






1.GoogLeNet介绍
GoogLeNet的名字不是GoogleNet,而是GoogLeNet,这是为了致敬LeNet。GoogLeNet和AlexNet/VGGNet这类依靠加深网络结构的深度的思想不完全一样。GoogLeNet在加深度的同时做了结构上的创新,引入了一个叫做Inception的结构来代替之前的卷积加激活的经典组件。GoogLeNet在ImageNet分类比赛上的Top-5错误率降低到了6.7%。
2.Inception Module
GoogLeNet中的基础卷积块叫作Inception块,Inception块在结构上比较复杂,如下图所示:
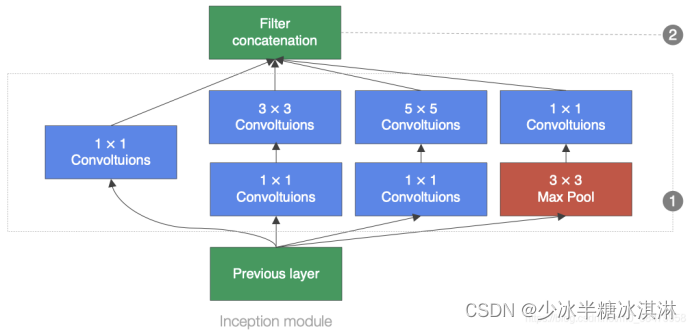
Inception块里有4条并行的线路。前3条线路使用窗口大小分别是1×1、3×3和5×5的卷积层来抽取不同空间尺寸下的信息,其中中间2个线路会对输入先做1×1卷积来减少输入通道数,以降低模型复杂度。第4条线路则使用3×3最大池化层,后接1×1卷积层来改变通道数。4条线路都使用了合适的填充来使输入与输出的高和宽一致。最后我们将每条线路的输出在通道维上连结,并向后进行传输。
Inception Module的代码实现如下,这段代码定义了一个 PyTorch 模块,用于实现 Inception 神经网络架构。Inception 是一种用于图像分类的流行卷积神经网络架构:
class Inception(nn.Module):
def __init__(self, in_planes, kernel_1_x, kernel_3_in, kernel_3_x, kernel_5_in, kernel_5_x, pool_planes):
super(Inception, self).__init__()
# 1x1 conv branch
self.b1 = nn.Sequential(
nn.Conv2d(in_planes, kernel_1_x, kernel_size=1),
nn.BatchNorm2d(kernel_1_x),
nn.ReLU(True),
)
# 1x1 conv -> 3x3 conv branch
self.b2 = nn.Sequential(
nn.Conv2d(in_planes, kernel_3_in, kernel_size=1),
nn.BatchNorm2d(kernel_3_in),
nn.ReLU(True),
nn.Conv2d(kernel_3_in, kernel_3_x, kernel_size=3, padding=1),
nn.BatchNorm2d(kernel_3_x),
nn.ReLU(True),
)
# 1x1 conv -> 5x5 conv branch
self.b3 = nn.Sequential(
nn.Conv2d(in_planes, kernel_5_in, kernel_size=1),
nn.BatchNorm2d(kernel_5_in),
nn.ReLU(True),
nn.Conv2d(kernel_5_in, kernel_5_x, kernel_size=3, padding=1),
nn.BatchNorm2d(kernel_5_x),
nn.ReLU(True),
