









文章目录
前言
今天学了pandas的基础用法,考虑到pandas中操作的很多,一时无法全部掌握熟练,这篇文章将pandas常用的一些操作进行总结,方便及时查阅复习。
一、pandas创建和读取存储
1.创建Dataframe和Series
创建DataFrame最常用的方式是字典+列表,语句很简单,先是字典外括,然后依次打出每一列的列名及其对应的列值(此处一定要用列表),这里对应关系重要,列的顺序并不重要。
import pandas as pd
df1 = pd.DataFrame({'工资':[15000,7000,12000,23000],'绩效分':[95,59,82,100],
'备注':['优秀','不及格','良好','最佳']},
index = ['阿粥','老六','老王','老龚'])
#把df1里面的工资列作为新的Series创建
s1 = df1['工资']
#查看s1的类型
print(type(s1))
s1
直接读取现有数据
import pandas as pd
# 创建数据
data = { "星期": ["星期一", "星期二", "星期三"], "天气": ["晴", "阴", "雨"], "温度": [29, 27, 22] }
# 创建DataFrame
df = pd.DataFrame(data)
# 显示DataFrame
print(df)
1.1创建series
先说函数 pandas.Series( data, index, dtype, name, copy)
参数说明:
data:一组数据(ndarray 类型),元组、列表、字典、数组等都可以
index:数据索引标签,如果不指定,默认从 0 开始;如果指定的话,使用列表或者元组格式
进行指定,其中列表或者元组的长度需要和 data的数据行数一致。此处索引指的是
行索引。
dtype:数据类型,默认会自己判断。
name:设置名称。# 也可以不设置
copy:拷贝数据,默认为 False。
2.数据读取和存储excel和csv
2.1excel读取
首先导入os这个系统模块,把Python切换到这个路径下:
import os
os.chdir(r'C:\works\WRI\Python电商数据分析实战\第二章 Pandas快速入门')
os.chdir是实现系统文件路径切换的方法,在里面输入我们从系统复制的路径地址。
