






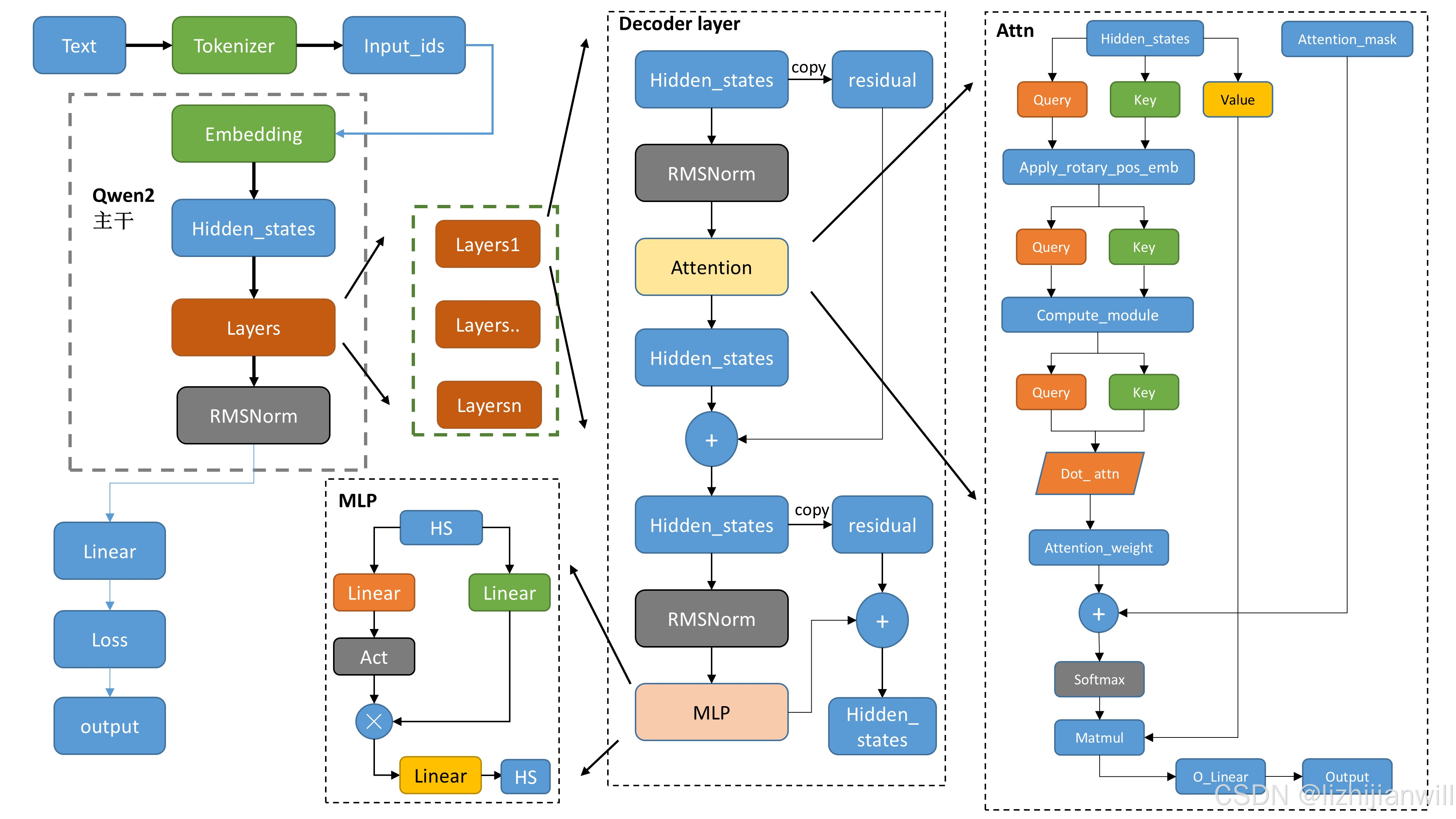
我们把 Qwen2 模型想象成一个非常聪明的“阅读理解专家”。 这个专家,就像我们人类一样,需要先“看”到文字,然后才能理解文字的意思,最后才能回答问题或者生成新的文字。
深入理解之运行代码:
from transformers.models.qwen2 import Qwen2Config, Qwen2Model
import torch
def run_qwen2():
# 根据模型需求配置参数,构造 Qwen2 模型的配置对象
qwen2_config = Qwen2Config(
vocab_size=151936, # 词汇表大小,即模型可识别的 token 数量
hidden_size=4096 // 2, # 隐藏层的维度,这里使用 4096 的一半(2048)
intermediate_size=22016 // 2, # 中间层(Feed-Forward 层)的维度,这里取 22016 的一半
num_hidden_layers=32 // 2, # Transformer 的层数(encoder 层数),这里使用 32 的一半
num_attention_heads=32, # 每层的注意力头数
hidden_dim=2048 // 32, # 注意力中每个头的维度,2048 除以 32 得到 64
max_position_embeddings=2048 // 2 # 模型支持的最大序列长度,这里取 2048 的一半
)
# 根据配置初始化 Qwen2 模型
qwen2_model = Qwen2Model(config=qwen2_config)
# 随机生成一个输入序列(这里生成的张量形状为 (batch_size, sequence_length))
# 使用 torch.randint 生成随机的 token id,范围在 [0, vocab_size) 内
input_ids = torch.randint(0, qwen2_config.vocab_size, (4, 30))
# 将输入传入模型,得到输出结果
res = qwen2_model(input_ids)
# 打印输出结果的类型,便于调试或了解模型返回的数据结构
print(type(res))
if __name__ == '__main__':
run_qwen2()1. “文本 (Text)” - 书本内容:
- 比喻: “文本”就像是你递给这位“阅读理解专家”的一本书。这本书里写满了文字,可能是一个故事,也可能是一些问题。
- 例子: “今天天气真好!” 或者 “请问北京是中国的首都吗?” 这些都是“文本”。
2. “分词器 (Tokenizer)” - 书本目录:
- 比喻: “分词器”就像是这本书的“目录”。 目录不会直接告诉你书的内容,但是它会把书分解成一个个章节、段落、甚至更小的“知识点”(词语),并且给每个“知识点”编上号码,方便专家快速查找和索引。
- 例子: “今天天气真好!” 经过“分词器”处理后,可能会变成 [“今天”, “天气”, “真”, “好”, “!”] 这样一个“词语列表”,并且每个词语会被转换成一个数字,例如 [123, 456, 789, 101, 202]。 这些数字就是 “输入 IDs (Input_ids)”。
