object>
<object>#检测到的多个物体
<name>chair</name>
<pose>Unspecified</pose>
<truncated>1</truncated>
<difficult>1</difficult>
<bndbox>
<xmin>277</xmin>
<ymin>186</ymin>
<xmax>312</xmax>
<ymax>220</ymax>
</bndbox>
</object>
</annotation>2.1.2 XML的操作
XML(Extensible Markup Language)是一种类似于HTML的标记语言,是一种结构化、层级化的数据格式,最适合体现XML的数据结构就是树,例如VOC2012年数据集中的标签格式:
XML常用于程序间数据传输、做配置文件、充当小型的数据库,其一般由version、encoding、standalon三部分组成,在python中可以调用Python xml.etree.ElementTree来解析XML文件,ET提供了两个对象:ElementTree将整个XML文档转化为树,Element则代表着树上的单个节点。对整个XML文档的交互(读取,写入,查找需要的元素),一般是在ElementTree层面进行的。对单个XML元素及其子元素,则是在Element层面进行。使用xml.etree来解析XML实例演示:
2.1.3 XML实例:country_data.xml
<?xml version="1.0"?>
<data name="Kaina" age="18">
<country name="列支敦斯登">
<rank>1</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="澳大利亚" direction="东部"/>
<neighbor name="新西兰" direction="西部"/>
</country>
<country name="新加坡">
<rank>4</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="马来西亚" direction="北部"/>
</country>
<country name=" 巴拿马">
<rank>68</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="哥斯达黎加" direction="西部"/>
<neighbor name=" 哥伦比亚" direction="东部"/>
</country>
</data>
(1)对XML进行读取
import xml.etree.ElementTree as ET
#1.解析xml文件,返回ElementTree对象
tree = ET.parse('country_data.xml')
#2.获得根节点
root = tree.getroot()
#3.打印根节点标签名
print("coutry_data.xml的根节点:"+root.tag)
#4.打印出根节点的属性和属性值
print("根节点标签里的属性和属性值:"+str(root.attrib))
#5.通过遍历获取孩子节点的标签、属性和属性值
for child in root:
print(child.tag, child.attrib)
#6.获取country标签下的子标签的内容
print("排名:"+root[0][0].text,"国内生产总值:"+root[0][2].text,)
#7.把所有neighbor标签找出来,并打印出标签的属性和属性值。
for neighbor in root.iter('neighbor'):
print(neighbor.attrib)
#8.使用findall()方法把满足条件的标签找出来迭代。
for country in root.findall('country'):
rank = country.find('rank').text
name = country.get('name')
print(name,rank)
(2)对XML文件进行修改操作
import xml.etree.ElementTree as ET
#1.解析xml文件,返回ElementTree对象
tree = ET.parse('country_data.xml')
#2.获得根节点
root = tree.getroot()
#3.遍历修改标签(添加属性和属性值、修改属性值、删除标签)
for rank in root.iter("rank"):
new_rank=int(rank.text)+1
rank.text=str(new_rank)
rank.set("updated","yes")
#4.write()的作用:创建文件,并把xml写入新的文件
#5.指定写入内容的编码
tree.write("output.xml",encoding="utf-8")
>>>修改后的形式
<data age="18" name="Kaina">
<country name="列支敦斯登">
<rank updated="yes">2</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor direction="东部" name="澳大利亚" />
<neighbor direction="西部" name="新西兰" />
</country>
<country name="新加坡">
<rank updated="yes">5</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor direction="北部" name="马来西亚" />
</country>
<country name=" 巴拿马">
<rank updated="yes">69</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor direction="西部" name="哥斯达黎加" />
<neighbor direction="东部" name=" 哥伦比亚" />
</country>
</data>
(3)对XML进行删除
import xml.etree.ElementTree as ET
#1.解析xml文件,返回ElementTree对象
tree = ET.parse('country_data.xml')
#2.获得根节点
root = tree.getroot()
#3.通过遍历获得满足条件的元素,并使用remove()指定删除
for country in root.findall('country'):
