






目录
1 概念
网络设备是Linux的第三类标准设备,没有对应的设备文件,使用内部设备名访问。网络设备及其驱动属于整个TCP/IP协议层的一部分,实现遵循TCP/IP协议栈的要求。(网卡驱动属于网络接口层)。
网络设备异步接收外部的数据包,主动请求将硬件收到的数据包交给内核。
2 网络设备驱动框架
Linux网络设备驱动程序的体系结构自上往下分为四层:网络协议接口层、网络设备接口层、设备驱动功能层和网络设备与媒介层。
在设计网络设备驱动程序时,我们主要的工作就是编写设备驱动功能层的相关函数以填充net_device数据结构并将net_device注册入内核。
2.1 体系结构
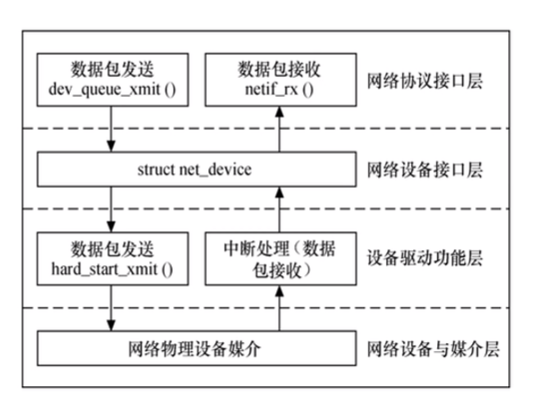
2.2 网络协议接口层
主要功能:给上层协议提供透明的数据包发送和接收接口。
当上层的ARP或IP协议需要发送数据包时,就会调用dev_queue_xmit()函数。
同样地,上层协议需要接收数据包时,就会调用netif_rx()函数。
/* : dev_queue_xmit
* @description : 上层协议发送数据包时的调用接口
* @param – skb : 套接字缓冲区指针
* @return : 0 成功;其他 失败
*/
int dev_queue_xmit(struct sk_buff *skb)
/* : netif_rx
* @description : 上层协议接收数据包时的调用接口
* @param – skb : 套接字缓冲区指针
* @return : 0 成功;其他 失败
*/
int netif_rx(struct sk_buff *skb)2.3 网络设备接口层
网络设备接口层的主要功能是为千变万化的网络设备定义了统一、 抽象的数据结构 net_device 结构体,以不变应万变,实现多种硬件在软件层次上的统一。
net_device 结构体在内核中指代一个网络设备, 网络设备驱动程序只需通过填充 net_device 的具体成员并注册 net_device 即可实现硬件操作函数与内核的挂接。net_device 本身是一个巨型结构体,包含网络设备的属性描述和操作接口。
2.4 设备驱动功能层
net_device 结构体的成员(属性和函数指针)需要被设备驱动功能层的具体数值和函数赋予。对于具体的设备 xxx,工程师应该编写设备驱动功能层的函数,这些函数形如 xxx_open()、 xxx_stop()、 xxx_tx()、xxx_ hard_header()、 xxx_get_stats()、 xxx_tx_timeout()、 xxx_poll()等。
由于网络数据包的接收可由中断引发,设备驱动功能层中另一个主体部分将是中断处理函数,它负责读取硬件上接收的数据包并传送给上层协议,可能包含 xxx_interrupt()和 xxx_rx()函数,前者完成中断类型判断等基本的工作,后者则需完成数据包的生成和递交上层等复杂工作。
对于特定的设备, 我们还可以定义其相关私有数据和操作, 并封装为一个私有信息结构体 xxx_private,让其指针被赋值给 net_device 的 priv 成员。 xxx_private 结构体中可包含设备特殊的属性和操作、自旋锁与信号量、定时器以及统计信息等。
2.4.0 net_device的生成和赋值
利用如下宏生成和赋值net_device:
#define alloc_netdev(sizeof_priv, name, setup) alloc_netdev_mqs(sizeof_priv, name, setup, 1, 1)
/* 相比于alloc_netdev,etherdev只是作为以太网设备的配置
* 实际也是通过alloc_netdev那些宏去设置以太网设备的缺省值。
* 这个函数分配一个网络设备使用 eth%d 作为参数 name.
* 它提供了自己的初始化函数 ( ether_setup )来设置几个 net_device 字段, 使用对以太网设备合适的值
*/
#define alloc_etherdev(sizeof_priv) alloc_etherdev_mq(sizeof_priv, 1)
#define alloc_etherdev_mq(sizeof_priv, count) alloc_etherdev_mqs(sizeof_priv, count, count)
/* : alloc_netdev_mqs
* @description : 生成一个net_device结构体,并对其成员赋值
* @param – sizeof_priv : 设备私有成员的大小
* @param – name : 设备名,这个名子可以有一个 printf 风格的 %d 在里面. 内核用下一个可用的接口号来替换这个 %d
* @param – setup : setup 是一个初始化函数的指针, 被调用来设置 net_device 结构的剩余部分。
* @param – txqs : 要分配的发送子队列数量,setup()函数接收的参数也为 struct net_device 指针,用于预置 net_device 成员的值。
* @param – rxqs : 要分配的接收子队列数量
* @return : 返回赋值后的net_device结构体指针
*/
struct net_device *alloc_netdev_mqs(int sizeof_priv, count char *name,
void(*setup)(struct net_device *),
unsigned int txqs,
unsigned int rxqs);2.4.0 net_device的释放
void free_netdev(struct net_device *dev);2.4.1 网络驱动设备的注册与注销
int register_netdev(struct net_device *dev);
void unregister_netdev(struct net_device *dev);net_device 结构体的分配和网络设备驱动注册需在网络设备驱动程序的模块加载函数中进行,而net_device 结构体的释放和网络设备驱动的注销则需在模块卸载函数中完成。网络设备驱动的模块加载/卸载函数模板如下:
int xxx_init_module(void)
{
...
