







1.现象
Mafka线上为某个业务搭建的集群,隔几天就会偶尔出现如下报警:
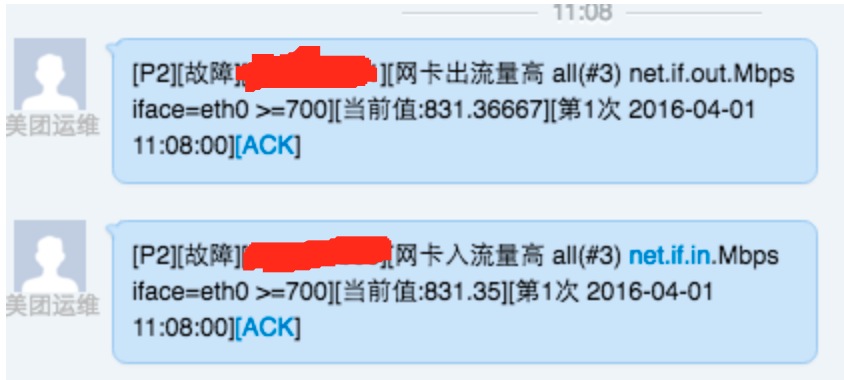
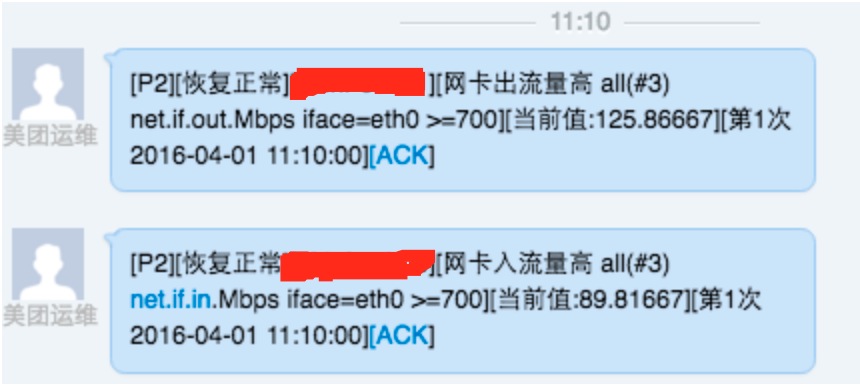
每次报警均是一个网卡出流量高,一个网卡入流量高(目前设置的阈值是700Mb),而且一般在5分钟左右的时间内故障就会自动恢复:
2.原因分析
简单描述:kafka 0.8 的读写锁bug,写的地方加锁了,读的地方未加锁。
具体展现:副本去请求数据的时候,出现请求的offset超出leader partitiond范围,从而认为副本出错,于是删除副本数据,从leader partition重新同步一份数据过来。
目前我们对业务设置的单partition最大存储数据量是20G,这个再同步的时候,leader和replica的磁盘都处于高I/O状态,所以出现报警,数据拉取完毕后,报警解除。
2.1 具体分析
其他博友有些相关分析:http://m.blog.csdn.net/article/details?id=51025141。
那为什么会出现这个原因呢?
leader partition在append消息的时候会做两件事情:
1. Append message to log
2. Update Log.nextOffsetMetadata.messageOffset.
如果一个replica在1和2这个过程中发生两次fetch,那么就会出现range exception,一旦发生range exception,就会执行handleOffsetOutOfRange逻辑,就会删除[topic、parition]
的所有数据,然后就需要重新拉取所有的现存数据了,一旦数据量较大,就引发网卡打爆问题。
3.解决方案
以下两种中可选择一种来解决:
1、fix 当前0.8版本的这个bug:
具体patch见:https://github.com/uber/kafka/commit/d01c7db19923d936a6177cd0a57e35f594eab9ec
2、0.9.0版本已经修复这个问题,升级broker版本到0.9.x。
4.官方task
https://issues.apache.org/jira/browse/KAFKA-2477
主要引用自涂扬wiki















 6268
6268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









