







看到就要学习的小事项:
磁盘查询数据的速度的限制,除了寻址的时间限制,还有就是磁盘也有带宽的限制,所以当一个高并发的查询到达数据库,就算有索引为什么还是慢,其实也是被磁盘的带宽限制了,当一部分并发充满了磁盘的带宽,其他线程就只能等待了。
数据库的排名:DB-Engines - Knowledge Base of Relational and NoSQL Database Management Systems
安装redis
略
epoll的发展
(1).最开始的网络模型为阻塞的方式,也就是一个socket就使用一个线程来读取数据,如果没有数据这个线程就一直在read处阻塞住
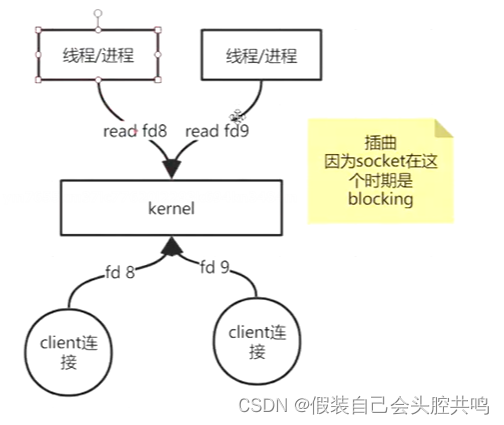
弊端:一个线程负责一个连接,造成资源的浪费,在阻塞的时候线程什么也不做
(2) 后来read方法变为了非阻塞的方法,多线程的方式就被取代了,循环所有的socket询问是否有数据进来了
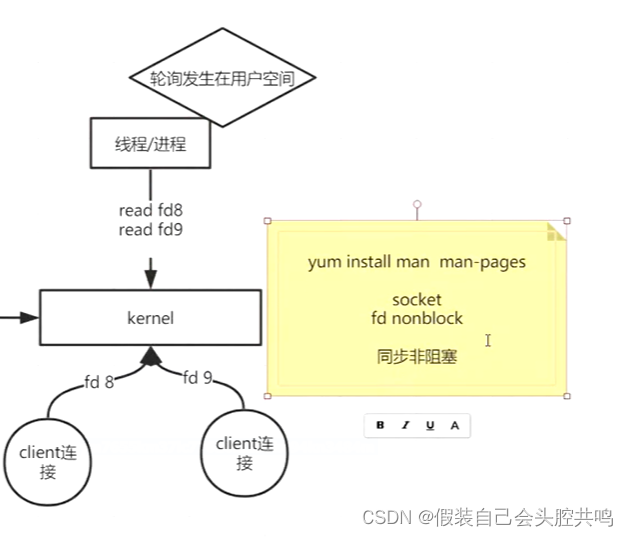
弊端:每一次询问的结果都是从用户态到内核态的一次切换,而且每次会把所有的socket进行一次循环,如果这时候客户端没有发来数据,那么这次询问将是无意义的
(3) 再后来select函数出现了,这个函数完全是在内核当中,将收到数据的socket返回给用户,
这样用户再去read的时候,这样用户就不会有无意义的用户态到内核态的切换
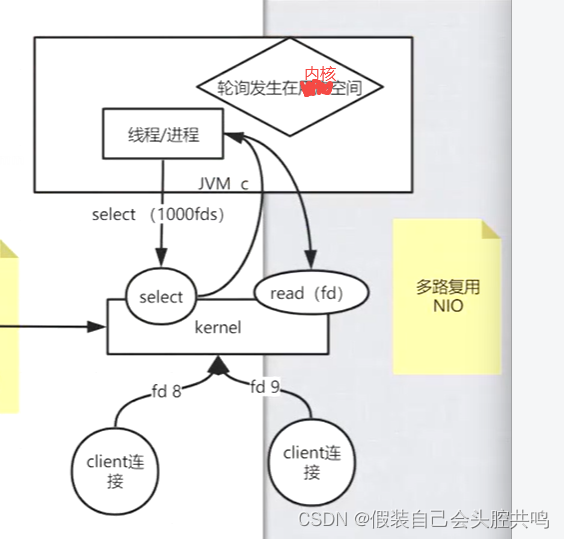
弊端:所有的socket其实在用户态和内核态来回传递
(4)为了解决上面的弊端就出现了epoll,出现了一个用户态和内核态的共享空间mmap
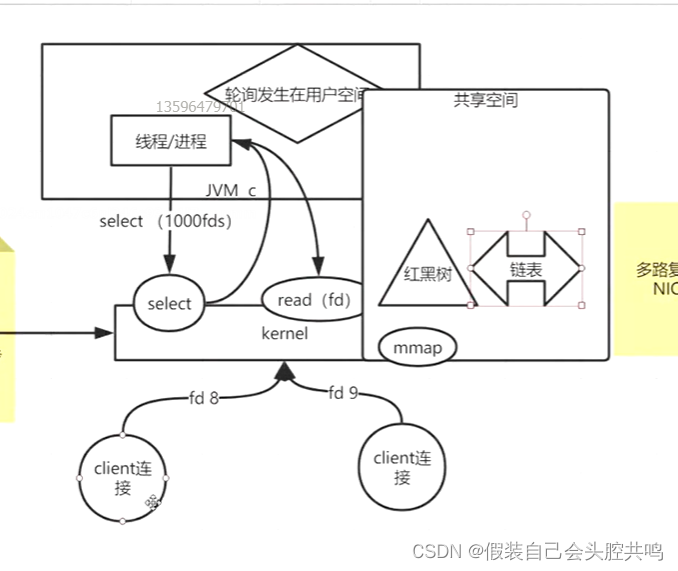
epoll的执行流程就是,当用户态产生了这些sokcet之后,就会放入共享空间mmap,然后epoll函数就开始不断监听共享空间的socket是否有数据进来了,如果有,就放入链表当中,供用户空间的线程去调用,这样就使用一个共享空间避免了,数据在用户态和内核态之间的传递
redis一些常用的命令:
1.通过这个命令 help @generic 查看redis常用的基本命令 ,下同并且按Tab可以切换
help @string
2. 通过这个命令 type 可以查看一个key的类型
二进制安全
redis在存储字符串的时候其实本质是存储的字节,比如说如果客户端的字符集编码是UTF-8
那么redis 存储的中文就是,三个字节,如果字符集编码是 GBK那么中文就是两个字节,这个时候