需要注意的是,路径前面加了一个r,是因为文件路径一般都包含斜杠,而斜杠在Python中会有其他含义(如转义)。在路径前加r相当于告诉Python里面的内容没有其他意思,保证路径被程序完整准确的理解。

注意:
我们的data1.xlsx中sheet1的数据源长这样:
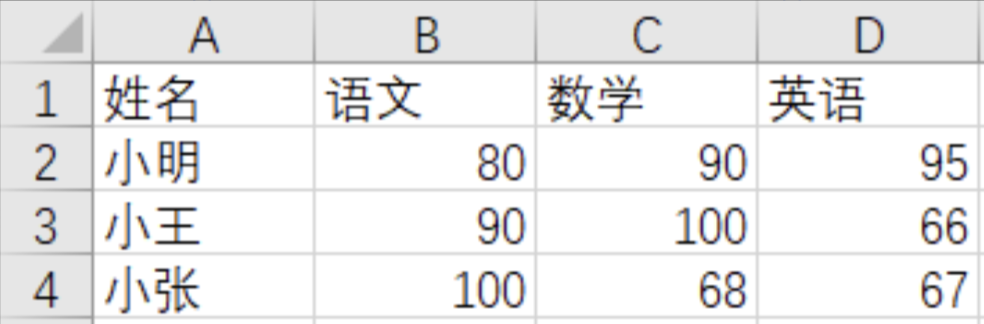
对比上面的结果,发现Pandas很智能的把第一行当作了表头来处理,实际数据则从第二行开始。
假如我们遇到了sheet2中的数据,在Excel文件中当时只保存了源数据,如下图所示:
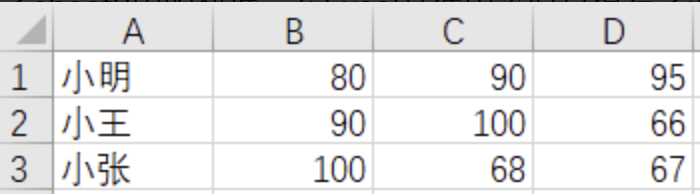
如果用Pandas直接读取,默认第一行当作表头的规则就显得不那么智能了:
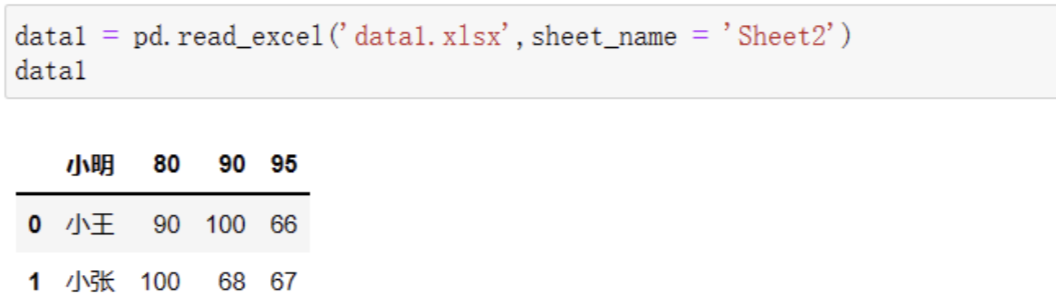
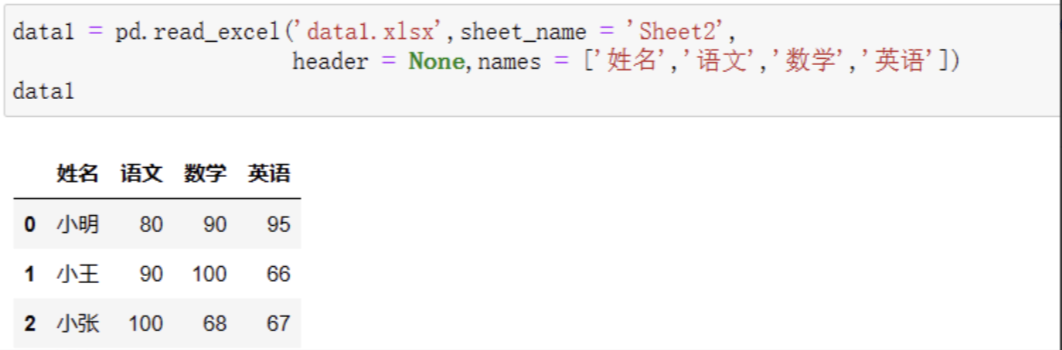
这个时候我们可以把headers参数设置成None,来告诉Pandas我们的数据中没有表头:
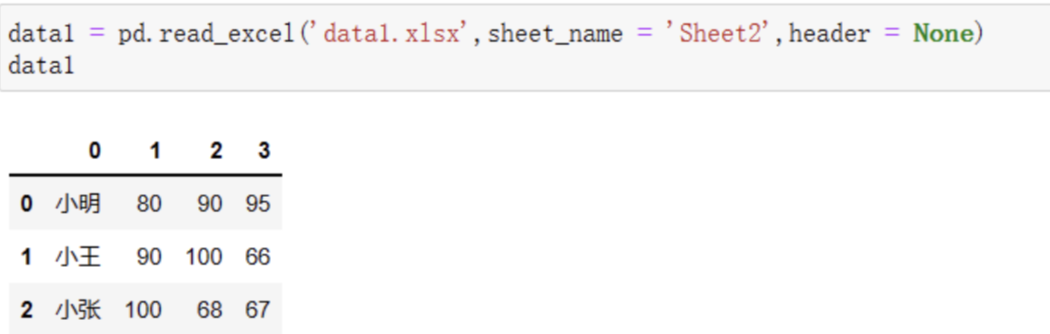
如果headers = None,默认的column表头是从0到3的几个数字,很不美观。所以,我们可以在读取的时候通过names参数,把表头设置成我们预期的内容即可:
当然,headers除了设置成None,还可以设置成数字,代表在读取时把第几行数据作为表头。例如我们想要把Sheet1中的小明所在的第二行作为表头,把headers设置成1即可(日常计数是从1开始,但Python里面的计数是从0开始):
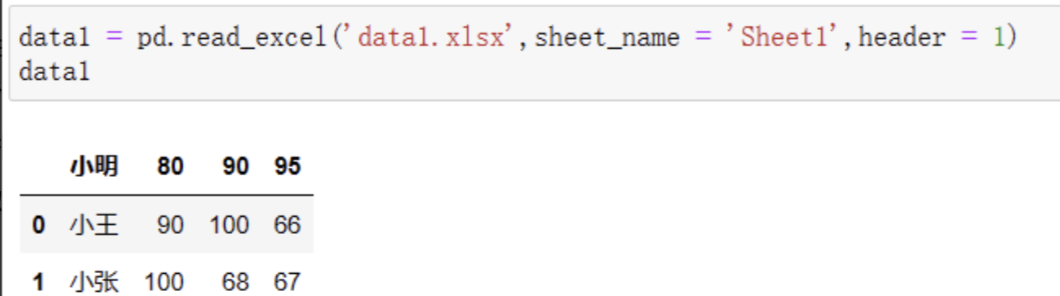
这样一来,可怜的小明就成为了表头。
其他参数:
- index_col指定索引列
- usecols指定读取部分列
- nrows指定读取部分行
- prefix给表头设置前缀
- dtype和字典结合,读取时为每一列数据设置格式
- …
2.2csv读取
Pandas读取csv文件用的是pd.read_csv(‘具体文件名’)的方法,如下图所示。不过Pandas在Excel和csv文件的读取上有很高的相似性,上节讲的大多数规则和参数也都是用于csv文件的读取。
需要注意的是,在实际操作中Excel文件的读取一般不会有什么问题,但csv的读取由于中文路径和编码等问题是报错的高发区,接下来我们重点看看csv文件的三个注意点以及如何避免错误。
2.2.1中文路径