3. “输入 IDs (Input_ids)” - 目录页码:
- 比喻: “输入 IDs” 就像是“目录”中每个“知识点”对应的“页码”。 专家拿到这些页码,就知道要去书的哪个地方查找相关的“知识点”。
- 例子: 数字 [123, 456, 789, 101, 202] 就是“输入 IDs”,它们代表了 “今天”、“天气”、“真”、“好”、“!” 这几个词在模型“词汇表”中的位置。
4. “嵌入层 (Embedding)” - 知识索引卡片:
- 比喻: “嵌入层” 就像是专家为每个“知识点”(词语)准备的“索引卡片”。 每张卡片上都记录着这个词语的各种“特征”或者“属性”,比如这个词语的意思、用法、和其他词语的关联等等。 这些“特征”用数字来表示,就像是词语的“DNA”。
- 例子: 对于“今天”这个词,它的“索引卡片”上可能记录着: [0.5, -0.2, 0.8, ..., 0.1] 这样一串数字。 这串数字就是 “隐藏状态 (Hidden_states)” 的最初形态,它代表了“今天”这个词的“向量表示”。
5. “Qwen2 主干” 和 “Decoder 层 (Decoder layer)” - 思考层层递进:
- 比喻: “Qwen2 主干” 就像是这位“阅读理解专家”的大脑核心,由很多层“思考层 (Decoder layer)” 堆叠而成。 每一层“思考层”都会从“索引卡片”(Hidden_states)中提取信息,并进行更深层次的理解和分析。 就像盖房子一样,一层一层地往上搭建,每一层都在前一层的基础上,进行更精细的加工。
6. “注意力机制 (Attn)” - 聚精会神地“看”重点:
- 比喻: 在每一层“思考层”中,都有一个“注意力机制”。 “注意力机制”就像是专家“聚精会神”地阅读书本,它会判断哪些“知识点”是重要的,哪些是不太重要的。 对于重要的“知识点”,它会投入更多的“注意力”,就像用“荧光笔”在书上标记重点一样。
- 例子: 在理解句子 “今天天气真好!” 时,“注意力机制”可能会发现 “天气” 和 “好” 这两个词更重要,因为它们直接关系到句子的情感倾向,所以会给予它们更高的“注意力”。
7. “多层感知机 (MLP)” - “推理”和“加工”信息:
- 比喻: 在“注意力机制”之后,信息会传递给“多层感知机 (MLP)”。 “MLP” 就像是专家的“推理中心”,它会基于“注意力机制”关注的重点,进一步“推理”和“加工”信息,提取更复杂的特征。 就像专家在标记重点后,会进一步思考这些重点之间的联系,从而更深入地理解书本内容。
8. “残差连接 (residual)” - “记忆”和“传承”信息:
- 比喻: “残差连接” 就像是专家在每一层“思考”过程中做的“笔记”或者“草稿”。 每一层“思考层”的输出,会有一部分“原始信息”(之前的“思考笔记”)被“记住”并“传承”到下一层,避免信息在层层传递中丢失。 这样可以确保模型更有效地利用之前层级的思考成果。
9. “RMSNorm” (或者 “LayerNorm”) - “调整”信息尺度:
- 比喻: “RMSNorm” 就像是专家在“思考”过程中,会不断“调整”信息的“尺度”或者“音量”。 它可以让不同来源的信息(比如来自“注意力机制”和“MLP”的信息)保持在相似的数值范围,避免某些信息“声音太大”盖过其他信息,从而让模型更稳定地学习。
