






🔥AI时代,你焦虑了吗?
铺天盖地的AI新闻,各种神奇的AI应用...你是不是感觉自己快要被时代抛弃了?
* “AI取代人类”的论调甚嚣尘上,你是否担心自己的饭碗不保?
* 眼花缭乱的AI工具,你是否感觉无从下手,学不过来?
* 只会机械地调Prompt,你是否渴望真正理解AI的“黑盒子”?
别慌!今天,我们就来一起“拆解”大模型,深入它的“大脑”,看看它到底是怎么思考的!🚀

😱大模型,真有那么神吗?
我们天天都在说“大模型”,但它到底是个啥?
简单来说,大模型就是一个巨大的神经网络,它通过学习海量的文本数据,学会了理解和生成人类语言。
但这背后,是极其复杂的数学和算法。如果你只是停留在“调Prompt”的层面,永远无法真正驾驭AI!
🤔️为什么我们要“拆解”大模型?
* 知其然,更要知其所以然: 只有深入理解大模型的工作原理,才能更好地利用它,而不是被它“牵着鼻子走”。
* 告别焦虑,掌控未来: 了解AI的本质,才能消除对未知的恐惧,在AI时代立于不败之地。
* 进阶AI高手: 从“调参侠”进阶为真正的AI工程师,甚至开发自己的AI应用!
🛠️手把手,带你“拆解”Qwen2大模型!
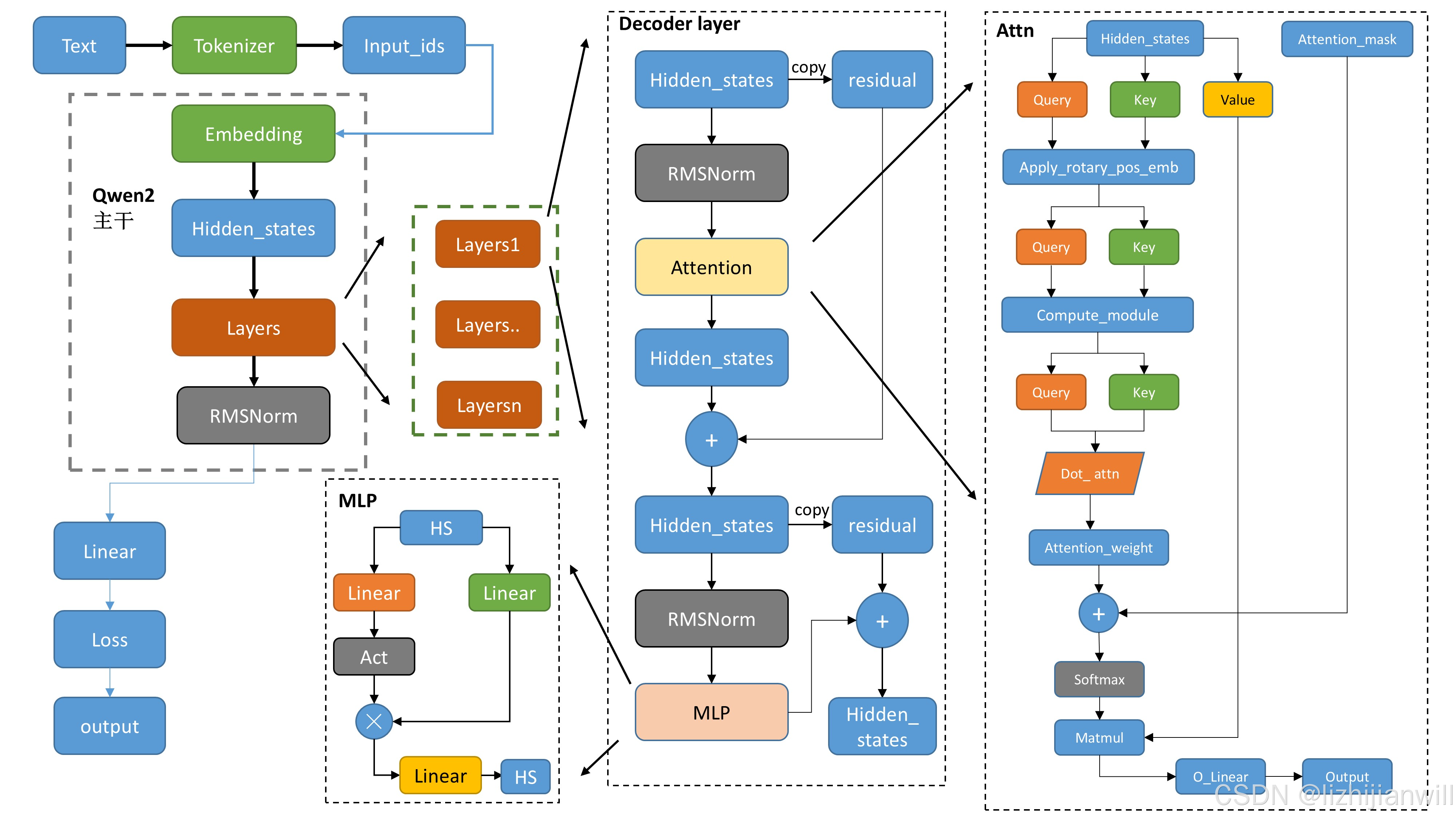
理论说再多,不如动手实践!
下面,我们就以Qwen2为例,用Python代码一步步拆解它的内部结构,让你亲眼看看大模型是如何运作的!(代码已简化,方便理解)
from transformers.models.qwen2 import Qwen2Config, Qwen2Model
import torch
def run_qwen2():
# 1. 配置模型参数:就像搭积木,先准备好各种“零件”
qwen2_config = Qwen2Config(
vocab_size=151936, # 词汇表大小:模型认识多少个“词”
hidden_size=4096 // 2, # 隐藏层维度:模型“大脑”的容量
intermediate_size=22016 // 2, # 中间层维度:影响模型的“思考”能力
num_hidden_layers=32 // 2, # Transformer层数:模型“思考”的深度
num_attention_heads=32, # 注意力头数:模型“关注”信息的角度
hidden_dim=2048 // 32, # 每个注意力头的维度
max_position_embeddings=2048 // 2 # 模型支持的最大序列长度:模型能“看”多长的句子