当文件路径是中文时直接读取,在一些Python版本里会报错。因为Python默认的读取引擎是C语言,它在处理中文时容易出问题。这个时候把读取引擎参数engine设置为Python就可以解决:
data = pd.read_csv('data2.csv',engine = 'python')
2.2.2编码问题
csv文件有不同的编码形式,utf8和gbk是两种最常见的编码。类似于一把钥匙对一个锁,如果文件是gbk编码的锁,那么用utf8的钥匙就算拧断也打不开,Pandas读取时默认是utf-8的编码格式。
通过设置encoding参数来指定文件编码格式,在读取gbk和其他编码文件的时候需要设置成对应编码即可解决问题:

2.2.3 分隔符的处理
Pandas的read_csv方法在读取csv文件时默认是以逗号作为分隔符来打开的(这也是绝大部分csv文件的分割方式),但如果当文件本身的分割使用的是其他分隔符,就需要在读取时设置好seq参数:
data2 = pd.read_csv('data2.csv',seq = '\t')
上面一串代码打开的文件是以\t为分隔符的。
2.3其他文件类型的读取
2.3.1 txt文件的读取
Pandas读取txt文件用的是pd.read_table(),需要在读取时输入txt文件的名称和分隔符(这里是必须的):
data1 = pd.read_table('对应文件名',seq = '\t')
2.3.2 json文件的读取
Json文件是一种类字典形式的文件,在读取时用pd.read_json()方法。
Excel和csv是最主要面对的两种文件形式,其他文件类型的读取这里只简单提及,只是打开的方法有所差异,大部分参数也都是通用的。
2.4 存储数据
当我们对数据进行读取、处理和分析之后,往往需要把结果数据存储起来。
在Pandas中数据存储非常方便,用的是pd.to_xxx()方法(xxx是你期望存储的文件形式):
data.to_excel('data1.xlsx')
data.to_csv('data1.csv')
默认的存储方式会把索引也作为一列存储,如果我们不希望索引保存,设置index=False就可以:
data.to_excel('xxx.xlsx',index = False)
二、pandas基本操作与常用函数
1 查看数据head和tail
很多时候我们想要查看数据的某个片段,来确认读取或者处理之后的数据是否符合预期,应该如何操作呢?