/* 分配 net_device 结构体并对其成员赋值 */
xxx_dev = alloc_netdev(sizeof(struct xxx_priv), "sn%d", xxx_init);
if (xxx_dev == NULL)
... /* 分配 net_device 失败 */
/* 注册 net_device 结构体 */
if ((result = register_netdev(xxx_dev)))
...
}
void xxx_cleanup(void)
{
...
/* 注销 net_device 结构体 */
unregister_netdev(xxx_dev);
/* 释放 net_device 结构体 */
free_netdev(xxx_dev);
}2.4.2 网络设备初始化
网络设备的初始化主要需要完成如下几个方面的工作。
- 进行硬件上的准备工作,检查网络设备是否存在,如果存在,则检测设备所使用的硬件资源。
- 进行软件接口上的准备工作,分配 net_device 结构体并对其数据和函数指针成员赋值。
- 获得设备的私有信息指针并初始化其各成员的值。如果私有信息中包括自旋锁或信号量等并发或同步机制,则需对其进行初始化。
对 net_device 结构体成员及私有数据的赋值都可能需要与硬件初始化工作协同进行,即硬件检测出了相应的资源,需要根据检测结果填充 net_device 结构体成员和私有数据。
网络设备初始化代码模板如下:
void xxx_init(struct net_device *dev)
{
/*设备的私有信息结构体*/
struct xxx_priv *priv;
/* 检查设备是否存在和设备所使用的硬件资源 */
xxx_hw_init();
/* 初始化以太网设备的公用成员 */
ether_setup(dev);
#if 0
//参考https://www.freesion.com/article/6368897183/
/*设置设备的成员函数指针*/
dev->open = xxx_open;
dev->stop = xxx_release;
dev->set_config = xxx_config;
dev->hard_start_xmit = xxx_tx;
dev->do_ioctl = xxx_ioctl;
dev->get_stats = xxx_stats;
dev->change_mtu = xxx_change_mtu;
dev->rebuild_header = xxx_rebuild_header;
dev->hard_header = xxx_header;
dev->tx_timeout = xxx_tx_timeout;
dev->watchdog_timeo = timeout;
/*如果使用 NAPI,设置 pool 函数*/
if (use_napi)
{
dev->poll = xxx_poll;
}
/* 取得私有信息,并初始化它*/
#endif
/*设置设备的成员函数指针*/
ndev->netdev_ops = &xxx_netdev_ops;
ndev->ethtool_ops = &xxx_ethtool_ops;
dev->watchdog_timeo = timeout;
priv = netdev_priv(dev);
... /* 初始化设备私有数据区 */
其中,xxx_hw_init()函数完成硬件相关的初始化操作,如下所示。
- 探测 xxx 网络设备是否存在。探测的方法类似于数学上的“反证法”,即先假设存在设备 xxx,访问该设备,如果设备的表现与预期的一致,就确定设备存在;否则,假设错误,设备 xxx 不存在。
- 探测设备的具体硬件配置。一些设备驱动编写得非常通用,对于同类的设备使用统一的驱动,我们需要在初始化时探测设备的具体型号。另外,即便是同一设备,在硬件上的配置也可能不一样,我们也可以探测设备所使用的硬件资源。
- 申请设备所需要的硬件资源,如用 request_region()函数进行 I/O 端口的申请等,但是这个过程可以放在设备的打开函数 xxx_open()中完成。
2.4.3 网络设备的打开与释放
网络设备的打开函数需要完成如下工作:
- 使能设备使用的硬件资源,申请 I/O 区域、中断和 DMA 通道等。
- 调用 Linux 内核提供的 netif_start_queue()函数,激活设备发送队列。
网络设备的关闭函数需要完成如下工作:
- 调用 Linux 内核提供的 netif_stop_queue()函数,停止设备传输包。
- 释放设备所使用的I/O区域、中断和 DMA 资源。
void netif_start_queue(struct net_device *dev);
void netif_stop_queue (struct net_device *dev);网络设备的打开与释放模板
int xxx_open(struct net_device *dev)
{
/* 申请端口、 IRQ 等,类似于 fops->open */
ret = request_irq(dev->irq, &xxx_interrupt, 0, dev->name, dev);
...
netif_start_queue(dev);
...
}
int xxx_release(struct net_device *dev)
{
/* 释放端口、 IRQ 等,类似于 fops->close */
free_irq(dev->irq, dev);
...
netif_stop_queue(dev); /* can't transmit any more */
...
}2.4.4 数据发送流程
Linux网络子系统在发送数据包时, 会调用驱动程序提供的hard_start_transmit() 函数, 该函数用于启动数据包的发送。 在设备初始化的时候, 这个函数指针需被初始化以指向设备的xxx_tx() 函数。
网络设备驱动完成数据包发送的流程如下。
1) 网络设备驱动程序从上层协议传递过来的sk_buff参数获得数据包的有效数据和长度, 将有效数据放入临时缓冲区。
2) 对于以太网, 如果有效数据的长度小于以太网冲突检测所要求数据帧的最小长度ETH_ZLEN, 则给临时缓冲区的末尾填充0。
3) 设置硬件的寄存器, 驱使网络设备进行数据发送操作。
int xxx_tx(struct sk_buff *skb, struct net_device *dev)
{
int len;
char *data, shortpkt[ETH_ZLEN];
if (xxx_send_available(...)) { /* 发送队列未满, 可以发送 */
/* 获得有效数据指针和长度 */
data = skb->data;
len = skb->len;
if (len < ETH_ZLEN) {
/* 如果帧长小于以太网帧最小长度, 补0 */
memset(shortpkt, 0, ETH_ZLEN);
memcpy(shortpkt, skb->data, skb->len);
len = ETH_ZLEN;
data = shortpkt;
}
dev->trans_start = jiffies; /* 记录发送时间戳 */
if (avail) {/* 设置硬件寄存器, 让硬件把数据包发送出去 */
xxx_hw_tx(data, len, dev);
}
else
{
netif_stop_queue(dev);
...