rank=int(country.find("rank").text)
if rank>50:
root.remove(country)
#4.删除后再把数据保存到output.xml文件中
tree.write("output.xml",encoding="utf-8")
>>>
<data age="18" name="Kaina">
<country name="列支敦斯登">
<rank>1</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor direction="东部" name="澳大利亚" />
<neighbor direction="西部" name="新西兰" />
</country>
<country name="新加坡">
<rank>4</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor direction="北部" name="马来西亚" />
</country>
</data>
针对XML具体任务需要,一般有两种方法
- 一:读取一个XML文档,进行修改,然后再将修改写入文档;
- 二:从头创建一个新XML文档。
在目标检测的任务过程中涉及到了对XML格式的修改,即将json文件转换成VOC的标准格式,具体采用的方法是将json转换至普通XML,然后引入VOC数据集要求的XML模板,对json文件进行转换并套上VOC.xml模板,具体过程见下文。
首先是讲怎么使用模板修改XML
任务: 先打开一个定义好的.xlm格式的模板文件,之后将TXT文件中的标注框信息逐行读入,用于修改xlm文件模板对应的指标数据,最后将修改后的新xlm文件写出保存。
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank>1</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank>4</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank>68</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
#核心思想:先打开一个定义好的xlm文件模板,之后将TXT文件中的标注框信息逐行读入,用于修改xlm文件模板对应的指标数据,最后将修改后的新xlm文件写出保存。
import copy
from lxml.etree import Element, SubElement, tostring, ElementTree
import cv2
# 模板xlm文件的存储路径
template_file = r'/Users/edz/Documents/yandi_data/taishi_loading/to_xlm/anno.xml'
path = r'/Users/edz/Documents/yandi_data/taishi_loading/to_xlm/'
# TXT文件数据的原始格式
train_files = '014f80f346d72001267240b1a62f1b72.jpg id12 1.3418148e+03, 6.2916492e+02, 1.4483580e+03, 9.2253162e+02, 6.3271374e-01'
trainFile = train_files.split() # trainFile存放全量的原始数据
print('原始数据集格式:{}'.format(trainFile))
>>>
原始数据集格式:['014f80f346d72001267240b1a62f1b72.jpg', 'id12', '1.3418148e+03,', '6.2916492e+02,', '1.4483580e+03,', '9.2253162e+02,', '6.3271374e-01']
file_name = trainFile[0]
print(file_name)
>>>
014f80f346d72001267240b1a62f1b72.jpg
# 定义新的xlm文件的详细指标数据
label = trainFile[1]
xmin = trainFile[2]
ymin = trainFile[3]
xmax = trainFile[4]
ymax = trainFile[5]
############# 读取模板xlm文件——用于存放TXT文件内容:
tree.parse(template_file) # 调用parse()方法,返回解析树
root = tree.getroot() # 获取根节点
##########修改新的xlm文件的详细指标数据
# folder
root.find('folder').text = 'new_folders'
# 修改魔板xlm文件中的内容为目标结果
root.find('filename').text = file_name # 2.Element.find() :找到第一个带有特定标签的子元素。
# # path
root.find('path').text = path + file_name
# 查看部分修改结果
print(root.find('filename').text) # 第一层下每一项内容
print(root.find('path').text) # 第一层下每一项内容
print(root.find('size').find('height').text) # 查看第二层下每一项内容
print(root.find('object').find('bndbox').find('xmin').text) # 查看第三层下每一项内容
>>>
014f80f346d72001267240b1a62f1b72.jpg
/Users/edz/Documents/yandi_data/taishi_loading/to_xlm/014f80f346d72001267240b1a62f1b72.jpg
1556
1378
# size
sz = root.find('size')
im = cv2.imread(path + file_name) # 读取图片信息
sz.find('height').text = str(im.shape[0])
sz.find('width').text = str(im.shape[1])
sz.find('depth').text = str(im.shape[2])
print('iamge height:',im.shape[0])
print('iamge width:',im.shape[1])
print('iamge depth:',im.shape[2])
>>>
iamge height: 1556