nn.Conv2d(kernel_5_x, kernel_5_x, kernel_size=3, padding=1),#2 3*3=>1 5*5
nn.BatchNorm2d(kernel_5_x),
nn.ReLU(True),
)
# 3x3 pool -> 1x1 conv branch
self.b4 = nn.Sequential(
nn.MaxPool2d(3, stride=1, padding=1),
nn.Conv2d(in_planes, pool_planes, kernel_size=1),
nn.BatchNorm2d(pool_planes),
nn.ReLU(True),
)
def forward(self, x):
y1 = self.b1(x)
y2 = self.b2(x)
y3 = self.b3(x)
y4 = self.b4(x)
return torch.cat([y1,y2,y3,y4], 1)该模块由四个并行分支组成,对输入张量以不同的方式进行处理,然后沿着通道维度将输出进行拼接。
第一个分支对输入张量应用了 1x1 卷积,然后进行批归一化和 ReLU 激活。
第二个分支对输入张量应用了 1x1 卷积,然后进行批归一化和 ReLU 激活,接着对第一个卷积的输出应用了带有 padding 1 的 3x3 卷积,然后进行批归一化和 ReLU 激活。
第三个分支对输入张量应用了 1x1 卷积,然后进行批归一化和 ReLU 激活,接着对第一个卷积的输出应用了带有 padding 1 的 3x3 卷积,然后进行批归一化和 ReLU 激活,然后对第二个卷积的输出应用了带有 padding 1 的 3x3 卷积,然后进行批归一化和 ReLU 激活。
第四个分支对输入张量应用了带有 stride 1 和 padding 1 的 3x3 最大池化,然后对池化后的张量应用了 1x1 卷积,进行批归一化和 ReLU 激活。
四个分支的输出沿着通道维度进行拼接,并作为模块的输出返回。该模块的输入是一个形状为 (batch_size, in_planes, height, width) 的张量,其中 in_planes 是输入通道数,输出是一个形状为 (batch_size, kernel_1_x + kernel_3_x + kernel_5_x + pool_planes, height, width) 的张量,其中 kernel_1_x、kernel_3_x、kernel_5_x 和 pool_planes 是四个分支的输出通道数。
3.GoogLeNet模型
GoogLeNet主要由Inception模块构成,如下图所示:
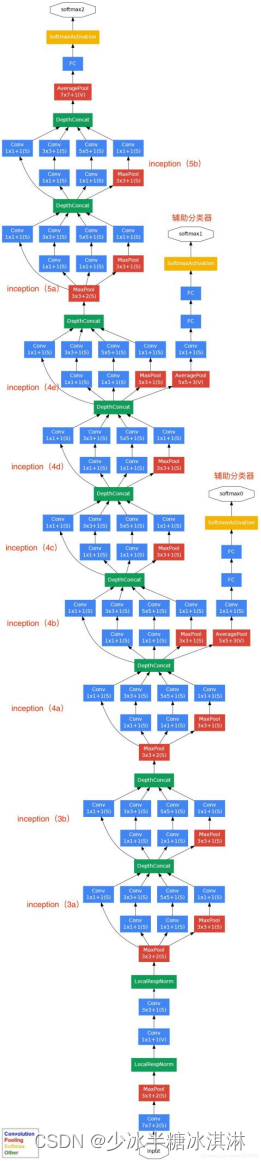
整个网络架构我们分为五个模块,每个模块之间使用步幅为2的3×3最大池化层来减小输出高宽。
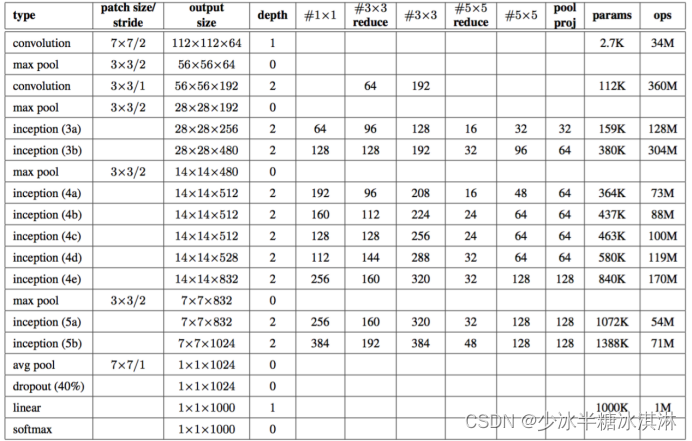
GoogLeNet的网络设计如下表:
Pre-layers1模块
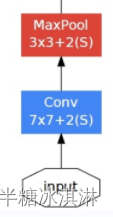
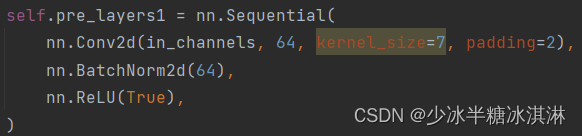
这段代码定义了一个 Pre-layers1 模块,包含了三个层,用于实现输入张量的预处理。这个模块包含以下三个层:
- 一个 2D 卷积层:这个卷积层使用了 7x7 的卷积核,处理输入张量的每一个空间位置。其中,参数 in_channels 表示输入张量的通道数,参数 64 表示输出通道数,参数 padding=2 表示在输入张量四周各添加两列/行的零填充,这样可以保持卷积后输出的张量大小不变。
- 一个批归一化层:该层对卷积层的输出进行批归一化处理,即将每个通道的输出值减去均值并除以标准差,以加速网络收敛并提高泛化性能。
- 一个 ReLU 激活函数:该层对批归一化后的输出进行 ReLU 操作,即将所有负数输出值设为零,保留所有非负数输出值。
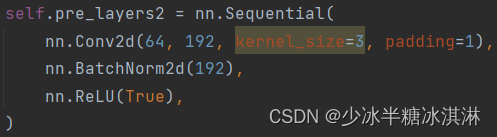
self.pre_layers2这个模块是在 self.pre_layers1 模块的基础上继续对输出张量进行处理。这个模块包含以下三个层:
- 一个 2D 卷积层:这个卷积层使用了 3x3 的卷积核,处理输入张量的每一个空间位置。其中,参数 64 表示输入通道数,参数 192 表示输出通道数,参数 padding=1 表示在输入张量四周各添加一列/行的零填充,这样可以保持卷积后输出的张量大小不变。
- 一个批归一化层:该层对卷积层的输出进行批归一化处理,即将每个通道的输出值减去均值并除以标准差,以加速网络收敛并提高泛化性能。
- 一个 ReLU 激活函数:该层对批归一化后的输出进行 ReLU 操作,即将所有负数输出值设为零,保留所有非负数输出值。
模块3
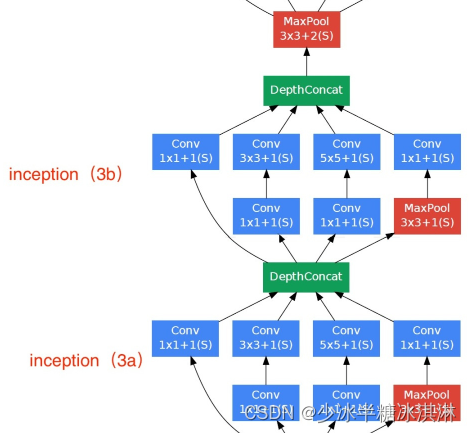

模块3定义了三个模块:a3、b3和max_pool。
a3和b3都是基于Inception模块的,分别输入192和256个特征图,使用不同的卷积核大小和个数来进行特征提取。具体地,a3使用了一个1x1卷积核、一个3x3卷积核和一个5x5卷积核以及一个3x3最大池化层,它们的输出通过在通道维度上进行拼接而合并在一起;b3使用了两个1x1卷积核、两个3x3卷积核和一个5x5卷积核以及一个3x3最大池化层,同样通过拼接来合并它们的输出。
max_pool是一个最大池化层,输入特征图的大小为3x3,步幅为2,填充为1。
模块4
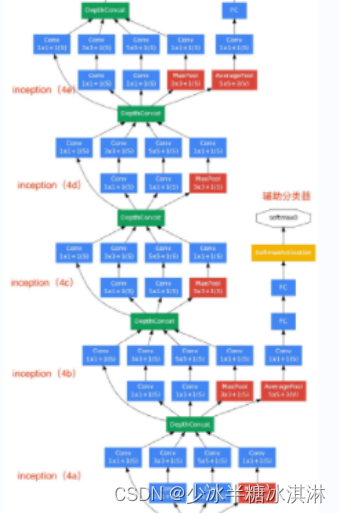
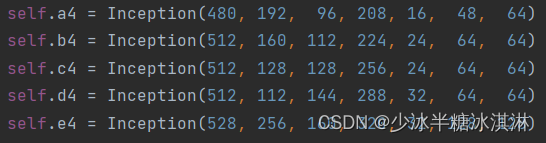
模块4定义了5个模块,每个模块都是基于Inception模块的,分别命名为a4、b4、c4、d4和e4。
这些模块的输入特征图的通道数逐步增加,分别为480、512、512、512和528。它们都是由不同的卷积核大小和数量组成的,用于提取不同层次的特征:
- a4使用了一个1x1卷积核、一个3x3卷积核和一个5x5卷积核以及一个3x3最大池化层。
- b4使用了一个1x1卷积核、一个3x3卷积核和一个5x5卷积核以及一个3x3最大池化层。
- c4使用了一个1x1卷积核、两个3x3卷积核和一个5x5卷积核以及一个3x3最大池化层。
- d4使用了一个1x1卷积核、两个3x3卷积核和一个5x5卷积核以及一个3x3最大池化层。
- e4使用了一个1x1卷积核、一个3x3卷积核和一个5x5卷积核以及一个3x3最大池化层。
模块5
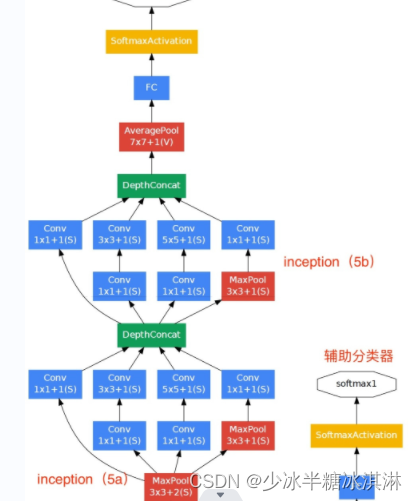