10. “线性层 (Linear)” - “转换”信息形态:
- 比喻: “线性层” 就像是专家手中的“变形工具”,它可以把信息的“形态”进行“转换”。 比如,它可以把“思考”结果从一种“向量”形态,转换成另一种“向量”形态,以便于后续的 “思考” 或者最终的 “输出”。
11. “输出 (output)” - 最终的“理解”成果:
- 比喻: 经过 “Qwen2 主干” 中所有“思考层”的层层处理,最后就得到了 “输出 (output)”。 “输出” 就像是这位 “阅读理解专家” 最终的 “理解成果”,可能是对问题的 “答案”,也可能是 “新生成的文字”(例如,续写故事、翻译等)。
12. “损失函数 (Loss)” - “打分”和“改进”:
- 比喻: “损失函数 (Loss)” 只有在模型 “学习”(训练)的时候才会用到。 它就像是给专家的 “理解成果” 进行 “打分” 的老师。 老师会比较专家的 “答案” 和 “标准答案”,然后给出一个 “分数”(Loss 值)。 如果分数不高,就说明专家理解得还不够好,需要 “改进”(调整模型参数),争取下次做得更好。
总结比喻:
整个 Qwen2 模型就像一个 高度智能的“阅读理解专家”。 它通过:
- “分词器” 把书本 (文本) 分解成目录 (输入 IDs)。
- “嵌入层” 为目录 (输入 IDs) 制作知识索引卡片 (Hidden_states)。
- “Qwen2 主干” 里的多层 “思考层” (Decoder layer) 像专家的大脑一样,层层递进地理解书本内容。
- 每个 “思考层” 中的 “注意力机制” 像聚精会神地看重点,“多层感知机” 像推理和加工信息,“残差连接” 像记忆和传承信息, “RMSNorm” 像调整信息尺度, “线性层” 像转换信息形态。
- 最终 “输出” 就是专家对书本内容的 “理解成果” (答案或者新生成的文字)。
- “损失函数” 则像老师一样,帮助专家不断 “学习” 和 “改进”。
代码和架构图的联系:
Python 代码,就是在 用程序的方式,搭建和运行这样一个 “阅读理解专家” 模型。
Qwen2Config(...)就像是 设计图纸,定义了专家的“大脑”有多大(例如有多少层思考层),每个“思考层”有多复杂等等。Qwen2Model(config=qwen2_config)就像是 根据图纸建造出这个 “阅读理解专家”。input_ids = torch.randint(...)就像是 准备了一堆随机的 “目录页码” 给专家。res = qwen2_model(input_ids)就像是 让专家根据 “目录页码” 去 “阅读理解” 并给出 “理解成果” (结果保存在res变量中)。res = qwen2_model(input_ids) 就像是 让专家根据 “目录页码” 去 “阅读理解” 并给出 “理解成果” (结果保存在 res 变量中)。print(type(res))只是 让你看看专家的 “理解成果” 是什么类型的 (例如,是一段文字还是一些数字)。

















 179
179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









