







目录
结构体字节对齐意义
1、平台原因(移植原因)
不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。(例如无法使用0x00000000地址处的空间)
2、性能原因
数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
结构体字节对齐方法
1、对齐值概念
- 自身对齐值:数据类型本身的对齐值,例如char类型的自身对齐值是1,short类型是2;
- 指定对齐值:编译器或程序员指定的对齐值;
- 有效对齐值:自身对齐值和指定对齐值中较小的那个。
- 结构体有效对齐值:其最大数据成员的自身对齐值。
1.1 自身对齐值

1.2 指定对齐值
指定对齐值:无预编译指令#pragma pack(n)就看默认CPU周期。
(1) CPU周期
WIN vs qt 默认8字节对齐
Linux 32位 默认4字节对齐,64位默认8字节对齐
(2) 预编译指令:
使用伪指令#pragma pack (n),C编译器将按照n个字节对齐。n = 1 2 4 8 16
使用伪指令#pragma pack (),取消自定义字节对齐方式。
1.3 有效对齐值
自身对齐值和指定对齐值中取最小值。
1.4 结构体有效对齐值
结构体最大数据成员的自身对齐值。(包括嵌套中的结构体的最大成员)。
2、对齐规则
2.1 规则一
存放成员的起始地址必须是该成员有效对齐值的整数倍。第一个成员为结构体起始地址。
2.2 规则二
对于结构体本身,要将其补齐为结构体有效对齐值的整数倍。
3、对齐步骤(实操)
以下述结构体为例:
struct S1
{
char c1;
int c2;
short c3;
};(1)确认对齐值
无预编译指令,指定对齐值默认位linux 32位 4字节对齐。

(2)根据规则一排列成员
c1:排列在结构体初始位置 0x0000。
c2:有效对齐值为4,因此排列在4的整数倍地址上,顺序存储,c1后的地址0x0004未被占用可用。
c3:有效对齐值为2,因此排列在2的整数倍地址上,顺序存储,c2后的地址0x0008未占用可用。

(3)规矩规则二补齐结构体
结构体有效对齐值为其最大成员c2的自身对其值 4。目前未补齐前结构体占10个字节(c1:1,保留3,c2:4,c3:2),不是4的整数倍,因此补齐两个字节,12为4的整数倍。
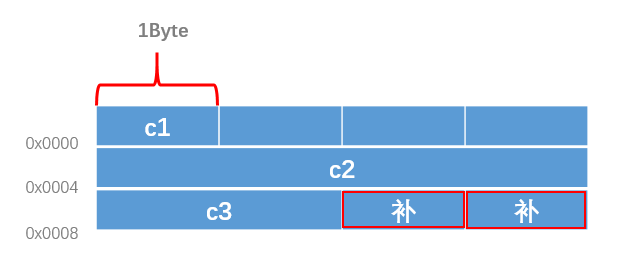
(4)计算总大小
c1: 0x0000~0x0001 占1个字节。
保留:0x0001~0X0004 占3个字节。
c2: 0x0004~0x0008 占4个字节。
c3: 0x0008~0x0010 占2个字节。
保留:0x0010~0X0012 占2个字节。
共计12字节。
3、结构体嵌套
如果一个结构体B里嵌套另一个结构体A,还是以最大成员类型的字节对齐,但是结构体A存储起点为A内部最大成员整数倍的地方。(struct B里存有struct A,A里有char,int,double等成员,那A应该从8的整数倍开始存储。),结构体A中的成员的对齐规则仍满足自身的规则 。
注意:结构体A整体所占的大小为该结构体成员内部最大元素的整数倍,不足补齐。
struct A{
int a;
double b;
short c;
}A;
struct {
char d[2];
int e;
double f;
short g;
struct A h;
short i;
}B;(1) 确认对齐值

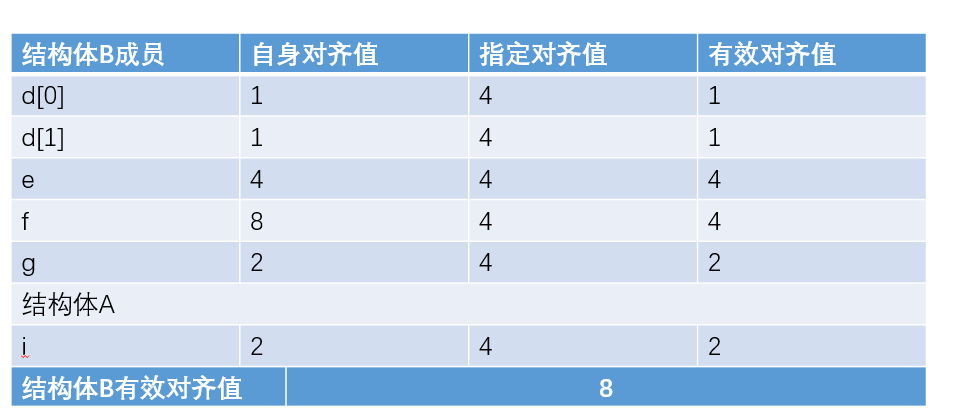
(2) 按照规则一排列结构体B中嵌套的结构体A之前的成员。

(3)之后排列嵌套结构体A。这里要注意三点:
1.结构体A存储起点为A内部最大成员整数倍的地方。
2.结构体A的其他成员排列按照规则一。
3.结构体A整体所占的大小为该结构体成员内部最大元素的整数倍,不足补齐。

(4)继续按照规则一补足结构体B剩余部分。 按照规则二补齐剩余部分。

编程应用
结构体字节对齐就是以空间换时间。
1、节省空间
编程时把结构中的变量按照类型大小从小到大声明,尽量减少中间的填补空间。
2、节省时间
以空间换取时间的效率,我们显示的进行填补空间进行对齐,比如:有一种使用空间换时间做法是显式的插入reserved成员:
struct A{
char a;
char reserved[3]; //保留,使用空间换时间
int b;
}reserved成员对我们的程序没有什么意义,它只是起到填补空间以达到字节对齐的目的,当然即使不加这个成员通常编译器也会给我们自动填补对齐,我们自己加上它只是起到显式的提醒作用.
3、隐患
在有字节对齐的结构体中使用指针强转取值时,容易发生越界访问的隐患。















 148
148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