}
}2.4.5 数据接收流程
中断接收数据
网络设备接收数据的主要方法是由中断引发设备的中断处理函数, 中断处理函数判断中断类型, 如果为接收中断, 则读取接收到的数据, 分配sk_buffer数据结构和数据缓冲区, 将接收到的数据复制到数据缓冲区, 并调用netif_rx() 函数将sk_buffer传递给上层协议。 代码清单14.9所示为完成这个过程的函数模板。
static void xxx_interrupt(int irq, void *dev_id)
{
...
switch (status &ISQ_EVENT_MASK) {
case ISQ_RECEIVER_EVENT:
/* 获取数据包 */
xxx_rx(dev);
break;
/* 其他类型的中断 */
}
}
static void xxx_rx(struct xxx_device *dev)
{
...
length = get_rev_len (...);
/* 分配新的套接字缓冲区 */
skb = dev_alloc_skb(length + 2);
skb_reserve(skb, 2); /* 对齐 */
skb->dev = dev;
/* 读取硬件上接收到的数据 */
insw(ioaddr + RX_FRAME_PORT, skb_put(skb, length), length >> 1);
if (length &1)
skb->data[length - 1] = inw(ioaddr + RX_FRAME_PORT);
/* 获取上层协议类型 */
skb->protocol = eth_type_trans(skb, dev);
/* 把数据包交给上层 */
netif_rx(skb);
/* 记录接收时间戳 */
dev->last_rx = jiffies;
...
}NAPI 接收数据
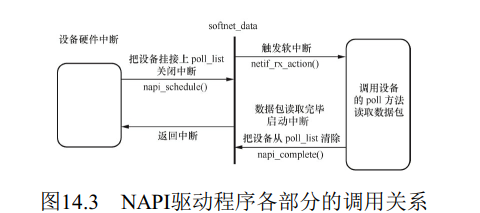
如果是NAPI兼容的设备驱动, 则可以通过poll方式接收数据包。 在这种情况下, 我们需要为该设备驱动提供作为netif_napi_add() 参数的xxx_poll() 函数。
{
int npackets = 0;
struct sk_buff *skb;
struct xxx_priv *priv = container_of(napi, struct xxx_priv, napi);
struct xxx_packet *pkt;
while (npackets < budget && priv->rx_queue) {
/* 从队列中取出数据包 */
pkt = xxx_dequeue_buf(dev);
/* 接下来的处理和中断触发的数据包接收一致 */
skb = dev_alloc_skb(pkt->datalen + 2);
...
skb_reserve(skb, 2);
memcpy(skb_put(skb, pkt->datalen), pkt->data, pkt->datalen);
skb->dev = dev;
skb->protocol = eth_type_trans(skb, dev);
/* 调用netif_receive_skb, 而不是net_rx, 将数据包交给上层协议 */
netif_receive_skb(skb);
/* 更改统计数据 */
priv->stats.rx_packets++;
priv->stats.rx_bytes += pkt->datalen;
xx_release_buffer(pkt);
npackets++;
}
if (npackets < budget) {
napi_complete(napi);
xxx_enable_rx_int (…); /* 再次启动网络设备的接收中断 */
}
return npackets;
}虽然NAPI兼容的设备驱动以xxx_poll() 方式接收数据包, 但是仍然需要首次数据包接收中断来触发这个过程。 与数据包的中断接收方式不同的是, 以轮询方式接收数据包时, 当第一次中断发生后, 中断处理程序要禁止设备的数据包接收中断并调度NAPI。
static void xxx_interrupt(int irq, void *dev_id)
{
switch (status &ISQ_EVENT_MASK) {
case ISQ_RECEIVER_EVENT:
… /* 获取数据包 */
xxx_disable_rx_int(...); /* 禁止接收中断 */
napi_schedule(&priv->napi);
break;
… /* 其他类型的中断 */
}
}
2.4.6 网络连接状态
网络适配器硬件电路可以检测出链路上是否有载波, 载波反映了网络的连接是否正常。 网络设备驱动可以通过netif_carrier_on() 和netif_carrier_off() 函数改变设备的连接状态, 如果驱动检测到连接状态发生变化, 也应该以netif_carrier_on() 和netif_carrier_off() 函数显式地通知内核。
除了netif_carrier_on() 和netif_carrier_off() 函数以外, 另一个函数netif_carrier_ok() 可用于向调用者返回链路上的载波信号是否存在。
这几个函数都接收一个net_device设备结构体指针作为参数, 原型分别为:
void netif_carrier_on(struct net_device *dev);
void netif_carrier_off(struct net_device *dev);
int netif_carrier_ok(struct net_device *dev);在网络设备驱动程序中可采取一定的手段来检测和报告链路状态, 最常见的方法是采用中断, 其次可以设置一个定时器来对链路状态进行周期性的检查。 当定时器到期之后, 在定时器处理函数中读取物理设备的相关寄存器以获得载波状态, 从而更新设备的连接状态。
//网络设备驱动用定时器周期性检查链路状态
static void xxx_timer(unsigned long data)
{
struct net_device *dev = (struct net_device*)data;
u16link;
…
if (!(dev->flags &IFF_UP))
goto set_timer;
/* 获得物理上的连接状态 */
if (link = xxx_chk_link(dev)) { //读取网络适配器硬件的相关寄存器, 以获得链路连接状态, 具体实现由硬件决定
if (!(dev->flags &IFF_RUNNING)) {
netif_carrier_on(dev); //显式地通知内核链路正常
dev->flags |= IFF_RUNNING;
printk(KERN_DEBUG "%s: link up\n", dev->name);
}
}
else
{
if (dev->flags &IFF_RUNNING) {
netif_carrier_off(dev); //显式地通知内核链路失去连接
dev->flags &= ~IFF_RUNNING;
printk(KERN_DEBUG "%s: link down\n", dev->name);
}
}
set_timer:
priv->timer.expires = jiffies + 1* Hz;
priv->timer.data = (unsigned long)dev;
priv->timer.function = &xxx_timer; /* timer handler */
add_timer(&priv->timer);
}定时器初始化
// 在网络设备驱动的打开函数中初始化定时器
static int xxx_open(struct net_device *dev)
{
struct xxx_priv *priv = netdev_priv(dev);
...
priv->timer.expires = jiffies + 3* Hz;
priv->timer.data = (unsigned long)dev;
priv->timer.function = &xxx_timer; /* 定时器处理函数 */
add_timer(&priv->timer);
...
