






官网相关内容:Downloading and processing files and images — Scrapy 2.9.0 documentation
修改setting.py
1.在文件末尾添加图片的储存的位置:
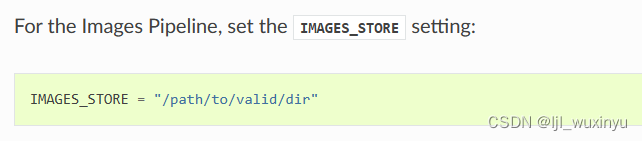
#./在当前文件下新建一个名为images的文件夹,存储图片
IMAGES_STORE = './images'2.找到并激活ltem pipeline
激活管道(在pipelines.py中的类都需要在setting.py中激活)
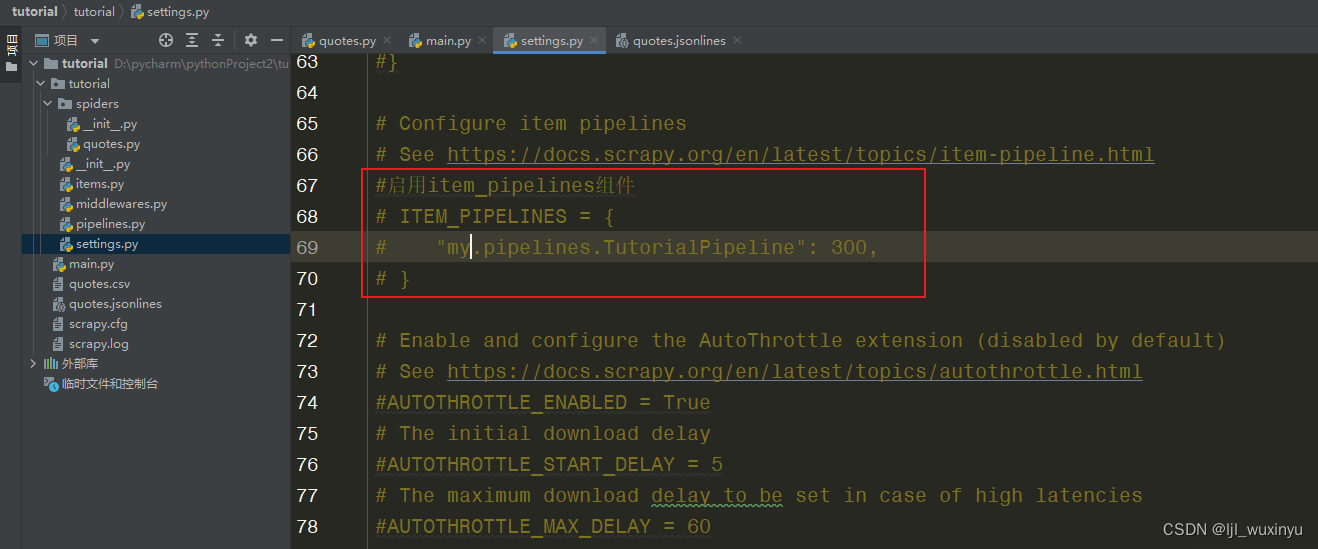
加入下载保存图片的类
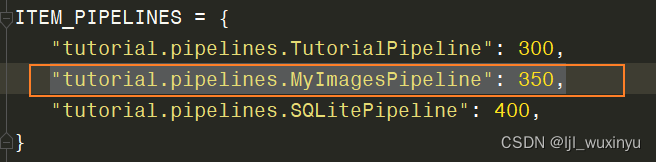
修改pipelinse.py
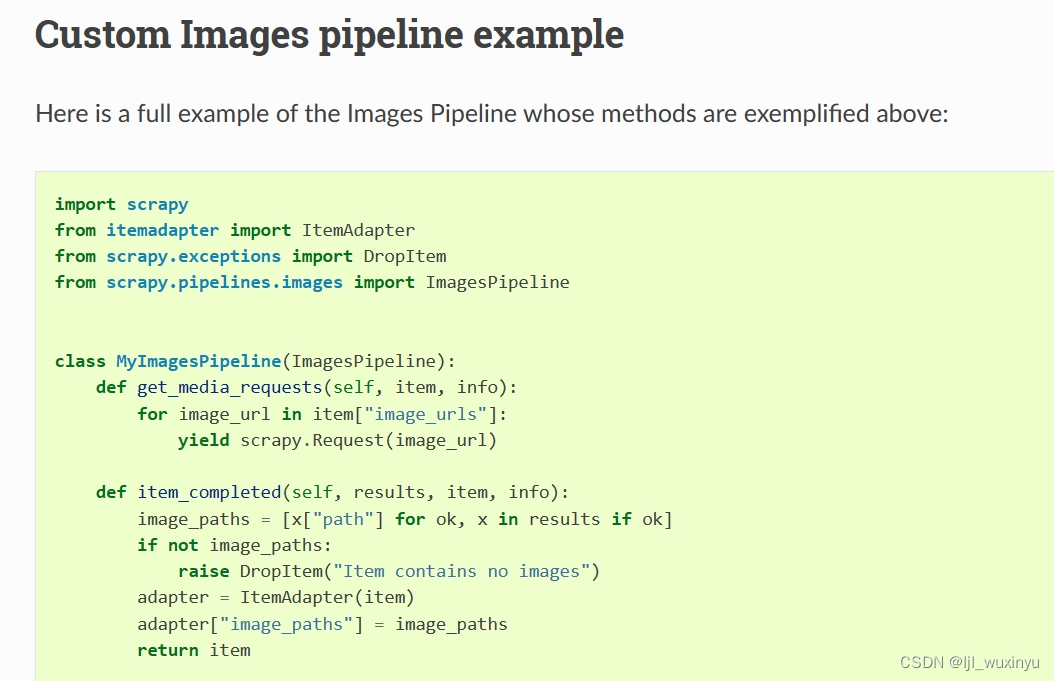
1.导入模块
2.创建一个自定义的图片下载管道类,继承自ImagesPipeline,并实现必要的方法。
-
get_media_requests(self, item, info): 该方法负责生成并返回要下载的图片的请求对象(Request)。可以通过item对象获取图片的URL,并使用yield语句返回一个或多个请求对象。 -
file_path(self, request, response=None, info=None, *, item=None): 该方法用于定义文件保存的路径和文件名。接收下载请求对象request作为参数,并返回一个字符串表示的文件路径。 -
item_completed(self, results, item, info): 该方法在图片下载完成后被调用。接收下载结果results、爬取的项目item和相关的信息对象info作为参数。可以在此方法中对下载的图片进行进一步处理或与其他字段关联。import scrapy from scrapy.pipelines.images import ImagesPipeline from scrapy.exceptions import DropItem #自定义存储图片类 class MyImagesPipeline(ImagesPipeline): #负责采集图片 def get_media_requests(self, item, info): #通过抓取item对象获取图片信息,并创建request请求对象添加队列,等待调度下载 for picture_url in item['picture']: #scrapy.request函数接受URL字符串作为参数 yield scrapy.Request('http:'+ picture_url) print(picture_url) #用于定义文件保存路径和文件名 def file_path(self, request, response=None, info=None, *, item=None): url = request.url #获取请求的url images = url.split("/") [-1] #返回列表最后一个元素 print("File path:", images) #查看生成的文件路径是否符合预期。 return images #采集完的信息 def item_completed(self, results, item, info): #先用if判断语句真假,真从results里拿取图片信息给到image_paths images= [x['path'] for ok, x in results if ok] #if判断真假,假就报错 if not images: raise DropItem("Item contains no images") #处理图片操作 item['picture'] = images return item















 2978
2978











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