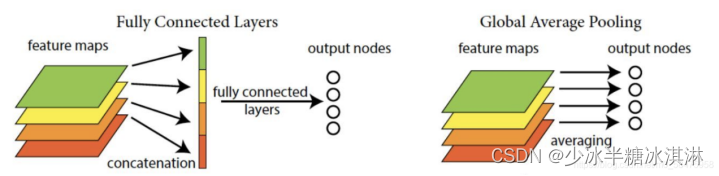
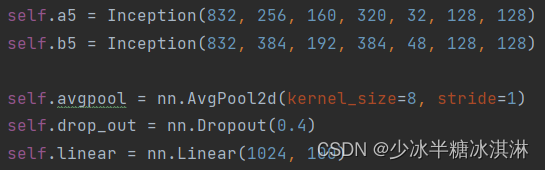
模块5定义了 GoogLeNet 模型的最后几层。模型的输入特征图的深度为 832。模型将输入特征图通过 Inception 模块 a5 和 b5 进行特征提取。最后,模型通过一个平均池化层对特征图进行降维,然后通过一个 dropout 层减少过拟合,最终通过一个全连接层将特征向量映射到 100 维的输出向量上。
具体来说,这里定义了 Inception 模块 a5 和 b5,它们的参数配置和之前定义的 Inception 模块类似。然后,通过一个平均池化层对特征图进行降维,将特征图的高和宽降至 1,然后通过一个 dropout 层减少过拟合。最后,通过一个线性全连接层将特征向量映射到 100 维的输出向量上。
关键函数
在模型评估部分,新增加了分类结果的可视化;在模型训练部分中,新增了对验证集的数据验证。
def test_model(net,testloader,criterion,device):
......
# 随机选择 5*5 张图像进行可视化
images, labels = iter(testloader).__next__()
outputs = net(images.to(device))
_, predicted = torch.max(outputs, 1)
fig, axes = plt.subplots(nrows=5, ncols=5, figsize=(10, 10))
for i, ax in enumerate(axes.flat):
# 显示图像
ax.imshow(np.transpose(images[i].cpu().numpy(), (1, 2, 0)))
# 判断预测结果是否与真实标签相同
predicted_label = class_names[predicted[i]]
true_label = class_names[labels[i]]
if predicted_label == true_label:
label_color = 'green'
label_text = 'Correct'
else:
label_color = 'red'
label_text = 'Wrong'
# 设置图像标题为分类名称和结果标签
ax.set_title(f"Predicted: {predicted_label} \n results: {label_text} \n True: {true_label}", color=label_color)
plt.tight_layout()
plt.show()
def train_model(net, criterion, optimizer, trainloader, valloader, device,epochs=30):
# Train the model
.......
for epoch in range(epochs): # loop over the dataset multiple times
print("Epoch[{}/{}]:".format(epoch + 1, epochs))
......
