






目录
是什么
mask矩阵是什么?是一个由0和1组成的矩阵(其中mask矩阵中1代表真实数据;0代表padding数据。)。一个例子是,在自然语言处理(NLP)中,句子的长度是不等长的,但因为我们经常将句子组成mini-batch用以训练,因此那些长度较短的句子都会在句尾进行填充0,也即padding的操作。一个mask矩阵即用以指示哪些是真正的数据,哪些是padding。如:
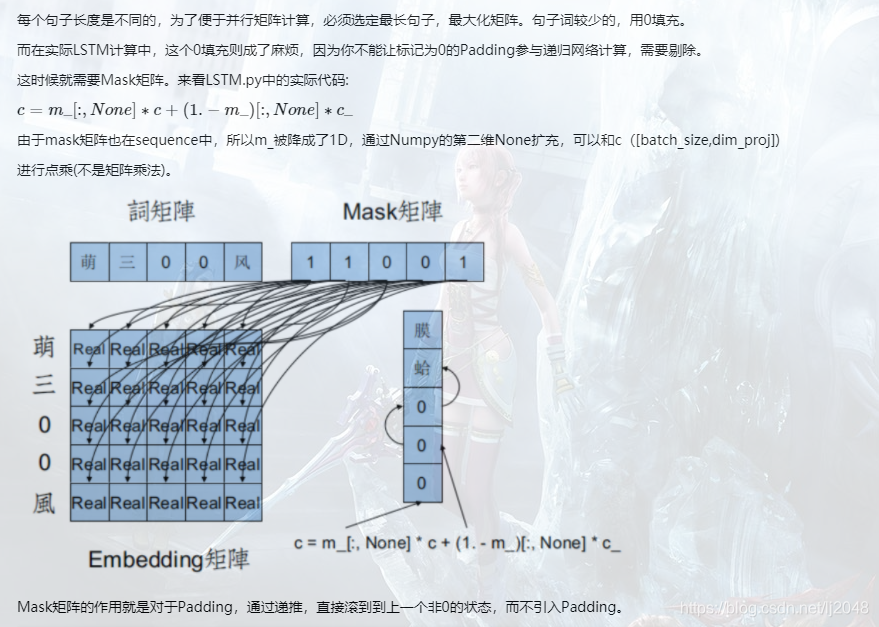
图片来源:Theano:LSTM源码解析
补充
- 矩阵的掩膜操作根据掩膜重新计算每个像素的像素值
- 掩膜的定义
- 用选定的图像、图形或物体,对处理的图像(全部或局部)进行遮挡,来控制图像处理的区域或处理过程。用于覆盖的特定图像或物体称为掩模或模板。光学图像处理中,掩模可以是胶片、滤光片等。数字图像处理中,掩模为二维矩阵数组,有时也用多值图像。
- 数字图像处理中,图像掩模主要用于:
-
提取感兴趣区,用预先制作的感兴趣区掩模与待处理图像相乘,得到感兴趣区图像,感兴趣区内图像值保持不变,而区外图像值都为0。
-
掩膜是一种图像滤镜的模板,实用掩膜经常处理的是遥感图像。当提取道路或者河流,或者房屋时,通过一个n*n的矩阵来对图像进行像素过滤,然后将我们需要的地物或者标志突出显示出来。这个矩阵就是一种掩膜。
-
屏蔽作用,用掩模对图像上某些区域作屏蔽,使其不参加处理或不参加处理参数的计算,或仅对屏蔽区作处理或统计。
-
结构特征提取,用相似性变量或图像匹配方法检测和提取图像中与掩模相似的结构特征。
-
特殊形状图像的制作。
-
实现图像对比度调整
为什么
为什么要使用mask矩阵?使用mask矩阵是为了让那些被mask掉的tensor不会被更新。考虑一个tensor T的size(a,b),同样大小的mask矩阵M,相乘后,在反向回传的时候在T对应mask为0的地方,0的梯度仍为0。因此不会被更新。
怎么做
接下来介绍几种(可能不全)使用mask的场景。
对输入进行mask
考虑NLP中常见的句子不等长的情况。设我们的输入的batch I:(batch_size,max_seqlen),我们在过一层Embedding层之前,
在过了一层Embedding层,则有 E:(batch_size,max_seqlen,embed_dim),如果我们希望Embedding是更新的(比如我们的Embedding是随机初始化的,那当然Embedding需要更新),但我们又不希望padding更新。
一种方法即令E与M相乘。其中M是mask矩阵(batch_size,max_seqlen,1) (1是因为要broadcast),这样在Embedding更新梯度时,因为mask矩阵的关系,padding位置上的梯度就是0。
当然在Pytorch中还可以直接显式地写:
1 | self.embedding = nn.Embedding(vocab_size, embed_dim,padding_idx=0) |
而此时应当将padding显式添加到词典的第一个。
对模型中间进行mask
一个很经典的场景就是dropout。
对于参数矩阵W:(h,w),同样大小的mask矩阵M,在前向传播时令W’=W*M,则在反向传播时,M中为0的部分不被更新。
当然,我们可以直接调用PyTorch中的包nn.Dropout()
1 2 3 | m = nn.Dropout(p=0.2) input = torch.randn(20, 16) output = m(input) |
对loss进行mask
考虑NLP中的language model,每个词都需要预测下一个词,在一个batch中句子总是有长有短,对于一个短句,此时在计算loss的时候,会出现这样的场景:<pad>词要预测下一个<pad>词。举个例子:三个句子[a,b,c,d],[e,f,g],[h,i],在组成batch后,会变成
X:
| a | b | c | d |
| e | f | g | <pad> |
| h | i | <pad> | <pad> |
Y:
| b | c | d | <pad> |
| f | g | <eos> | <pad> |
| i | <eos> | <pad> | <pad> |
X是输入,Y是预测。那么从第三行可以看出,<pad>在预测下一个<pad>。这显然是有问题的。
一种解决方案就是使用mask矩阵,在loss的计算时,将那些本不应该计算的mask掉,使得其loss为0,这样就不会反向回传了。
具体实践:在PyTorch中,以CrossEntropy为例:
1 2 | class torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction=’elementwise_mean’ |
如果reduction=None则会返回一个与输入同样大小的矩阵。在与mask矩阵相乘后,再对新矩阵进行mean操作。
在PyTorch实践上还可以可以这么写:
1 2 3 | masked_outputs = torch.masked_select(dec_outputs, mask) masked_targets = torch.masked_select(targets, mask) loss = my_criterion(masked_outputs, masked_targets) |
另一种更为简单的解决方案是,直接在CrossEntropy中设ignore_index=0,这样,在计算loss的时候,发现target=0时,会自动不对其进行loss的计算。其本质和mask矩阵是一致的。
总结
mask矩阵可以用在任何地方,只要希望与之相乘的tensor相对应的地方不更新就可以进行mask操作。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