}2.4.7 参数设置和统计数据
网络设备的驱动程序还提供一些供系统对设备的参数进行设置或读取设备相关信息的方法。
当用户调用ioctl() 函数, 并指定SIOCSIFHWADDR命令时, 意味着要设置这个设备的MAC地址。
设置网络设备的MAC地址可用如下所示的模板。
//设置网络设备的MAC地址
static int set_mac_address(struct net_device *dev, void *addr)
{
if (netif_running(dev))
return -EBUSY; /* 设备忙 */
/* 设置以太网的MAC地址 */
xxx_set_mac(dev, addr);
return 0;
}上述程序首先用netif_running() 宏判断设备是否正在运行, 如果是, 则意味着设备忙, 此时不允许设置MAC地址; 否则, 调用xxx_set_mac() 函数在网络适配器硬件内写入新的MAC地址。 这要求设备在硬件上支持MAC地址的修改, 而实际上, 许多设备并不提供修改MAC地址的接口。
当用户调用ioctl() 函数时, 若命令为SIOCSIFMAP(如在控制台中运行网络配置命令ifconfig就会引发这一调用) , 系统会调用驱动程序的set_config() 函数。系统会向set_config() 函数传递一个ifmap结构体, 该结构体主要包含用户欲设置的设备要使用的I/O地址、 中断等信息。 注意, 并不是ifmap结构体中给出的所有修改都是可以接受的。 实际上, 大多数设备并不适合包含set_config() 函数。 set_config() 函数的例子如下所示。
static int xxx_config(struct net_device *dev, struct ifmap *map)
{
if (netif_running(dev)) /* 不能设置一个正在运行状态的设备 */
return - EBUSY;
/* 假设不允许改变 I/O 地址 */
if (map->base_addr != dev->base_addr) {
printk(KERN_WARNING "xxx: Can't change I/O address\n");
return - EOPNOTSUPP;
}
/* 假设允许改变 IRQ */
if (map->irq != dev->irq)
dev->irq = map->irq;
return 0;
}驱动程序还应提供get_stats() 函数以向用户反馈设备状态和统计信息, 该函数返回的是一个net_device_stats结构体, 如下所示。
struct net_device_stats *xxx_stats(struct net_device *dev)
{
…
return &dev->stats;
}net_device_stats结构体定义在内核的include/linux/netdevice.h文件中, 它包含了比较完整的统计信息,如下所示。
struct net_device_stats
{
unsigned long rx_packets; /* 收到的数据包数 */
unsigned long tx_packets; /* 发送的数据包数 */
unsigned long rx_bytes; /* 收到的字节数 */
unsigned long tx_bytes; /* 发送的字节数 */
unsigned long rx_errors; /* 收到的错误数据包数 */
unsigned long tx_errors; /* 发生发送错误的数据包数 */
...
};net_device_stats结构体已经内嵌在与网络设备对应的net_device结构体中, 而其中统计信息的修改则应该在设备驱动的与发送和接收相关的具体函数中完成, 这些函数包括中断处理程序、 数据包发送函数、 数据包发送超时函数和数据包接收相关函数等。 我们应该在这些函数中添加相应的代码。
/* 发送超时函数 */
void xxx_tx_timeout(struct net_device *dev)
{
...
dev->stats.tx_errors++; /* 发送错误包数加1 */
...
}
/* 中断处理函数 */
static void xxx_interrupt(int irq, void *dev_id)
{
struct net_device *dev = dev_id;
switch (status &ISQ_EVENT_MASK) {
...
case ISQ_TRANSMITTER_EVENT: /
dev->stats.tx_packets++; /* 数据包发送成功, tx_packets信息加1 */
netif_wake_queue(dev); /* 通知上层协议 */
if ((status &(TX_OK | TX_LOST_CRS | TX_SQE_ERROR | TX_LATE_COL | TX_16_COL)) != TX_OK)
{ /* 读取硬件上的出错标志 */
/* 根据错误的不同情况, 对net_device_stats的不同成员加1 */
if ((status &TX_OK) == 0)
dev->stats.tx_errors++;
if (status &TX_LOST_CRS)
dev->stats.tx_carrier_errors++;
if (status &TX_SQE_ERROR)