如果不设置 --raw 在get一个中文的时候只能取出字节的16进制表达形式,如果设置了将按照客户端的字符集来展示存入的中文,当然存入英文和数字的时候,就是一个字符一个字节了
类似 set a 999
strlen a
就得到3
String类型
1.字符串 基本的操作不写了,按照范围取值,按照范围替换
不存在的时候才设置(set k1 ooxx nx) ,存在的时候才设置(set k2 hello xx)
设置新值,并且返回老值 GETSET
2.数值 自增1 自减1 增加指定数字 减去指定数字 增加指定小数
3.位图 设置名称为k1的位图第七个下标为1 setbit k1 7 1
bitpos 在指定的8位数字当中找到 是否含有这个数字,然后返回下标
bitpos k1 1 0 0,在k1当中找 1 从第0个byte开始到第0个byte结束
bitcount k1 0 1 在0到1这个字节区间内 1 出现了几次
bitop and andkey k1 k2 与或非操作 and就是与的操作 andkey就是目标key
字符集 :
1.ascii 就八位 0XXX XXXX
2.其他都叫扩展字符集,不对ascii做改变只做补充
两个位图使用的例子:
1.在随机时间范围内,用户是否登录,登录过几次?
以用户id为key,然后建立位图,位图的第一位就是第一天,如果登录了 就变为1
2.在随机时间范围内,判断用户是否为活跃用户,只要登录过就算活跃用户
以时间为key,用户id为位图索引下标,只要用户登录过,用户id指定的索引下标就变为1
然后把位图进行或运算,是1的就是活跃用户
List类型:
1.list 这个类型根据命令的调用不同,既可以实现栈也可以实现队列,阻塞队列
还可以实现数组也就是根据下标进行操作(甚至可以实现在指定的位置之前插入数据)
注意:这个阻塞队列其实是一个单播的队列,也就是如果十个客户端,都因为这个阻塞队列没有数据被阻塞了,当队列有数据之后,只有一个客户端可以拿到队列里面的数据
Hash类型:
1.其实就是把 java当中的hashmap作为value 只有一个map 不是map集合
2.hash类型当中的int 就像string一样可以进行计算的
set类型:
跟list的区别在于:set是不可以有重复的,list是可以有重复的,并且set是乱序的
1.并且可以做交集,并集,差集
2.随机事件 用于抽奖
sortset类型:
有序的set,但是用什么来决定排序?
1.使用score来决定排序顺序,当然score分数相同的时候,是按照名称的字典序来排的















 3310
3310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