iamge width: 1924
iamge depth: 3
# object
obj = root.find('object')
obj.find('name').text = label
bb = obj.find('bndbox')
bb.find('xmin').text = xmin
bb.find('ymin').text = ymin
bb.find('xmax').text = xmax
bb.find('ymax').text = ymax
########## 校验修改后的root是否为新数据
root.find('object').find('bndbox').find('ymax').text
>>>
'9.2253162e+02,' # 符合预期
########## 保存新生成的xlm数据文件
tree=ET.ElementTree(root)
tree.write("/Users/edz/Documents/yandi_data/taishi_loading/to_xlm/99.xml")
2.2 coco数据集形式及其数据结构JOSN特点
(可以使用pycocotools工具直接进行清洗)
COCO数据集是一个大型的、丰富的物体检测,分割和字幕数据集。这个数据集以scene understanding为目标,主要从复杂的日常场景中截取,图像中的目标通过精确的segmentation进行位置的标定。图像包括91类目标,328,000影像和2,500,000个label。目前为止有语义分割的最大数据集,提供的类别有80 类,有超过33 万张图片,其中20 万张有标注,整个数据集中个体的数目超过150 万个。
该数据集主要解决3个问题:目标检测,目标之间的上下文关系,目标的2维上的精确定位。数据集的对比示意图:
COCO通过大量使用Amazon Mechanical Turk来收集数据。COCO数据集现在有3种标注类型:object instances(目标实例), object keypoints(目标上的关键点), 和image captions(看图说话),使用JSON文件存储。
├── coco2017: 数据集根目录
├── train2017: 所有训练图像文件夹(118287张)
├── val2017: 所有验证图像文件夹(5000张)
└── annotations: 对应标注文件夹
├── instances_train2017.json: 对应目标检测、分割任务的训练集标注文件
├── instances_val2017.json: 对应目标检测、分割任务的验证集标注文件
├── captions_train2017.json: 对应图像描述的训练集标注文件
├── captions_val2017.json: 对应图像描述的验证集标注文件
├── person_keypoints_train2017.json: 对应人体关键点检测的训练集标注文件
└── person_keypoints_val2017.json: 对应人体关键点检测的验证集标注文件夹
2.2.1 coco格式
COCO有5种类型的标注,分别是:物体检测、关键点检测、实例分割、全景分割、图片标注,都是对应一个json文件,json是一个大字典,都包含如下的关键字共享且相同:info、licenses、images共享信息如下所示:
{
"info": info,
"licenses": [license],
"images": [image],
"annotations": [annotation],
}
info{
"year": int,
"version": str,
"description": str,
"contributor": str,
"url": str,
"date_created": datetime,
}
license{
"id": int,
"name": str,
"url": str,
}
image{
"id": int,
"width": int,
"height": int,
"file_name": str,
"license": int,
"flickr_url": str,
"coco_url": str,
"date_captured": datetime,
}针对根据不同任务有不同的类别信息categories和不同的标注信息annotations,例如目标检测:
annotation{
"id" : int,
"image_id" : int,
"category_id" : int,
"segmentation" : RLE or [polygon],
"area" : float,
"bbox" : [x,y,width,height],
"iscrowd" : 0 or 1,
}
categories[{
"id" : int,
"name" : str,
"supercategory" : str,
}]关键点检测:
annotation{
"keypoints" : [x1,y1,v1,...],
"num_keypoints" : int,
"[cloned]" : ...,
}
categories[{
"keypoints" : [str],
"skeleton" : [edge],
"[cloned]" : ...,
}]
"[cloned]": denotes fields copied from object detection annotations defined above.实例分割: stuff注释格式与上面的对象检测格式完全相同并完全兼容(除了iscrowd没有必要并且默认设置为0)。为了方便访问,我们提供了JSON和png格式的注释,以及这两种格式之间的转换脚本。在JSON格式中,图像中的每个类别都用一个RLE注释进行编码(更多细节请参阅Mask API)。category_id表示当前物品类别的id。有关物品类别和超类别的更多细节,请参阅物品评估页面。参见stuff task。
全景分割: 对于panoptic任务,每个注释结构是每个图像的注释,而不是每个对象的注释。每个图像注释有两个部分:(1)一个PNG存储与类无关的图像分割;(2)一个JSON结构存储每个图像分割的语义信息。更详细地说:要将注释与图像匹配,请使用image_id字段(也就是注释)。image_id = = image.id)。对于每个注释,每个像素的段id都存储在annotation.file_name中的单个PNG中。这些png文件在一个与JSON文件同名的文件夹中,例如:annotations/name. JSON对应的annotations/name. JSON。每个段(无论是东西段还是东西段)都被分配一个唯一的id。未标记的像素(void)被分配0的值。请注意,当你加载PNG作为RGB图像,你将需要通过ids=R+G256+B256^2计算id。对于每个注释,每个段信息都存储在annotation.segments_info中。segment_info。id存储段的唯一id,用于从PNG (ids==segment_info.id)中检索相应的掩码。category_id给出语义类别,iscrowd表示该段包含一组对象(仅与事物类别相关)。bbox和area字段提供了关于段的额外信息。COCO panoptic任务具有与检测任务相同的事物类别,而物品类别与stuff任务不同(详情请参见panoptic评估页面)。最后,每个类别结构都有两个额外的字段:区分事物和事物类别的isthing和有助于一致可视化的颜色。