dev->stats.tx_heartbeat_errors++;
if (status &TX_LATE_COL)
dev->stats.tx_window_errors++;
if (status &TX_16_COL)
dev->stats.tx_aborted_errors++;
}
break;
case ISQ_RX_MISS_EVENT:
dev->stats.rx_missed_errors += (status >> 6);
break;
case ISQ_TX_COL_EVENT:
dev->stats.collisions += (status >> 6);
break;
}
}2.5 网络设备与媒介层
网络设备与媒介层直接对应于实际的硬件设备。为了给设备的物理配置和寄存器操作一个更一般的描述,我们可以定义一组宏和一组访问设备内部寄存器的函数,具体的宏和函数与特定的硬件紧密相关。
3 套接字缓冲区--sk_buff
struct sk_buff {
/* These two members must be first. */
struct sk_buff *next; // 因为sk_buff结构体是双链表,所以有前驱后继。这是个指向后面的sk_buff结构体指针
struct sk_buff *prev; // 这是指向前一个sk_buff结构体指针
//老版本(2.6以前)应该还有个字段: sk_buff_head *list //即每个sk_buff结构都有个指针指向头节点
struct sock *sk; // 指向拥有此缓冲的套接字sock结构体,即:宿主传输控制模块
ktime_t tstamp; // 时间戳,表示这个skb的接收到的时间,一般是在包从驱动中往二层发送的接口函数中设置
struct net_device *dev; // 表示一个网络设备,当skb为输出/输入时,dev表示要输出/输入到的设备
unsigned long _skb_dst; // 主要用于路由子系统,保存路由有关的东西
char cb[48]; // 保存每层的控制信息,每一层的私有信息
unsigned int len, // 表示数据区的长度(tail - data)与分片结构体数据区的长度之和。其实这个len中数据区长度是个有效长度,
// 因为不删除协议头,所以只计算有效协议头和包内容。如:当在L3时,不会计算L2的协议头长度。
data_len; // 只表示分片结构体数据区的长度,所以len = (tail - data) + data_len;
__u16 mac_len, // mac报头的长度
hdr_len; // 用于clone时,表示clone的skb的头长度
// 接下来是校验相关域,这里就不详细讲了。
__u32 priority; // 优先级,主要用于QOS
kmemcheck_bitfield_begin(flags1);
__u8 local_df:1, // 是否可以本地切片的标志
cloned:1, // 为1表示该结构被克隆,或者自己是个克隆的结构体;同理被克隆时,自身skb和克隆skb的cloned都要置1
ip_summed:2,
nohdr:1, // nohdr标识payload是否被单独引用,不存在协议首部。 // 如果被引用,则决不能再修改协议首部,也不能通过skb->data来访问协议首部。</span></span>
nfctinfo:3;
__u8 pkt_type:3, // 标记帧的类型
fclone:2, // 这个成员字段是克隆时使用,表示克隆状态
ipvs_property:1,
peeked:1,
nf_trace:1;
__be16 protocol:16; // 这是包的协议类型,标识是IP包还是ARP包或者其他数据包。
kmemcheck_bitfield_end(flags1);
void (*destructor)(struct sk_buff *skb); // 这是析构函数,后期在skb内存销毁时会用到
#if defined(CONFIG_NF_CONNTRACK) || defined(CONFIG_NF_CONNTRACK_MODULE)
struct nf_conntrack *nfct;
struct sk_buff *nfct_reasm;
#endif
#ifdef CONFIG_BRIDGE_NETFILTER
struct nf_bridge_info *nf_bridge;
#endif
int iif; // 接受设备的index
#ifdef CONFIG_NET_SCHED
__u16 tc_index; /* traffic control index */
#ifdef CONFIG_NET_CLS_ACT
__u16 tc_verd; /* traffic control verdict */
#endif
#endif
kmemcheck_bitfield_begin(flags2);
__u16 queue_mapping:16;
#ifdef CONFIG_IPV6_NDISC_NODETYPE
__u8 ndisc_nodetype:2;
#endif
kmemcheck_bitfield_end(flags2);
/* 0/14 bit hole */
#ifdef CONFIG_NET_DMA
dma_cookie_t dma_cookie;
#endif
#ifdef CONFIG_NETWORK_SECMARK
__u32 secmark;
#endif