for i, data in enumerate(trainloader, 0):
# get the inputs
inputs, labels = data[0].to(device), data[1].to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
acc = accuracy(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_train_iter_loss += loss.item()
running_train_iter_acc += acc.item()
running_train_loss += loss.item()
running_train_acc += acc.item()
if i % 100 == 99: # print every 100 mini-batches
print('[%d, %5d] train_loss: %.3f, train_accuracy: %.3f' %
(epoch + 1, i + 1, running_train_iter_loss / 100, running_train_iter_acc / 100))
train_loss_iter_list.append(running_train_iter_loss / 100)
train_acc_iter_list.append(running_train_iter_acc / 100)
running_train_iter_loss = 0.0
running_train_iter_acc = 0.0
train_loss_list.append(running_train_loss / len(trainloader))
train_acc_list.append(running_train_acc / len(trainloader))
print('Epoch[ %d / %d ] : train_loss: %.3f, train_accuracy: %.3f' % (epoch + 1, epochs, running_train_loss / len(trainloader), running_train_acc / len(trainloader)))
# Evaluate the model on the validation set
running_val_loss = 0.0
running_val_acc = 0.0
with torch.no_grad():
for data in valloader:
inputs, labels = data[0].to(device), data[1].to(device)
outputs = net(inputs)
val_loss = criterion(outputs, labels)
val_acc = accuracy(outputs, labels)
running_val_loss += val_loss.item()
running_val_acc += val_acc.item()
val_loss_list.append(running_val_loss / len(valloader))
val_acc_list.append(running_val_acc / len(valloader))
print('Epoch[ %d / %d ] : val_loss: %.3f, val_accuracy: %.3f' %
(epoch+1, epochs, running_val_loss / len(valloader), running_val_acc / len(valloader)))
print('Finished Training')
#plot
......
实验结果
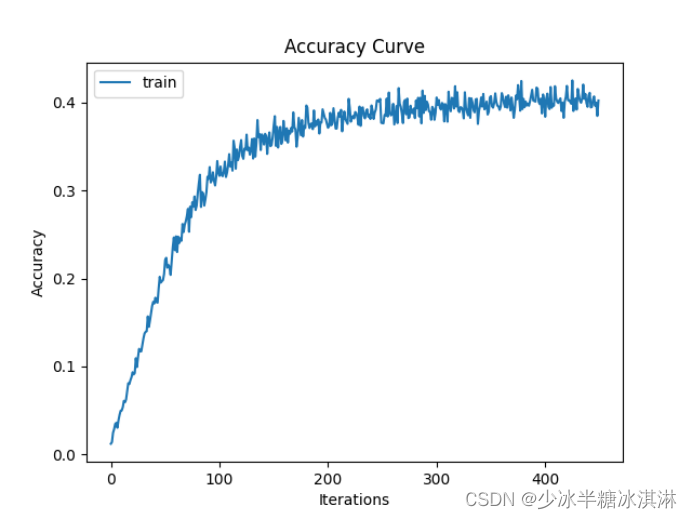
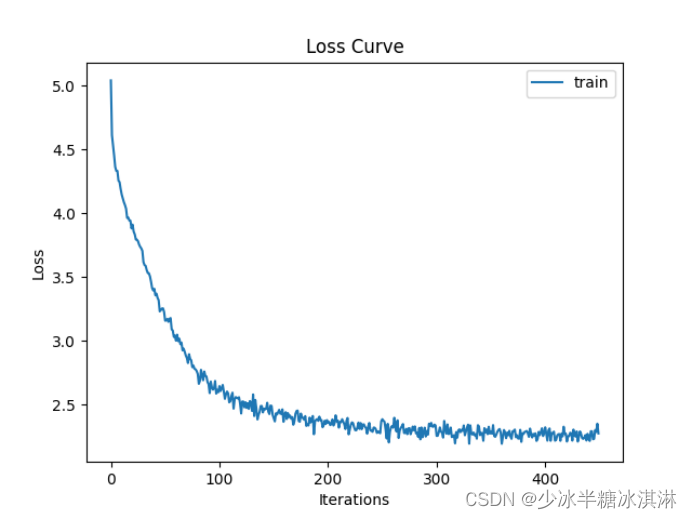
Epochs=30,learning rate=1e-1
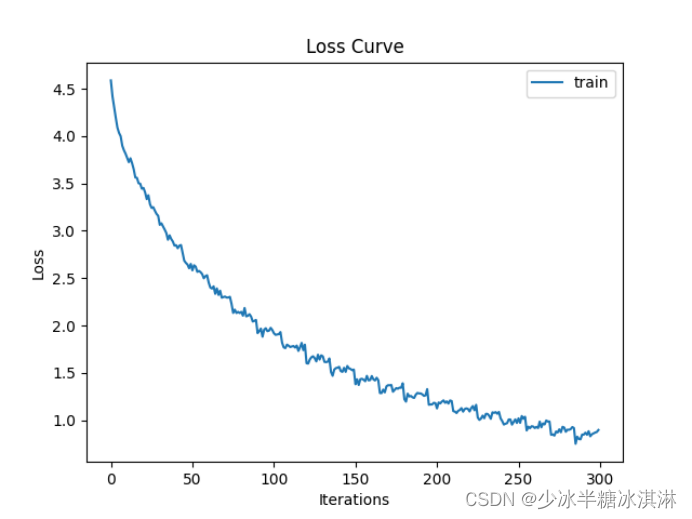