annotation{
"image_id" : int,
"file_name" : str,
"segments_info" : [segment_info],
}
segment_info{
"id" : int,
"category_id" : int,
"area" : int,
"bbox" : [x,y,width,height],
"iscrowd" : 0 or 1,
}
categories[{
"id" : int,
"name" : str,
"supercategory" : str,
"isthing" : 0 or 1,
"color" : [R,G,B],
}]图像标注:
annotation{
"id" : int,
"image_id" : int,
"caption" : str,
}2.2.2 json数据结构及操作
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它是JavaScript的子集,易于人阅读和编写。前端和后端进行数据交互,其实就是JS和Python进行数据交互
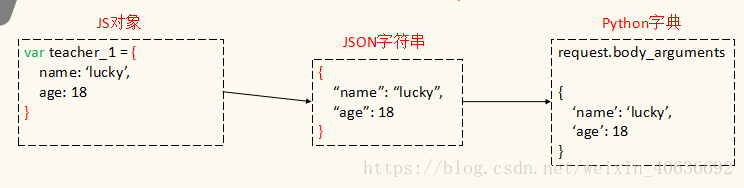
JSON注意事项:
(1)名称必须用双引号(即:””)来包括
(2)值可以是双引号包括的字符串、数字、true、false、null、JavaScript数组,或子对象
| ber | |
| True | true |
| False | false |
| None | null |
| 使用方法:在使用json这个模块前,首先要导入json库:import json | |
| 方法 | 描述 |
| json.dumps() | 将 Python 对象编码成 JSON 字符串 |
| json.loads() | 将已编码的 JSON 字符串解码为 Python 对象 |
| json.loads() | 将Python内置类型序列化为json对象后写入文件 |
| json.load() | 读取文件中json形式的字符串元素转化为Python类型 |
3. 针对目标检测yolo5的一份数据清洗过程
3.1数据实例格式分析
来源于数据集The Kvasir-SEG Dataset:
Kvasir-SEG Dataset Details
The Kvasir-SEG dataset (size 46.2 MB) contains 1000 polyp images and their corresponding ground truth from the Kvasir Dataset v2. The resolution of the images contained in Kvasir-SEG varies from 332x487 to 1920x1072 pixels. The images and its corresponding masks are stored in two separate folders with the same filename. The image files are encoded using JPEG compression, and online browsing is facilitated. The open-access dataset can be easily downloaded for research and educational purposes.
The bounding box (coordinate points) for the corresponding images are stored in a JSON file. This dataset is designed to push the state of the art solution for the polyp detection task.Some examples of the dataset.
3.2 数据格式转换过程
Kvasir_seg使用bbox标注,标注信息为json文件用记事本打开如图所示, 而yolov5训练所需要的文件格式是yolo(txt格式)的,查阅资料并没有找到可以将json转换成yolo可以直接使用的程序,而xml转成txt有博主写到了;所以这里需要考虑将json转换成txt文本,查找资料考虑先将json转换成xml格式,然后在对xml进行处理成txt后,输入yolo5进行训练。
3.2.1 json转xml
GNU General Public License v2.0 - GNU Project - Free Software Foundation
#首先定义一个dicttoxml函数
#!/usr/bin/env python
# coding: utf-8
"""
Converts a Python dictionary or other native data type into a valid XML string.
Supports item (`int`, `float`, `long`, `decimal.Decimal`, `bool`, `str`, `unicode`, `datetime`, `none` and other number-like objects) and collection (`list`, `set`, `tuple` and `dict`, as well as iterable and dict-like objects) data types, with arbitrary nesting for the collections. Items with a `datetime` type are converted to ISO format strings. Items with a `None` type become empty XML elements.
This module works with both Python 2 and 3.