__u32 mark;
__u16 vlan_tci;
sk_buff_data_t transport_header; // 指向四层帧头结构体指针
sk_buff_data_t network_header; // 指向三层IP头结构体指针
sk_buff_data_t mac_header; // 指向二层mac头的头
/* These elements must be at the end, see alloc_skb() for details. */
sk_buff_data_t tail; // 指向数据区中实际数据结束的位置
sk_buff_data_t end; // 指向数据区中结束的位置(非实际数据区域结束位置)
unsigned char *head, // 指向数据区中开始的位置(非实际数据区域开始位置)
*data; // 指向数据区中实际数据开始的位置
unsigned int truesize; // 表示总长度,包括sk_buff自身长度和数据区以及分片结构体的数据区长度
atomic_t users; // skb被克隆引用的次数,在内存申请和克隆时会用到
}; //end sk_buff
// char cb[48];这个字段是skb信息控制块,也就是存储每层的一些协议信息,当数据包在哪一层时,存储的就是哪一层协议信息。这个字段由数据包所在层使用和维护,如果要访问本层协议信息,可以通过用一些宏来操作这个成员字段。如:#define TCP_SKB_CB(__skb) ((struct tcp_skb_cb *)&((__skb)->cb[0]))
// _u8 fclone:2;这是个克隆状态标志,到sk_buff结构内存申请时会使用到。这里提前讲下:若fclone = SKB_FCLONE_UNAVAILABLE,则表明SKB未被克隆;若fclone = SKB_FCLONE_ORIG,则表明是从skbuff_fclone_cache缓存池(这个缓存池上分配内存时,每次都分配一对skb内存)中分配的父skb,可以被克隆;若fclone = SKB_FCLONE_CLONE,则表明是在skbuff_fclone_cache分配的子SKB,从父SKB克隆得到的;
// atomic_t users;这是个引用计数,表明了有多少实体引用了这个skb。其作用就是在销毁skb结构体时,先查看下users是否为零,若不为零,则调用函数递减下引用计数users即可;当某一次销毁时,users为零才真正释放内存空间。有两个操作函数:atomic_inc()引用计数增加1;atomic_dec()引用计数减去1;
// sk_buff->data_len:只计算分片中数据的长度,即是分片结构体中page指向的数据区长度。这个在分片结构体中会再详细讲解下。
// sk_buff->len:表示当前缓冲区中数据块的大小的总长度。它包括主缓冲中(即是sk_buff结构中指针data指向)的数据区的实际长度(data-tail)和分片中的数据长度。这个长度在数据包在各层间传输时会改变,因为分片数据长度不变,从L2到L4时,则len要减去帧头大小和网络头大小;从L4到L2则相反,要加上帧头和网络头大小。所以:len = (data - tail) + data_len;
// sk_buff->truesize:这是缓冲区的总长度,包括sk_buff结构和数据部分。如果申请一个len字节的缓冲区,alloc_skb函数会把它初始化成len+sizeof(sk_buff)。当skb->len变化时,这个变量也会变化。所以:truesize = len + sizeof(sk_buff) = (data - tail) + data_len + sizeof(sk_buff);
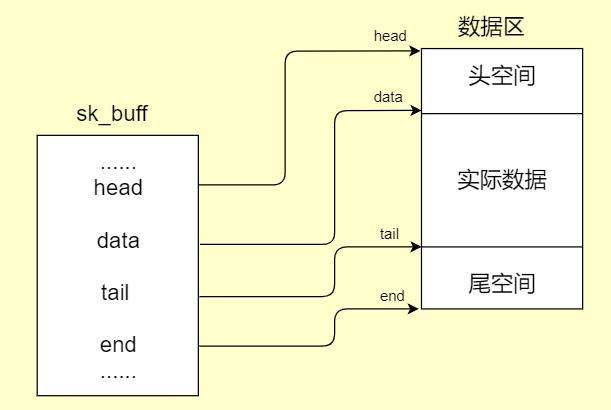
3.1 head、end与data、tail指针
head、end指针指向sk_buff缓冲区数据的头部和尾部。
data、tail指针指向实际数据的头部和尾部。
网络协议栈(TCP/IP)每一层(传输层、网络层、网络接口层不包括应用层)会在head和data之间填充协议头,在tail和end之间添加新的数据协议。
这个结构被网络的不同层(MAC或者其他二层链路协议,三层的IP,四层的TCP或UDP等)使用,并且其中的成员变量在结构从一层向另一层传递时改变。 L4(传输层)向L3(网络层)传递前会添加一个L4的头部,同样,L3向L2(网络接口层)传递前,会添加一个L3的头部。
内核中sk_buff结构体在各层协议之间传输不是用拷贝sk_buff结构体,而是通过增加协议头和移动指针来操作的。
添加头部比在不同层之间拷贝数据的效率更高。
3.1.1 数据包在各层之间传输时,data指针的变化
sk_buff_data_t transport_header; // 指向四层帧头结构体指针
sk_buff_data_t network_header; // 指向三层IP头结构体指针
sk_buff_data_t mac_header; // 指向二层mac头的头
以收包为例:
数据包开始进入第二层时,data指针开始时指向帧头。然后通过mac_header = data,就可以操作mac指针以及数据包。当二层操作完后把包往三层传送时,会调用一个函数让data指针指向三层的IP头;