训练准确率(Train accuracy)和训练损失值(Train loss)随模型迭代次数的变化趋势图:
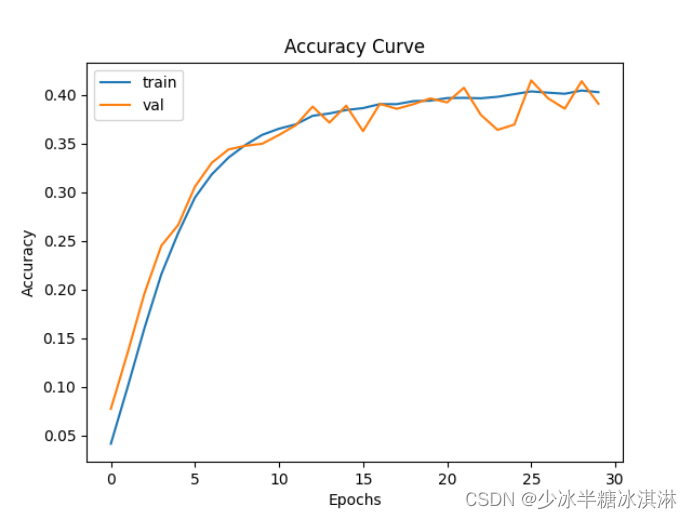
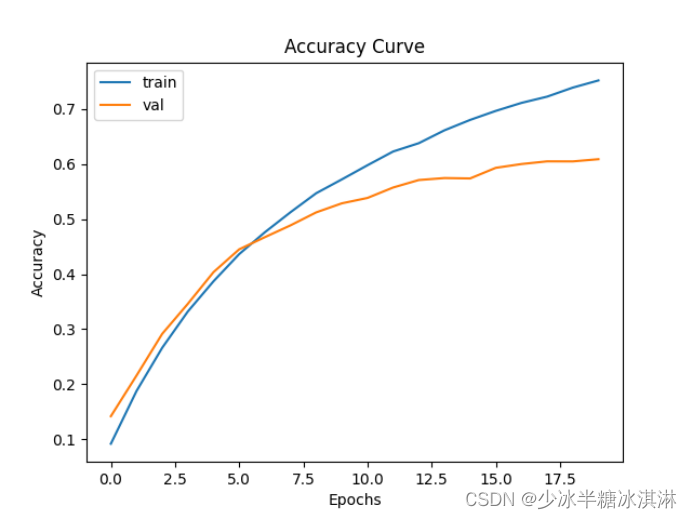
训练准确率(Train accuracy)和验证准确率(Validation accuracy)随训练轮数(epoch)的变化趋势图:
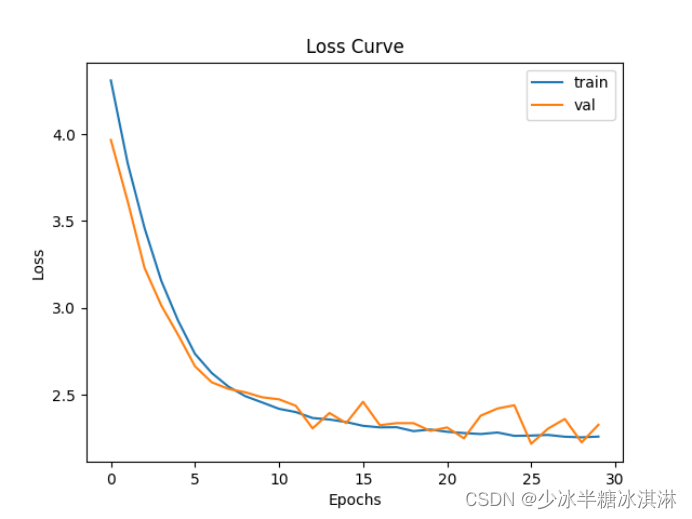
训练损失值(Train loss)和验证损失值(Validation loss)随训练轮数(epoch)的变化趋势图:
在10k测试集上测试得到模型的最终准确率为38%,随机抽取5*5的可视化结果图,结果显示如图:

可以看出训练的结果效果不理想,在给定参数条件下,测试集的准确率仅仅达到38%,这是非常不理想的,因此后续采取了调整模型结构和参数的措施,进一步优化模型。
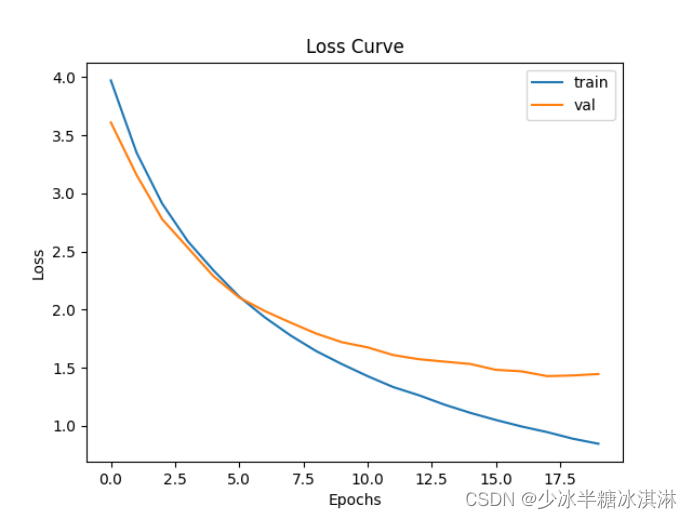
Epochs=20,learning rate=1e-3
训练准确率(Train accuracy)和训练损失值(Train loss)随模型迭代次数的变化趋势图:
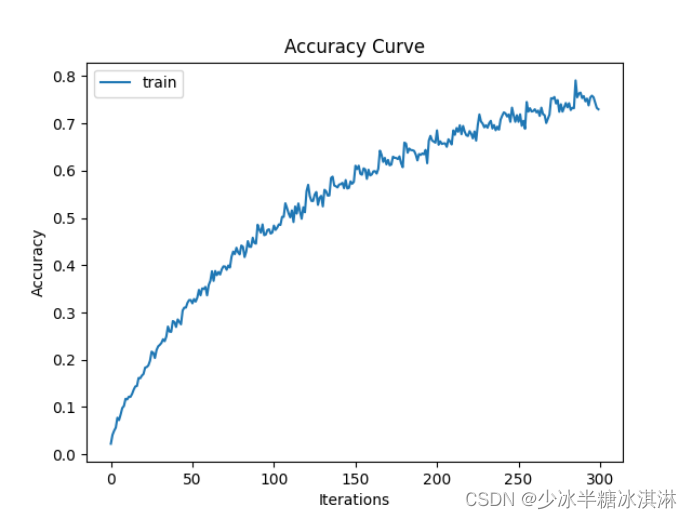
训练准确率(Train accuracy)和验证准确率(Validation accuracy)随训练轮数(epoch)的变化趋势图:
训练损失值(Train loss)和验证损失值(Validation loss)随训练轮数(epoch)的变化趋势图:
 在10k测试集上测试得到模型的最终准确率为60%,随机抽取5*5的可视化结果图,结果显示如图:
在10k测试集上测试得到模型的最终准确率为60%,随机抽取5*5的可视化结果图,结果显示如图:


















 2563
2563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