"""
from __future__ import unicode_literals
__version__ = '1.7.4'
version = __version__
from random import randint
import collections
import numbers
import logging
from xml.dom.minidom import parseString
LOG = logging.getLogger("dicttoxml")
# python 3 doesn't have a unicode type
try:
unicode
except:
unicode = str
# python 3 doesn't have a long type
try:
long
except:
long = int
def set_debug(debug=True, filename='dicttoxml.log'):
if debug:
import datetime
print('Debug mode is on. Events are logged at: %s' % (filename))
logging.basicConfig(filename=filename, level=logging.INFO)
LOG.info('\nLogging session starts: %s' % (
str(datetime.datetime.today()))
)
else:
logging.basicConfig(level=logging.WARNING)
print('Debug mode is off.')
def unicode_me(something):
"""Converts strings with non-ASCII characters to unicode for LOG.
Python 3 doesn't have a `unicode()` function, so `unicode()` is an alias
for `str()`, but `str()` doesn't take a second argument, hence this kludge.
"""
try:
return unicode(something, 'utf-8')
except:
return unicode(something)
ids = [] # initialize list of unique ids
def make_id(element, start=100000, end=999999):
"""Returns a random integer"""
return '%s_%s' % (element, randint(start, end))
def get_unique_id(element):
"""Returns a unique id for a given element"""
this_id = make_id(element)
dup = True
while dup:
if this_id not in ids:
dup = False
ids.append(this_id)
else:
this_id = make_id(element)
return ids[-1]
def get_xml_type(val):
"""Returns the data type for the xml type attribute"""
if type(val).__name__ in ('str', 'unicode'):
return 'str'
if type(val).__name__ in ('int', 'long'):
return 'int'
if type(val).__name__ == 'float':
return 'float'
if type(val).__name__ == 'bool':
return 'bool'
if isinstance(val, numbers.Number):
return 'number'
if type(val).__name__ == 'NoneType':
return 'null'
if isinstance(val, dict):
return 'dict'
if isinstance(val, collections.Iterable):
return 'list'
return type(val).__name__
def escape_xml(s):
if type(s) in (str, unicode):
s = unicode_me(s) # avoid UnicodeDecodeError
s = s.replace('&', '&')
s = s.replace('"', '"')
s = s.replace('\'', ''')
s = s.replace('<', '<')
s = s.replace('>', '>')
return s
def make_attrstring(attr):
"""Returns an attribute string in the form key="val" """
attrstring = ' '.join(['%s="%s"' % (k, v) for k, v in attr.items()])
return '%s%s' % (' ' if attrstring != '' else '', attrstring)
def key_is_valid_xml(key):
"""Checks that a key is a valid XML name"""
LOG.info('Inside key_is_valid_xml(). Testing "%s"' % (unicode_me(key)))
test_xml = '<?xml version="1.0" encoding="UTF-8" ?><%s>foo</%s>' % (key, key)
try:
parseString(test_xml)
return True
except Exception: # minidom does not implement exceptions well
return False
def make_valid_xml_name(key, attr):
"""Tests an XML name and fixes it if invalid"""
LOG.info('Inside make_valid_xml_name(). Testing key "%s" with attr "%s"' % (
unicode_me(key), unicode_me(attr))
)
key = escape_xml(key)
attr = escape_xml(attr)
# pass through if key is already valid
if key_is_valid_xml(key):
return key, attr
# prepend a lowercase n if the key is numeric
if key.isdigit():
return 'n%s' % (key), attr
# replace spaces with underscores if that fixes the problem
if key_is_valid_xml(key.replace(' ', '_')):
return key.replace(' ', '_'), attr
# key is still invalid - move it into a name attribute
attr['name'] = key
key = 'key'
return key, attr
def wrap_cdata(s):
"""Wraps a string into CDATA sections"""
s = unicode_me(s).replace(']]>', ']]]]><![CDATA[>')
return '<![CDATA[' + s + ']]>'
def default_item_func(parent):
return 'item'
def convert(obj, ids, attr_type, item_func, cdata, parent='root'):
"""Routes the elements of an object to the right function to convert them
based on their data type"""
LOG.info('Inside convert(). obj type is: "%s", obj="%s"' % (type(obj).__name__, unicode_me(obj)))
item_name = item_func(parent)
if isinstance(obj, numbers.Number) or type(obj) in (str, unicode):
return convert_kv(item_name, obj, attr_type, cdata)
if hasattr(obj, 'isoformat'):
return convert_kv(item_name, obj.isoformat(), attr_type, cdata)
if type(obj) == bool:
return convert_bool(item_name, obj, attr_type, cdata)
if obj is None:
return convert_none(item_name, '', attr_type, cdata)
if isinstance(obj, dict):
return convert_dict(obj, ids, parent, attr_type, item_func, cdata)
if isinstance(obj, collections.Iterable):
return convert_list(obj, ids, parent, attr_type, item_func, cdata)
raise TypeError('Unsupported data type: %s (%s)' % (obj, type(obj).__name__))
def convert_dict(obj, ids, parent, attr_type, item_func, cdata):
"""Converts a dict into an XML string."""