当包进入第三层时,这时data指针已经指向了IP头,让network_header = data,然后操作nh指针以及数据包,当三层操作完后把包往四层传送时,同样调用一个函数把data指向四层的TCP头,transport_header = data;同理,四层也是一样处理的,只移动指针,不删除协议头。发包时就相反了,只是变成了为每一层添加协议头了。
3.2 sk_buff数据区
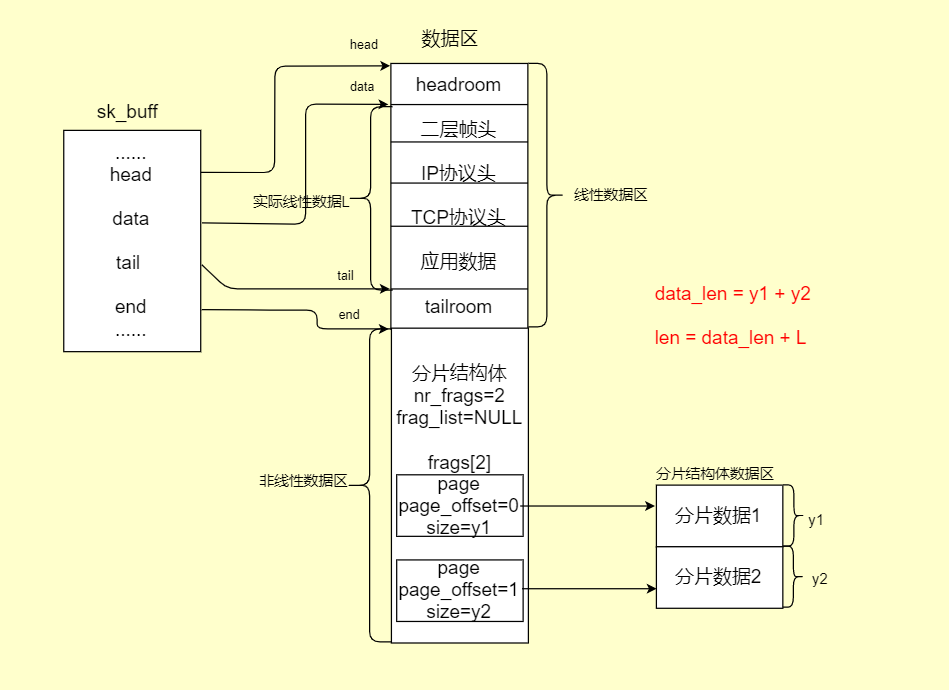
sk_buff结构体只是网络数据包中的一些配置,真正包含传输内容和传输协议的都是在sk_buff结构体中几个指针所指向的数据区中。这里先简称数据区,数据区的大小是:(skb->end - skb->head)。
对于每个数据包来说这个大小都是固定的,而且在传输过程中skb->end和skb->head所指向的地址都是不变的。这块数据区是用来存放应用层发下来的数据和各层的协议信息。
但在计算数据长度或者操作协议信息时,一般都要和实际的数据存放指针为准。实际数据指针为data和tail,data指向实际数据开始的地方,tail指向实际数据结束的地方。
head和data之间的区域成为headroom,data和tail之间的区域存放真正的数据,tail和end之间的区域成为tailroom。
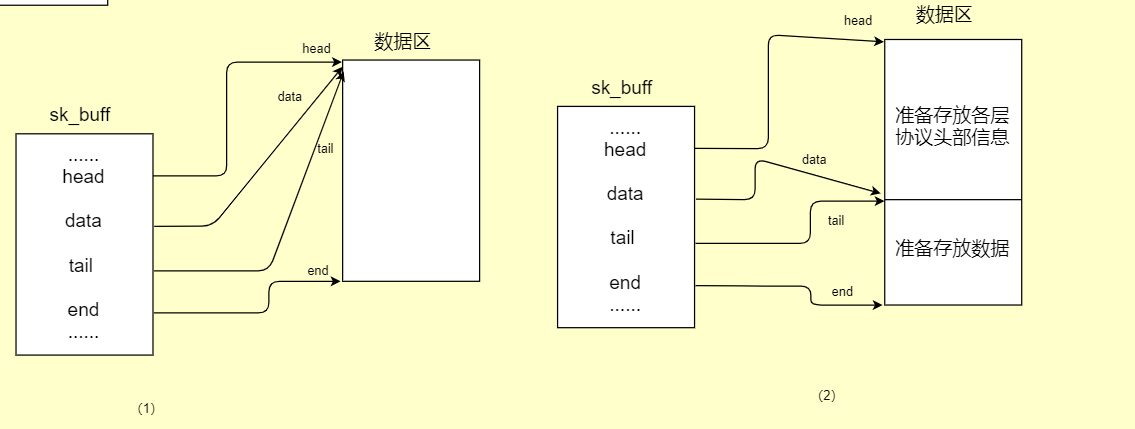
3.2.1 包的形成和数据区的变化:
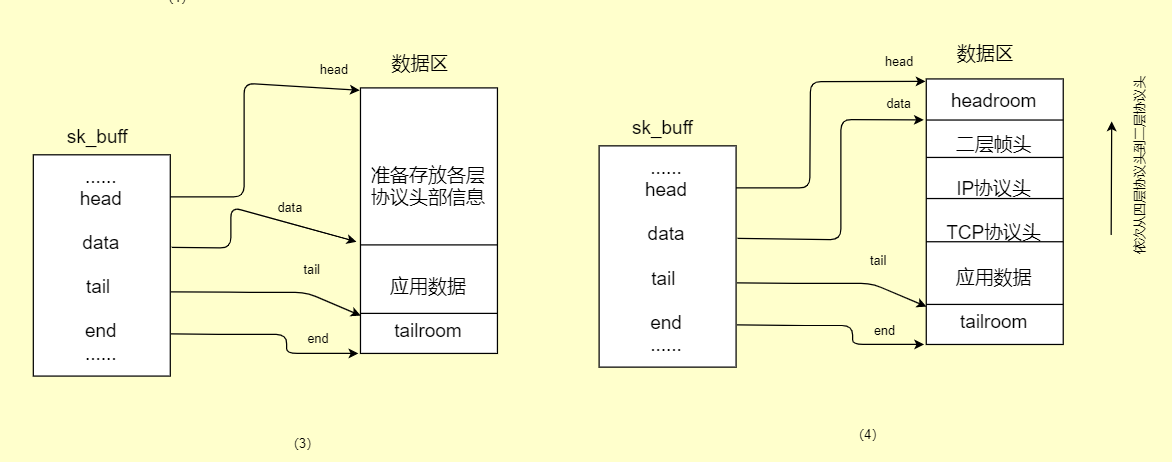
(1)sk_buff结构数据区刚被申请好,此时head指针、data指针、tail指针都是指向同一个地方。head指针和end指针指向的位置一直都不变,而对于数据的变化和协议信息的添加都是通过data指针和tail指针的改变来表现的。
(2)开始准备存储应用层下发过来的数据,通过调用函数 skb_reserve()来使data指针和tail指针同时向下移动,空出一部分空间来为后期添加协议信息。
(3) 开始存储数据了,通过调用函数skb_put()来使tail指针向下移动空出空间来添加数据,此时skb->data和skb->tail之间存放的都是数据信息,无协议信息。
(4)这时就开始调用函数skb_push()来使data指针向上移动,空出空间来添加各层协议信息。直到最后到达二层,添加完帧头然后就开始发包了。
3.3 其他相关结构体
3.3.1 sk_buff_head结构体
sk_buff结构体是双链表结构,其头结点就是sk_buff_head结构。
struct sk_buff_head {
/* These two members must be first. */
struct sk_buff*next;
struct sk_buff*prev;
__u32 qlen; //代表表中skb元数的个数
spinlock_t lock; //锁,防止并发访问
};next和prev,前驱后继指针,这里内核特意注释规定了前两个成员一定要是:next和prev指针。因为这使得sk_buff_head和sk_buff可以放到同一个链表中,尽管他们不是同一种结构体。为什么sk_buff的指针(prev和next)能够指向sk_buff_head结构?原文有句话是关键:“......在表的开端额外增加一个sk_buff_head结构作为一种哑元元素。”
3.3.2 skb_shared_info分片结构体
上文说过sk_buff的head和end都是固定的,因此data和tail之间的数据(线性数据)有可能会超过,因此引入了分片结构存放数据(非线性数据)。
这个分片结构体和sk_buff结构的数据区是一体的,所以在各种操作时都把他们两个结构看做是一个来操作。比如:为sk_buff结构的数据区申请和释放空间时,分片结构也会跟着该数据区一起分配和释放。而克隆时,sk_buff的数据区和分片结构都由分片结构中的 dataref 成员字段来标识是否被引用。
struct skb_shared_info {
atomic_t dataref;// 用于数据区的引用计数,克隆一个skb结构体时,会增加一个引用计数
unsigned short nr_frags;// 表示有多少个分片结构
unsigned short gso_size;
#ifdef CONFIG_HAS_DMA
dma_addr_t dma_head;
#endif
/* Warning: this field is not always filled in (UFO)! */
unsigned short gso_segs;
unsigned short gso_type; // 分片的类型
__be32 ip6_frag_id;
union skb_shared_tx tx_flags;
struct sk_buff *frag_list; // 这也是一种类型的分配数据
struct skb_shared_hwtstamps hwtstamps;
skb_frag_t frags[MAX_SKB_FRAGS]; // 这是个比较重要的数组,到讲分片结构数据区时会细讲
#ifdef CONFIG_HAS_DMA
dma_addr_t dma_maps[MAX_SKB_FRAGS];
#endif
/* Intermediate layers must ensure that destructor_arg
* remains valid until skb destructor */
void * destructor_arg;
};
