







吴恩达深度学习笔记——七、第三课第一周:机器学习策略
0 什么是机器学习(ML)策略
当我们训练一个机器学习算法时,可能会发现我们的学习器效果不够好,凭借我们现有的知识,可能会选择以下改进方法:

但是其中一些方法对当前学习器的性能提升是有用的,而更多的方法对当前学习器的性能提升并没有效果,我们要会判断哪个方法值得一试,哪些方法应该放弃。这一课十分重要,因为可以在将来做应用时节省大量时间。
1 正交化(Orthogonalize)
我们可以设计一个单独的维度,这一维度单独控制模型的一个性能,再设计另一个维度,单独控制模型的另一个性能,这样我们的模型会变得更加可控。例如汽车的控制中,方向盘单独控制angle,油门和刹车单独控制speed,如果我们设计一个有两个按钮的手柄,两个按钮的控制效果如下图所示:
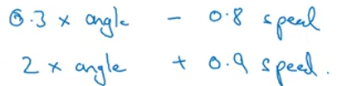
虽然我们也可以实现对汽车的控制,但是这显然控制起来很复杂,这也就是正交化的目的,AI大佬往往正交化能力很强。
ML策略往往有四步:
- 在训练集上达到较高的性能(目标性能往往期望和人一样好)
- 在开发集上达到较高的性能
- 在测试集上达到较高的性能
- 在real world上达到较高的性能
我们在以上四步都应该有一组旋钮knob可以单独调节学习模型在不同数据集上的表现
2 评估指标
2.1 单一实数评估指标
要为模型设定一个单实数评估指标,这样可以很方便的查看修改某一参数时模型是变好了还是变差了
我们通常评估学习器有两个指标:
- 查准率P:找出的分类为猫猫的图片中是真正的猫猫的图片比例有多高
- 找回率R:数据集中所有猫猫图片有百分之多少被找出来了
这两个指标相互制约,同时我们希望用一个指标来衡量——F1:P和R的调和平均值

2.2 满足和优化指标(Satisficing and optimizing metrics)
有时候变成一个指标比较困难,我们往往使用满足和优化指标
satisficing指标:比如有“运行时间”,我们一般只希望运行时间别超过我们用户的容忍值即可。
optimizing指标:比如有“查准度”,我们希望这个指标越高越好。
当我们面对N个指标时,我们一般取一个为optimizing指标,其他的都定为satisficing指标
3 训练集、开发集、测试集的划分
3.1 划分比例与划分原则
ps:开发集(dev set/ development set)又称为保留交叉验证集(hold out cross vaildation set)
如果我们有一个模型要在全球进行验证,那么我们的开发集和测试集一定要有相同的分布。
Choose a dev set and test set to reflect data you expect to get in the future and consider important to do well on
早期的机器学习中,可以这样划分数据集:

现今的深度学习,这样划分比较合理:
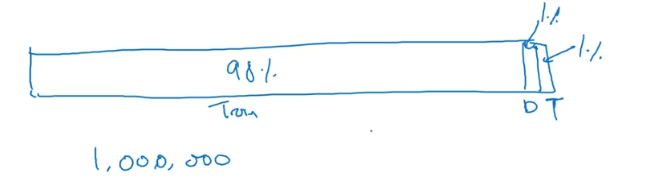
因为数据集大得很,1%就满足测试集的要求了。

3.2 什么时候改变开发测试集指标
举一个例子:我们有两个猫猫图片分类模型,A的误分类率为3%,B的误分类率为5%,但是A会把涩图分类为猫猫推荐给用户,这种错误显然不能容忍,所以我们在评价分类器指标时加一个权重w:
也就是说我们如果对旧指标不满意,那么就不要再用了,要定义一个适合自己的新指标。
4 人的表现和避免偏差
在分类问题中有一个贝叶斯误差,这是所有分类器(包括人类自己)的理论最优误差上限,除非过拟合,否则无论如何都不能使分类器误差低于这个值。

4.1 human level performance
我们一般把一组对该问题最有经验的专家一起做决策的分类错误率作为human level performance

当一个学习器的错误率低于1%时,那么它就有部署的意义了。
在上上张图片中可得,我们如何去估计贝叶斯误差在较困难的分类任务中很重要,比如在嘈杂环境中做语音识别,我们不可能让偏差降低到0,我们应该让训练集误差与贝叶斯误差比较,判断是否有继续优化算法以降低偏差的必要,而贝叶斯误差可以用human level performance近似估计。
以下为优化策略:















 723
723











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