LOG.info('Inside convert_dict(): obj type is: "%s", obj="%s"' % (
type(obj).__name__, unicode_me(obj))
)
output = []
addline = output.append
item_name = item_func(parent)
for key, val in obj.items():
LOG.info('Looping inside convert_dict(): key="%s", val="%s", type(val)="%s"' % (
unicode_me(key), unicode_me(val), type(val).__name__)
)
attr = {} if not ids else {'id': '%s' % (get_unique_id(parent)) }
key, attr = make_valid_xml_name(key, attr)
if isinstance(val, numbers.Number) or type(val) in (str, unicode):
addline(convert_kv(key, val, attr_type, attr, cdata))
elif hasattr(val, 'isoformat'): # datetime
addline(convert_kv(key, val.isoformat(), attr_type, attr, cdata))
elif type(val) == bool:
addline(convert_bool(key, val, attr_type, attr, cdata))
elif isinstance(val, dict):
if attr_type:
attr['type'] = get_xml_type(val)
addline('<%s%s>%s</%s>' % (
key, make_attrstring(attr),
convert_dict(val, ids, key, attr_type, item_func, cdata),
key
)
)
elif isinstance(val, collections.Iterable):
if attr_type:
attr['type'] = get_xml_type(val)
addline('<%s%s>%s</%s>' % (
key,
make_attrstring(attr),
convert_list(val, ids, key, attr_type, item_func, cdata),
key
)
)
elif val is None:
addline(convert_none(key, val, attr_type, attr, cdata))
else:
raise TypeError('Unsupported data type: %s (%s)' % (
val, type(val).__name__)
)
return ''.join(output)
def convert_list(items, ids, parent, attr_type, item_func, cdata):
"""Converts a list into an XML string."""
LOG.info('Inside convert_list()')
output = []
addline = output.append
item_name = item_func(parent)
if ids:
this_id = get_unique_id(parent)
for i, item in enumerate(items):
LOG.info('Looping inside convert_list(): item="%s", item_name="%s", type="%s"' % (
unicode_me(item), item_name, type(item).__name__)
)
attr = {} if not ids else { 'id': '%s_%s' % (this_id, i+1) }
if isinstance(item, numbers.Number) or type(item) in (str, unicode):
addline(convert_kv(item_name, item, attr_type, attr, cdata))
elif hasattr(item, 'isoformat'): # datetime
addline(convert_kv(item_name, item.isoformat(), attr_type, attr, cdata))
elif type(item) == bool:
addline(convert_bool(item_name, item, attr_type, attr, cdata))
elif isinstance(item, dict):
if not attr_type:
addline('<%s>%s</%s>' % (
item_name,
convert_dict(item, ids, parent, attr_type, item_func, cdata),
item_name,
)
)
else:
addline('<%s type="dict">%s</%s>' % (
item_name,
convert_dict(item, ids, parent, attr_type, item_func, cdata),
item_name,
)
)
elif isinstance(item, collections.Iterable):
if not attr_type:
addline('<%s %s>%s</%s>' % (
item_name, make_attrstring(attr),
convert_list(item, ids, item_name, attr_type, item_func, cdata),
item_name,
)
)
else:
addline('<%s type="list"%s>%s</%s>' % (
item_name, make_attrstring(attr),
convert_list(item, ids, item_name, attr_type, item_func, cdata),
item_name,
)
)
elif item is None:
addline(convert_none(item_name, None, attr_type, attr, cdata))
else:
raise TypeError('Unsupported data type: %s (%s)' % (
item, type(item).__name__)
)
return ''.join(output)
def convert_kv(key, val, attr_type, attr={}, cdata=False):
"""Converts a number or string into an XML element"""
LOG.info('Inside convert_kv(): key="%s", val="%s", type(val) is: "%s"' % (
unicode_me(key), unicode_me(val), type(val).__name__)
)
key, attr = make_valid_xml_name(key, attr)
if attr_type:
attr['type'] = get_xml_type(val)
attrstring = make_attrstring(attr)
return '<%s%s>%s</%s>' % (
key, attrstring,
wrap_cdata(val) if cdata == True else escape_xml(val),
key
)
def convert_bool(key, val, attr_type, attr={}, cdata=False):
"""Converts a boolean into an XML element"""
LOG.info('Inside convert_bool(): key="%s", val="%s", type(val) is: "%s"' % (
unicode_me(key), unicode_me(val), type(val).__name__)
)
key, attr = make_valid_xml_name(key, attr)
if attr_type:
attr['type'] = get_xml_type(val)
attrstring = make_attrstring(attr)
return '<%s%s>%s</%s>' % (key, attrstring, unicode(val).lower(), key)
def convert_none(key, val, attr_type, attr={}, cdata=False):
"""Converts a null value into an XML element"""
LOG.info('Inside convert_none(): key="%s"' % (unicode_me(key)))
key, attr = make_valid_xml_name(key, attr)
if attr_type:
attr['type'] = get_xml_type(val)
attrstring = make_attrstring(attr)
return '<%s%s></%s>' % (key, attrstring, key)
def dicttoxml(obj, root=True, custom_root='root', ids=False, attr_type=True,
item_func=default_item_func, cdata=False):
"""Converts a python object into XML.
Arguments:
- root specifies whether the output is wrapped in an XML root element
Default is True
- custom_root allows you to specify a custom root element.
Default is 'root'
- ids specifies whether elements get unique ids.
Default is False
- attr_type specifies whether elements get a data type attribute.
Default is True
- item_func specifies what function should generate the element name for
items in a list.
Default is 'item'
- cdata specifies whether string values should be wrapped in CDATA sections.
Default is False
"""
LOG.info('Inside dicttoxml(): type(obj) is: "%s", obj="%s"' % (type(obj).__name__, unicode_me(obj)))
output = []
addline = output.append
if root == True:
addline('<?xml version="1.0" encoding="UTF-8" ?>')
addline('<%s>%s</%s>' % (
custom_root,
convert(obj, ids, attr_type, item_func, cdata, parent=custom_root),
custom_root,
)
)
else:
addline(convert(obj, ids, attr_type, item_func, cdata, parent=''))
return ''.join(output).encode('utf-8')
*在调试代码的时候出现了红线,结果发现是使用了中文括号
定义完成后使用下面的代码:
import json
import urllib
import dicttoxml
#page = urllib.urlopen(r'D:\pythonProject1\json\annotation.json')
#print(page)
def load_josn(path):
lines = []
with open(path) as f:
for row in f.readlines():
if row.strip().startswith("//"):
continue
lines.append(row)
return json.loads("\n".join(lines))
if __name__ == "__main__":
obj = load_josn(r"D:\pythonProject1\json\annotation.json")
#print(obj)
xml = dicttoxml.dicttoxml(obj)
print(xml)*在使用转换代码的时候,因为需要导入json文件,所以采用了load_json(path)的方式进行导入(不同文件的加载方式不同,多查阅)。
转换后的XML文件:
<?xml version="1.0" encoding="UTF-8" ?><root>
<cju2ouil2mssu0993hvxsed6d type="dict"><width type="int">605</width>
<bbox type="list"><item type="dict"><xmin type="int">246</xmin><ymin type="int">243</ymin><ymax type="int">360</ymax><xmax type="int">361</xmax><label type="str">polyp</label></item></bbox><height type="int">511</height>
</cju2ouil2mssu0993hvxsed6d><cju5fs6j6d8350801vglraq4u type="dict"><width type="int">626</width><bbox type="list"><item type="dict"><xmin type="int">72</xmin><ymin type="int">146</ymin><ymax type="int">450</ymax><xmax type="int">415</xmax><label type="str">polyp</label></item></bbox><height type="int">547</height>