)
# 2. 初始化模型:把“零件”组装起来
qwen2_model = Qwen2Model(config=qwen2_config)
# 3. 准备输入:给模型一个“问题”
# 随机生成一个输入序列,模拟用户输入的一段话
input_ids = torch.randint(0, qwen2_config.vocab_size, (4, 30))
# 4. 模型推理:让模型“思考”
res = qwen2_model(input_ids)
# 5. 查看结果:看看模型“回答”了什么
print(type(res))
if __name__ == '__main__':
run_qwen2()
🤓代码解读,深入理解每一步!
* `Qwen2Config`: 模型的“配置文件”,定义了模型的各种参数。这些参数决定了模型的规模、能力和特性。
* `Qwen2Model`: 模型的“主体”,根据配置文件构建。
* `input_ids`: 模型的“输入”,是一串数字,代表一句话中的每个字或词。
* `res`: 模型的“输出”,包含了模型对输入的理解和生成的文本。
💡核心概念,一次搞懂!
* 词汇表(vocab_size): 模型能识别的所有字或词的集合。
* 隐藏层(hidden_size): 模型内部的“神经元”,数量越多,模型越强大。
* Transformer层数(num_hidden_layers): 模型“思考”的深度,层数越多,模型越复杂。
* 注意力机制(num_attention_heads): 模型“关注”输入信息的方式,多头注意力可以让模型从不同角度理解信息。

✨举一反三,触类旁通!
这段代码虽然是针对Qwen2模型的,但其核心思想适用于所有基于Transformer架构的大模型,如GPT、LLaMA等。
只要你理解了这段代码,就等于掌握了打开大模型“黑盒子”的钥匙!🔑
🚀AI时代,拒绝焦虑,拥抱未来!
与其担心被AI淘汰,不如主动学习,掌握AI!
从今天开始,告别“调参侠”,成为真正的AI高手!💪
💬互动时间:
* 你对AI的未来有什么看法?
* 你还想了解哪些关于大模型的知识?
* 你认为学习AI最重要的是什么?
欢迎在评论区留言分享你的观点!
📌温馨提示:
1. 强烈建议读者复制代码亲自运行感受下!
2. 请关注本公众号后续文章,持续深入学习和交流!
3. 别忘了分享给你的朋友,一起学习,共同进步!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