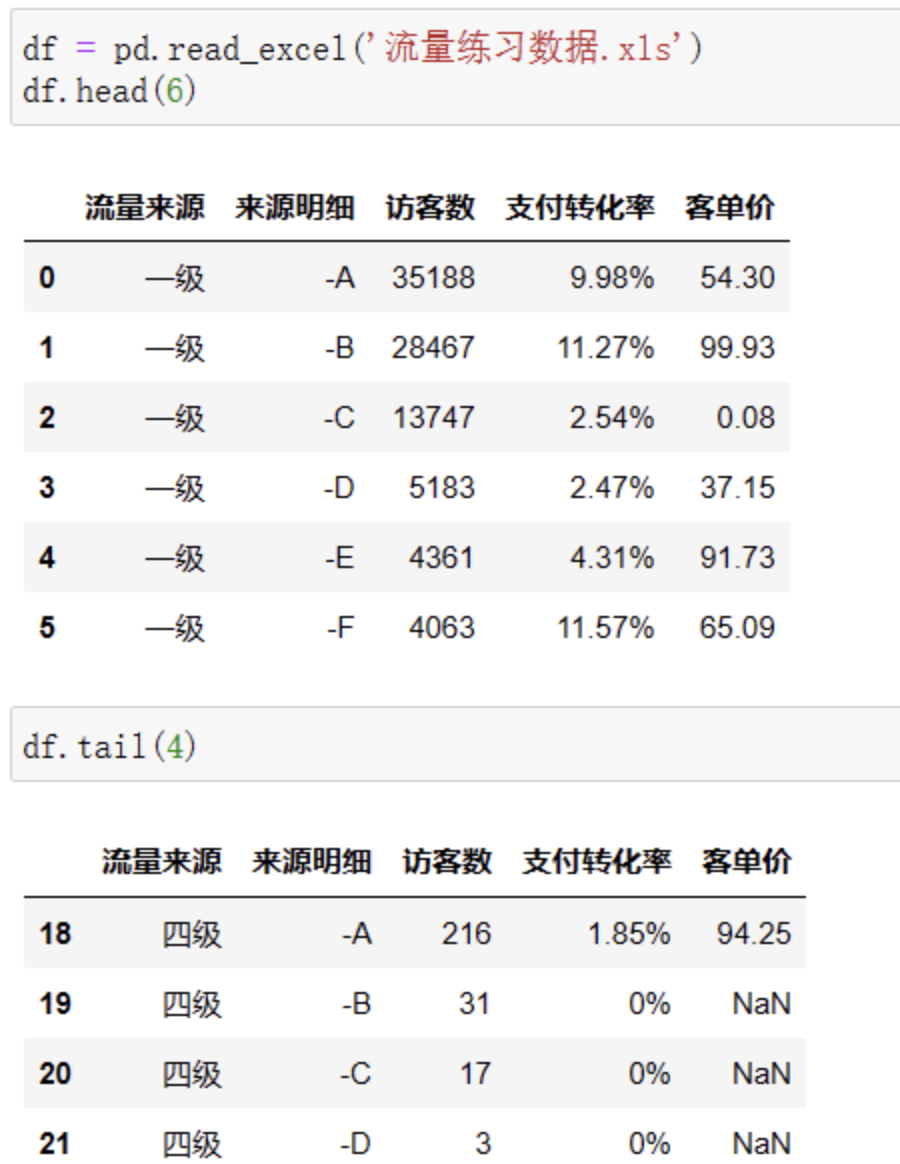
Pandas中用df.head()函数直接可以查看默认的前5行。与之对应,df.tail()就可以查看数据尾部的5行数据,这两个参数内可以传入一个数值来自定义查看的行数,例如df.head(6)表示查看前6行数据和用df.tail(4)查看最后4行数据:
2.基本信息info
数据的行列数,每一列是否有空缺值存在,各列的数据格式分别是什么,这些信息对于分析师来说也至关重要。
用df.info()可以帮助我们一步摸清各列数据的类型,以及缺失情况:
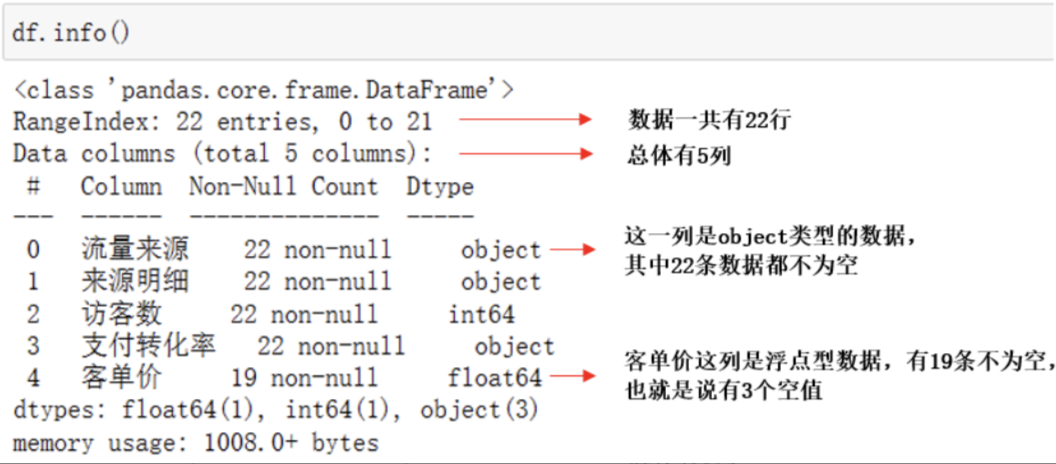
上面的信息全面描述了数据集的行列数、对应名称、每一列的数据类型、有多少条非空数据以及数据集的大小,非常方便。
3.数据统计函数describe
在查看了数据样例,了解数据类型和空缺值情况后,我们经常还会对数据某些列做统计层面的分析。