</cju5fs6j6d8350801vglraq4u><cju34sh43d8zm08019xbwhc0o type="dict"><width type="int">620</width><bbox type="list"><item type="dict"><xmin type="int">105</xmin><ymin type="int">206</ymin><ymax type="int">492</ymax><xmax type="int">332</xmax><label type="str">polyp</label></item></bbox><height type="int">530</height>
</cju34sh43d8zm08019xbwhc0o><cju422cm8lfxn0818ojicxejb type="dict"><width type="int">571</width><bbox type="list"><item type="dict"><xmin type="int">147</xmin><ymin type="int">346</ymin><ymax type="int">531</ymax><xmax type="int">376</xmax><label type="str">polyp</label></item></bbox><height type="int">531</height>3.2.2 xml标准化
用到上文那个实例,也就是这个博主的内容:(二)Python创建、修改、保存XML文件——xml.etree.ElementTree模块_Yale-曼陀罗-CSDN博客_python保存xml文件![]() https://blog.csdn.net/weixin_42782150/article/details/106219001
https://blog.csdn.net/weixin_42782150/article/details/106219001
先打开一个定义好的.xlm格式的模板文件,之后将TXT文件中的标注框信息逐行读入,用于修改xlm文件模板对应的指标数据,最后将修改后的新xlm文件写出保存。
- 原始数据;
- 模板文件:TXT文件数据的原始格式;
- 转换函数;
#encoding: utf-8
import copy
#from lxml import etree
#from lxml.etree import Element as ET
#from lxml.etree import Element, SubElement, tostring, ElementTree
import xml.etree.ElementTree as ET
import cv2
import os
# 模板xlm文件的存储路径
template_file = r'D:\pythonProject1\model.xml'
path = r'D:/pythonProject1/images/'
# TXT文件数据的原始格式
train_files = 'cju0roawvklrq0799vmjorwfv.jpg id12 1.3418148e+03, 6.2916492e+02, 1.4483580e+03, 9.2253162e+02, 6.3271374e-01'
trainFile = train_files.split() # trainFile存放全量的原始数据
#print('原始数据集格式:{}'.format(trainFile))
file_name = trainFile[0]
print(file_name)
# 定义新的xlm文件的详细指标数据
label = trainFile[1]
xmin = trainFile[2]
ymin = trainFile[3]
xmax = trainFile[4]
ymax = trainFile[5]
############# 读取模板xlm文件——用于存放TXT文件内容:
tree = ET.parse(template_file) # 调用parse()方法,返回解析树
root = tree.getroot() # 获取根节点
##########修改新的xlm文件的详细指标数据
# folder
root.find('folder').text = 'new_folders'
# 修改魔板xlm文件中的内容为目标结果
root.find('filename').text = file_name # 2.Element.find() :找到第一个带有特定标签的子元素。
# # path
root.find('path').text = path + file_name
# 查看部分修改结果
print(root.find('filename').text) # 第一层下每一项内容
print(root.find('path').text) # 第一层下每一项内容
print(root.find('size').find('height').text) # 查看第二层下每一项内容
print(root.find('object').find('bndbox').find('xmin').text) # 查看第三层下每一项内容
# size
imgpath = os.path.join(path, file_name)
sz = root.find('size')
im = cv2.imread(path + file_name) # 读取图片信息
sz.find('height').text = str(im.shape[0])
sz.find('width').text = str(im.shape[1])
sz.find('depth').text = str(im.shape[2])
print('iamge height:', im.shape[0])
print('iamge width:', im.shape[1])
print('iamge depth:', im.shape[2])
# object
obj = root.find('object')
obj.find('name').text = label
bb = obj.find('bndbox')
bb.find('xmin').text = xmin
bb.find('ymin').text = ymin
bb.find('xmax').text = xmax
bb.find('ymax').text = ymax
########## 校验修改后的root是否为新数据
root.find('object').find('bndbox').find('ymax').text
########## 保存新生成的xlm数据文件
tree = ET.ElementTree(root)
tree.write(r"D:\pythonProject1\99.xml")
*首先是使用命令这里,需要导入的包 cv2、xml
*在使用别人的程序的时候:
- 首先看环境;
- 在看环境相应的函数有没有变化;
- 再看环境下的包有没有导入进来,其次还要看导入进来后的函数有没有被定义成别的简称函数;
*debug的时候,要读懂代码,现在刚开始学习,要清楚每行代码的命令记载。
3.2.3 使用xml做成标准yolo标准数据集
接下来的内容就是目标检测---数据集格式转化及训练集和验证集划分_didiaopao的博客-CSDN博客














 2284
2284











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









