







理解Transformer中mask操作
了解transformer结构
原始Transformer结构是由编码器和解码器构成,如下图所示,左侧和右侧分别对应着编码器(Encoder)和解码器(Decoder)结构。其中,编码器主要是由多头自注意力子层和前馈神经网络构成,解码器是由带掩码的多头自注意力子层和交叉注意力子层和前馈神经网络构成。每个transformer块接受一个向量序列作为输入,并输出一个等长的向量序列作为输出。

Transformer中mask操作
了解了transformer基本结构,来谈谈Encoder和Decoder模块中分别使用的掩码mask操作,以及为什么需要mask?
对于Encoder模块中的mask
在模型训练过程中,数据会以batch(多个句子向量)的形式输入到模型进行训练,而自然语言中一个batch内的每一句话的长度可能不一致,为了保证一个batch内输入的长度一致,所以需要将所有句子都补全到最大的长度,也就是将短句子的长度填充到最长句子的长度,一般使用0进行填充。这种用0填充的位置信息是没有意义的,因此不应该参与模型训练的梯度反向传播过程,为了避免这些填充(padding)位置影响模型训练效果,所以在训练时需要将填充的位置给遮挡住(mask),这种做法称为padding mask,在多头自注意力的计算过程中,让有效词的注意力集中在有意义的词位置上。
具体的,padding mask在自注意力模块的计算过程中处于softmax函数之前,将padding补全位置的值设置成一个非常小的负数(一般设置为负无穷),再通过softmax函数计算后补全位置的概率值就变为0,这相当于把补全位置给mask了。
举个例子:
假设当前batch中最长句子有10个token,有以下三个句子:
“学习人工智能”
“大语言模型的发展趋势”
“深度学习”
为了让所有句子的长度保持一致的,能够进行模型训练,需要将不足10个token的句子填充(padding)到10的长度,那模型怎么知道句子哪些token是填充的呢?就需要通过添加掩码(mask)来标记。例如,上面三个句子的掩码分别是:
(0,0,0,0,0,0,1,1,1,1)
(0,0,0,0,0,0,0,0,0,0)
(0,0,0,0,1,1,1,1,1,1)
对于Decoder模块中的mask
next token predict(预测下一个词)
Decoder模块是用来做next token predict任务,所以是采用自回归方式进行训练(解释一下自回归,就是Decoder在预测下一个词时,会根据之前词的信息进行预测,一个词接一个词的预测)。具体示例,如下图所示,首先根据输入 “start” 预测出第一个单词为 “学”,然后根据输入 “start 学” 预测下一个单词 “习”。

sequence mask(序列掩码)
自注意力在计算时,是一种双向编码,一个词可以和其他词进行相关性计算,那如何让decoder模块看不到预测词以及之后的词的信息(也就是在一个序列中的第i个token在解码时,只能依靠第i个token之前(包括自身)的token,而不依赖于之后token进行预测)?
也就是要用到sequence mask操作,它会采取一个遮盖(mask)的方法使得decoder在计算self-attention的时候只用第i个token之前的token进行计算。也就是使用单向注意力进行计算,目的是:在训练的时候,不让模型看到后面的“答案”,因此需要将未来的token(词信息)给遮盖住。
在decoder阶段中self-attention必需要添加sequence mask,不像padding mask可以跳过;并且sequence mask操作也是在self-attention的softmax函数之前,与padding mask不一样的是mask矩阵中的元素不一样,mask矩阵是一个下三角矩阵,即对角线以及对角线一下是1(不遮挡),对角线以上全为0(遮挡)。并将QV矩阵计算得到的attention scores(权重矩阵)位置对应于mask矩阵为0位置上的元素替换为一个很小的负数,再后面经过softmax时将遮挡位置的值变为0,从而达到遮盖目的。
具体计算过程如下:
第一步:在进行decoder计算时,假设输入的序列矩阵包含“学习人工智能”6个单词的表示向量,那么mask矩阵是一个6x6的矩阵。通过对mask矩阵不同位置标记0(不遮挡)和1(遮挡)值,用于表示第i个token只能使用第i-1以及之前token的信息。根据输入矩阵,确定 mask矩阵值,如下图所示:

第二步:计算attention scores(注意力权重矩阵)。对输入矩阵X通过线性变换得到Q,K,V矩阵,然后对Q、K矩阵计算attention scores(注意力权重矩阵):

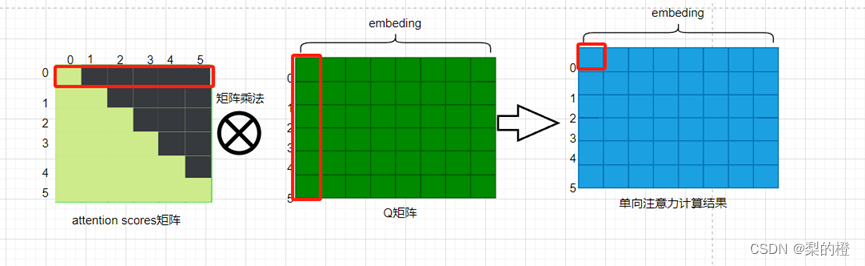
第三歩:带有mask的权重矩阵计算。得到attention scores矩阵后,使用mask矩阵与权重矩阵进行按位相乘,其实是将权重矩阵中对应mask矩阵中的遮挡位置的值设置为无穷小的值,然后再使用softmax函数计算使得遮挡位置的值为0(因为无穷小的值经过softmax函数计算后结果为0),计算过程如下:

第4歩:输出单向注意力计算结果。通过如下计算过程可看到,第1个token的预测只用到了第0个token的信息。具体如下图:
总结
在transformer中Encoder和Decoder模块都需要使用mask操作。在Encoder模块中使用的mask操作称为padding mask;在Decoder模块中的使用mask操作,称为sequence mask。这也是在模型结构之外需要知道的操作,以及便于理解transformer代码中的mask计算过程。

















 1376
1376

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