Pandas依然可以一键搞定,它的df.describe()可以快速计算数值型数据的关键统计指标,像平均数、分位数、标准差等常见指标。
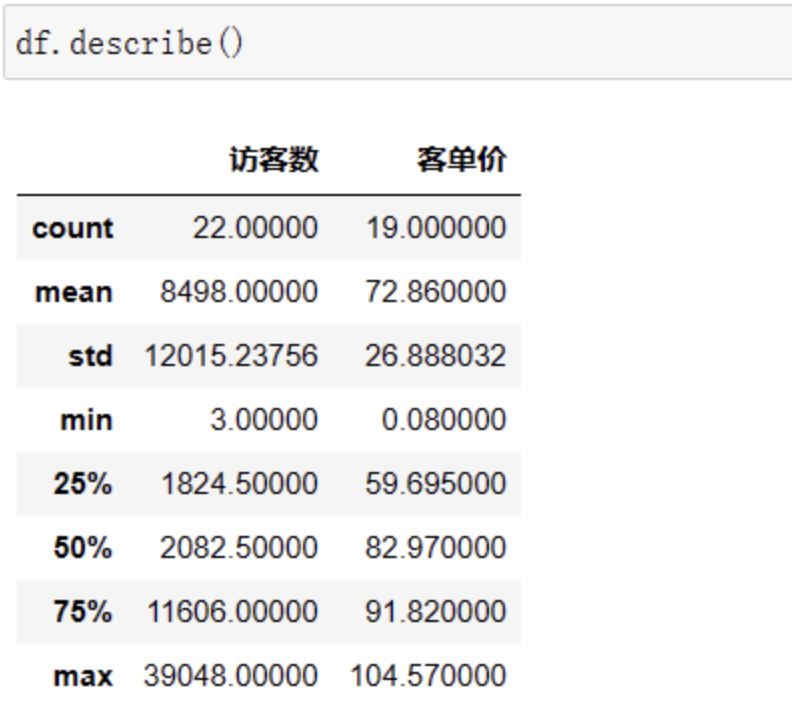
但是!我们本来有5列数据,为什么返回结果只有两列?那是因为这个操作只针对数值型的列,非数值型的列本身也无法得出完整的统计信息。其中count是统计每一列的有多少个非空数值,mean、std、min、max对应的分别是该列的均值、标准差、平均值和最大值,25%、50%、75%对应的则是具体分位数大小。
4.基本增删改查操作
4.1增
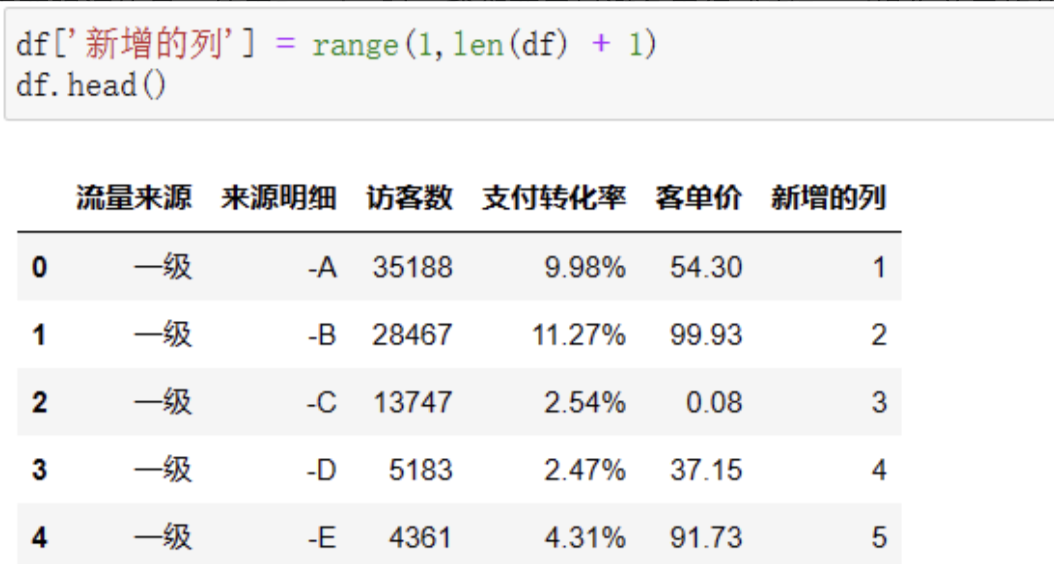
增加列用的是df[‘新列名’] = 新列值的方式,在原数据基础上赋值即可:
4.2删(drop)
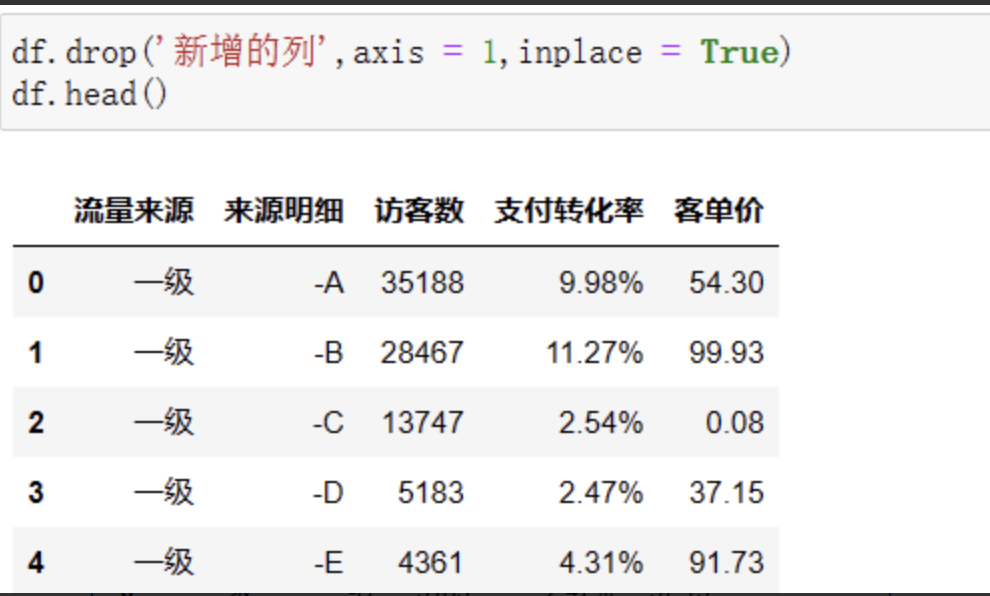
我们用drop函数制定删除对应的列,axis = 1表示针对列的操作,inplace为True,则直接在源数据上进行修改,否则源数据会保持原样。