分片结构和sk_buff的数据区连在一起,end指针的下个字节就是分片结构的开始位置。那访问分片结构时,可以直接用end指针作为这个分片结构体的开始(记得要强转成分片结构体)。
或者用内核定义好的宏去访问也可以,其本质也是返回个sk_buff的end指针。
#define skb_shinfo(SKB) ((struct skb_shared_info *)((SKB)- > end)) 3.3.3 分片结构体的数据区
skb_frag_t frags[MAX_SKB_FRAGS];
typedef struct skb_frag_struct skb_frag_t;
struct skb_frag_struct {
struct page *page; // 指向分片数据区的指针,类似于sk_buff中的data指针
__u32 page_offset; // 偏移量,表示从page指针指向的地方,偏移page_offset
__u32 size; // 数据区的长度,即:sk_buff结构中的data_len
};3.4 skb操作函数
3.4.1 分配
/* : alloc_skb
* @description : 分配套接字缓冲区和数据缓冲区
* @param – size : 数据缓冲区大小
* @param – priority : 内存分配方式(也叫优先级)GFP MASK宏,如GFP_KERNEL,GFP_ATOMIC等
* @return : sk_buff类型的指针。
*/
struct sk_buff *alloc_skb(unsigned int size, gfp_t priority)
/* : dev_alloc_skb
* @description : 分配套接字缓冲区和数据缓冲区
* @param – length : 数据缓冲区大小
* @return : sk_buff类型的指针。
*/
struct sk_buff *dev_alloc_skb(unsigned int length)[注意]
1、套接字缓冲区分配函数中,不光分配套接字缓冲区(skb_buff)还分配数据缓冲区(数据区)。
2、alloc_skb申请的数据缓冲区通常要以L1_CACHE_BYTES字节对齐(ARM以32字节对齐)。
3、dev_alloc_skb与alloc_buff的区别:前者用于设备驱动的接收中断中,因为他的内存分配方式默认为GFP_ATOMIC(原子操作)。
3.4.2 释放
void kfree_skb(struct sk_buff *skb); // 内核内部使用,我们自己建议使用一下三种
void dev_kfree_skb(struct sk_buff *skb); // 用于非中断上下文
void dev_kfree_skb_irq(struct sk_buff *skb); // 用于中断上下文
void dev_kfree_skb_any(struct sk_buff *skb); // 非中断、中断上下文都可以使用dev_kfree_skb_any():
原理是此函数先判断是否处于中断,处于中断上下文就调用__dev_kfree_skb_irq(),否则调用kfree_skb()。
3.4.3 变更/指针移动
(1)reserve:调整缓冲区的头部,预留协议头信息空间。
将data和tail指针同时向下移动len个字节,为各种协议头信息预留空间。
static inline skb_reserve(struct sk_buff *skb,int len);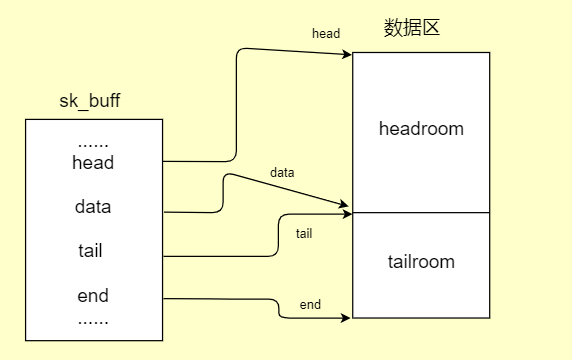
(2)put:在缓冲区尾部添加数据。
将 tail 指针下移len个字节,增加 sk_buff 的 len 值,并返回 skb->tail 的当前值。 skb_put()和__ skb_put()的区别在于前者会检测放入缓冲区的数据, 而后者不会检查。
unsigned char *skb_put(struct sk_buff *skb, unsigned int len);
unsigned char *_ _skb_push(struct sk_buff *skb, unsigned int len);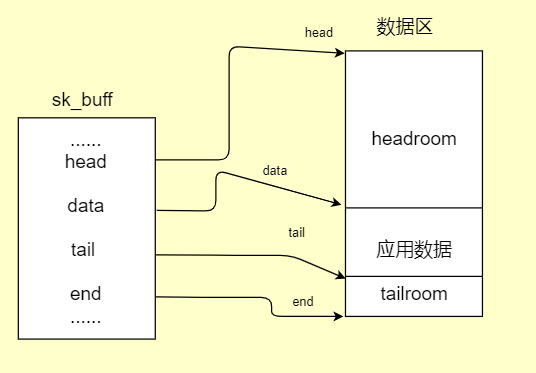
(3)push:在缓冲区开头添加数据。
将 data 指针上移len个字节。 push 操作主要用于在数据包发送时添加头部。 skb_push()与_skb_push()的区别和 skb_put()和_ _skb_put()的区别类似。
unsigned char *skb_push(struct sk_buff *skb, unsigned int len);
unsigned char *_ _skb_push(struct sk_buff *skb, unsigned int len);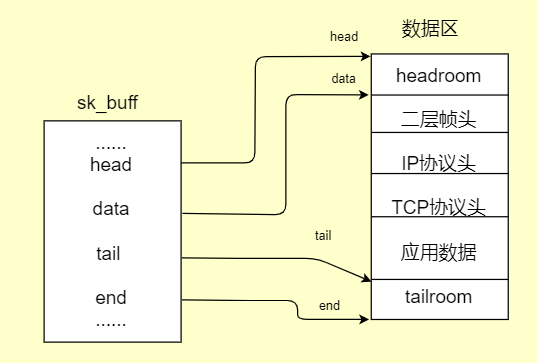
(4)poll:在缓冲区开头“移出”数据
将 data 指针下移。这个操作一般用于下层协议向上层协议移交数据包,使 data 指针指向上一层协议的协议头。
unsigned char * skb_pull(struct sk_buff *skb, unsigned int len);














 872
872











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









