







linux grep命令浅析
首先理解一下grep的字面意思
grep (global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
grep命令主要配合正则表达式使用
先理解记忆一下grep的几个参数
-i 忽略大小写进行检索
-v 反向搜索文件内容
-n 将搜索出来的内容按行显示
grep语法结构:grep -参数+搜索信息+路径
grep的另类应用
通过文件内容反向确定其在目录下的哪个文件
确定文件内容在哪个子目录下的哪个文件
创建环境
查找lizhiming在哪个子目录哪个文件里



grep和正则表达式的结合
创建环境

基础正则的使用:
①[] 匹配括号内的多个字符信息
例如搜索文件中的food和fold 此时就可以用fo[ol]d 表示搜索food和fold

②^表示匹配以什么开头的信息,但是当 ^在[]括号内的时候就不一样了,此时 ^代表反向选择。比如我要搜索如果想要搜索到有 oo 的行,但不想要 oo 前面有 g

此时可以看到7,8行也显示出来了,这显然不符合我的搜索条件,7行出来是因为后边的tool符合搜索条件,8行是因为oo前边的是o所以才显示出来。
同时还可以用来筛选数列

此处的重点就是区别尖角在[]内和外的意义
③ 行首与行尾定位符^$
这里特别注意的就是定位行尾是.结尾的方法

此时如果不加\的话就会出现这个情况

注意了:因为. 在正则中表示任意一个字符且只一个字符所以他就会去匹配其他的字符,这里加上转义字符\相当于将.转义为就是点的意思。
还得解释一下.的任意一个且只代表一个字符
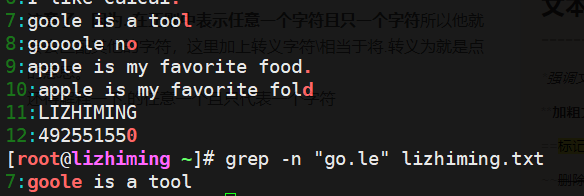
这里只搜索出来了第七行而第八行没有显示,因为goooole中go后边有三个o所以不再去匹配

④*代表匹配前面一个字符出现0次或者多次

此时的匹配结果需要注意了啊小哥哥
首先匹配出来显示o的行可以理解,其次就是2,4,6,11,12行它们并没有字母o 那为什么还会匹配出来呢,那是因为*还有匹配0次的意思

此处第一次输入 g*g 出现的结果是因为其识别成了g后匹配g出现0次才匹配到的这些
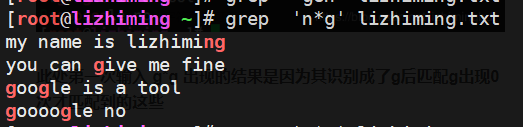
此处加深理解第一行匹配的是n出现一次后边接g
后边匹配的都是n出现0次的ng
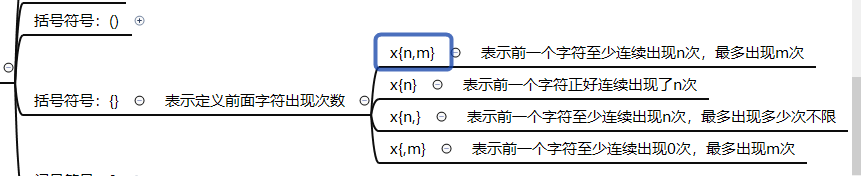
⑤在上边可以用. 和*实现两个字符中间接0个字符或者多个字符的查找,那么如果要实现查找两个字符中指定字符次数的查找就需要用到{}
{} 表示前面字符出现的次数
使用扩展正则egrep
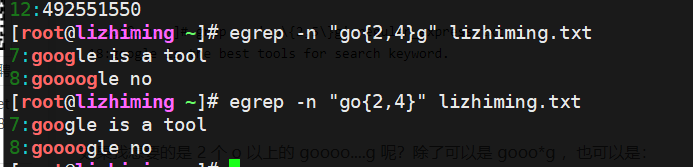
查找文件中o出现两次的行

这里注意;如果使用正则则需要在花括号前后加转义字符

理解一下这个
⑥ 扩展正则的?和 +区别 首先?表示前边的字符出现0次或一次以上
+表示前边的字符出现一次或者一次以上
错误示范

第一次输入出现的错误是没有加\对.进行转义
第二次出现错误是因为[]和.?之间有空格
正确检索出文本中含有小数点的信息,如果是检索小数点后一位

如果检索小数点出现0次或者一次则需要这样操作

前边的492551550出现是因为其中小数点出现了0次
所以也符合搜索条件
如果需要检索小数点后两位,则需要一下操作

联系到前边数列{}的表达式 可以将这个命令简化为

同理可以推出小数点后三位的表达式
















 408
408











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