4.3选
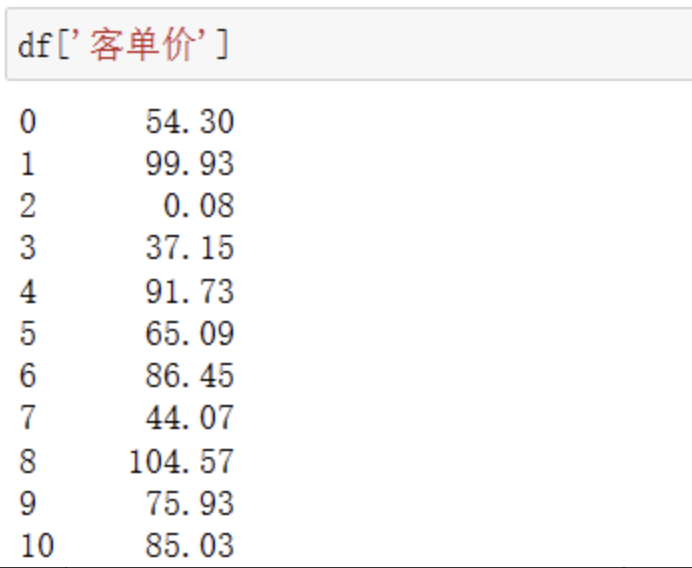
我们想要选取某一列数据应该怎么操作?df[‘列名’]即可:
选取多列呢?需要用括号内的列表来传递df[[‘第一列’,‘第二列’,‘第三列’…]]:
4.4改
数据的更改和新增操作很相近,用df[‘旧列名’] = 某个值或者某列值(列值的数量必须和原数据行数相等),就完成了对原列数值的修改。
总结
以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用和读取存储,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法,明天继续加油!!!















 732
732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









